
时序数据是一种按时间顺序排列的数据,其主要特征是数据随时间变化而变化。时序数据往往具有时间依赖性、连续性、周期性、实时性、大规模性、异步性、多维性、不确定性等特点。时序数据的处理和分析需要专门的数据库管理系统,即时序数据库。
生产制造与工业自动化
能源电力与石油化工
车联网与轨道交通
航空航天
物联网传感器测量(水冷、高温、地震...)
服务器监控(CPU、内存、磁盘...)
资源消耗(能源、电力...)
医疗健康监测(心率、血氧浓度...)
网络流量分析
零售与电子商务 金融市场交易
作为一种针对时序数据高度优化的垂直型数据库,时序数据库在物联网行业有广泛的应用场景(如工业制造、能源电力、航空航天、智慧交通、设备健康、智能运维、医疗保健、零售业等),通过对海量时序数据进行分析预测,企业可以获得有价值的信息,从而做出更明智的决策,获得独特的竞争优势。
物联网大数据平台在进行时序数据库选型时,会考虑哪些性能特征呢?以下为一些常见的考量因素,供大家参考~
1. 高效的分布式系统与存储功能。物联网产生的数据量巨大,因此处理系统必须是分布式的、水平扩展的。为降低成本,一个节点的处理性能必须是高效的,需要支持数据的快速写入和快速查询。
2. 数据持续稳定写入。对于物联网系统,通常数据流量呈平稳状态,因此我们可以相对准确地估算数据写入所需的资源。然而,挑战在于查询和分析阶段,尤其是即席查询,可能对系统资源造成巨大压力。因此,系统必须确保分配足够的资源,以保障数据能够顺利写入系统而不至丢失。具体而言,这要求系统采取写优先的策略,以确保对写入操作的优先满足。
3. 实时处理的框架。对于物联网场景,需要基于采集的数据做实时预警、决策,延时要控制在秒级以内。物联网数据的实时性要求数据库具备快速的数据摄取和处理能力,以支持实时监控、预警和其他实时应用场景。
4. 实时流式计算功能。支持流式数据处理,能够对连续流入的数据进行实时处理和分析,以满足物联网环境中快速变化的数据需求。实时预警或预测已经不再简单地基于单一阈值进行,而是需要对多个设备生成的数据流进行实时聚合计算。这种计算不再仅限于单一时间点,而是基于时间窗口进行,考虑了更广泛的时间范围。
5. 快速且灵活的查询能力。时序数据库提供了专门用于时序数据分析的查询能力。它包括了经过优化的函数、运算符和索引技术,通过其处理涉及时间间隔、滑动窗口和聚合等复杂查询的能力,使用户能够迅速准确地从物联网海量数据中提取有价值的指标。
6. 持续聚合。允许用户预先计算并存储不同时间间隔的聚合数据。这个特性极大地提高了常见聚合查询的性能,例如在特定时间范围内计算平均值、总和或计数。对于需要实时分析和仪表板的物联网应用,持续聚合提供了显著的性能提升。
7. 高扩展性和高可用性。由于物联网设备数量众多,数据库应该具备高度可扩展性,能够轻松应对不断增长的设备连接和数据量;同时,由于物联网环境复杂,数据库应具备容错性和高可用性,以确保即使在设备故障或网络问题的情况下,系统仍能保持稳定运行。
8. 支持云边协同。要有一套灵活的机制将边缘计算节点的数据上传到云端,根据具体需要,可以将原始数据及加工计算后的数据,或仅符合过滤条件的数据同步到云端,而且随时可以取消,更改策略。
9. 便于私有化部署。通过私有化部署,便于掌握系统的管理、配置和访问控制,确保数据安全性并满足内部隐私和合规性要求,并适应特定业务流程和工作负载。
作为 DB-Engines 排行榜上国内排名第一的时序数据库,DolphinDB 是完全自主研发的新一代的高性能分布式时序数据库,以一站式大数据方案、快速开发、性能优异、综合使用成本低著称。DolphinDB 目前广泛应用于量化金融及工业物联网领域,接下来介绍 DolphinDB 作为工业物联网数据平台的7大优势,为大家提供数据库选型参考。
1. 一站式数据解决方案
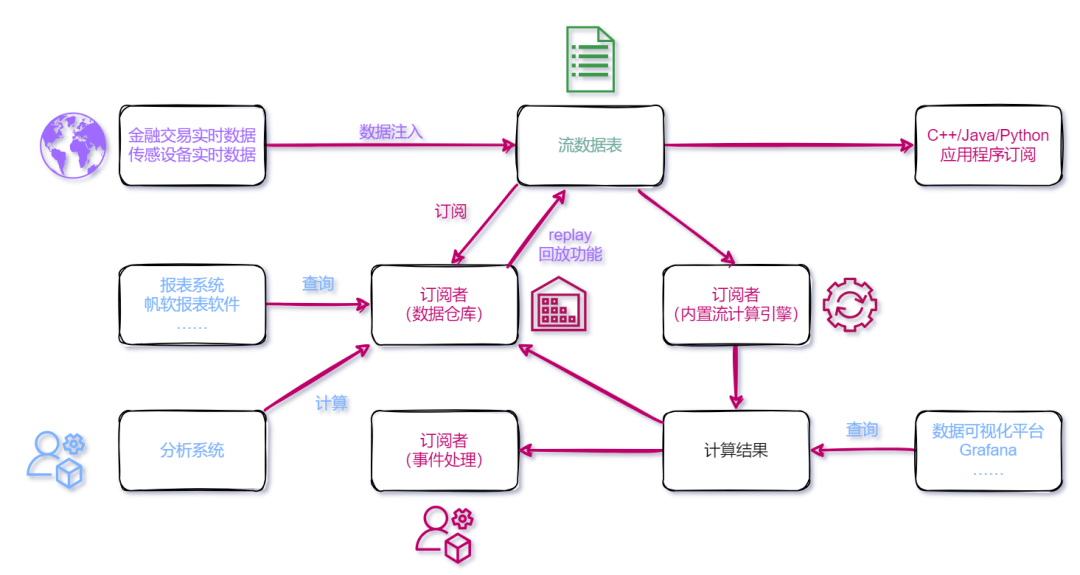
对于系统集成商或企业而言,在一套系统上进行开发和维护,无论是在开发维护还是硬件采购成本上都更为经济高效。
2. 轻量级跨平台部署
工业物联网平台的复杂性体现在多方面:从低成本的工控机(低配 PC 或嵌入式系统)到高性能的服务器或服务器集群,涵盖了边缘计算、本地平台部署以及云端平台部署。这涉及到多种操作系统,包括 Linux 和 Windows。市场上存在许多开源或商用的时序数据库,以及相关的大数据生态系统,这些组件繁多且复杂,体积庞大,对软硬件的要求也较高。尝试使用一套系统进行跨平台部署会面临巨大的挑战。
DolphinDB 是一个非常轻量级的系统,用 GNU C++开发,系统大小仅70余兆,无任何依赖,可以部署在上述任何平台上,极大节约了系统集成商的开发和维护成本。
3. 海量历史数据存储和处理
范围查询:DolphinDB 使用数据对(pair)的形式表示范围。 多维查询:可以针对不同列进行聚合,实现高维或低维的范围查询功能。 抽样查询:提供了以分区为单位的抽样查询机制,可以按照指定的比例或者数量对分区进行抽样,只需要在 where 后调用 sample 函数。 精度查询:DolphinDB 的时间精度达到纳秒,支持海量高精度历史数据存储,也支持把高精度大数据集聚合转换成低精度小数据集存储。同时,支持多种精度分组抽样及自定义分组。 插值查询:在工业领域经常会发生采集的数据缺失。DolphinDB 在查询计算时提供了4种插值方式补全数据,向前/向后取非空值填充(bfill/ffill),线性填充(lfill)和指定值填充(nullFill)。 聚合查询:DolphinDB 函数库非常丰富,支持以下聚合函数:atImax, atImin, avg, beta, contextCount, contextSum, contextSum2, count, corr, covar, derivative, difference, first, imax, last, lastNot, max, maxPositiveStreak, mean, med, min, mode, percentile, rank, stat,std,sum, sum2,var, wavg, wsum, zscore。 面板数据分组查询:DolphinDB 提供了 context by 和滑动统计函数,并对部分滑动统计函数进行了优化,最大程度地降低了重复计算。 对比查询:DolphinDB 的 pivot by 可用于数据透视,特别是同一时间不同列的指标对比。 关联查询:支持多种关联查询,包括等值连接、完全连接、交叉连接、左连接、asof join 和窗口连接。 机器学习与分布式计算:提供了 map-reduce,iterative map-reduce 等分布式计算框架,无需编译、部署,可以直接在线使用。同时,DolphinDB 内置了常用的拟合和分类算法,如线性回归、广义线性模型(GLM)、随机森林(Random Forest)、逻辑回归等。
DolphinDB 是一个完全自主研发的分布式时序数据库,从底层的分布式文件系统和存储引擎,到数据库和核心类库,再到分布式计算引擎、脚本语言,甚至外围的开发集成环境 GUI 和集群管理工具,全部自主研发,无任何外部依赖,保证了系统的安全可控性。
DolphinDB 不仅支持 x86 和 arm 指令体系,还在适配 MIPS 指令体系,以支持龙芯等国产 CPU ,在工业物联网平台上实现了软硬件同时自主可控。
欢迎大家点击 DolphinDB 官网 dolphindb.cn 或 阅读原文了解及试用
Explore More


