在大模型火之前,机器视觉,是近5年来讲AI、用AI最多,最频繁的行业。业内一些公司,也靠AI赚到了真金白银。
2023年,GPT横空出世,举世沸腾,海量资金疯狂入场大模型赛道。

但和AI纠缠了5年多的机器视觉行业,对大模型,似乎没那么热情。
行业很分散,应用很垂直,难通用。
中小玩家众多,大模型对中小企业而言,就是奢侈品:一年的利润不够买一台H100(小几百万)。
短期看,大模型对行业的影响有限;但长期看(5-10年),更聪明、更灵活、更通用的AI,将给视觉行业带来巨大的变革。

大模型的本质
www.do3think.com
传统的神经网络AI,仅参考人类大脑,构造了一个机器大脑,但学习过程,没法参考人类的学习模式,仅针对少样本或特定样本,进行学习。(主要原因,是以前无法高效的输入足够多的有效信息、数据,且运算能力也不够强大)。
近10年,随着互联网信息的海量爆发,以及硬件算力的持续增长,使高效的获得足够多的有效信息,并进行大量运算成为可能。AI科学家,参考人脑的结构和学习过程,设计并训练神经网络,并获得了不错的结果。基于这种神经网络结构和海量数据学习的AI,就是大模型。
一个婴儿,从出生到3岁,眼睛从真实世界获取的影像,约3亿张---人类大脑的学习过程,就是不断从外界摄入信息---视觉,听觉,触觉,味觉,运动感知等,不断学习,不断提高,从而成为一个“通用”的人。
Do3think
经过海量学习的人脑,其实就是一个成功的通用大模型。

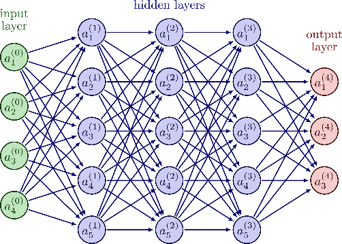
大模型,既参考人脑结构,还参考了人脑学习过程。
大模型,就像从大学毕业的学生,经过训练,具备了很多通用的技能,掌握了再学习的技巧,再进入陌生领域,只需要学习陌生领域的知识,即可成为一个合格的“打工人”。
• GPT,就是世界顶级名校培养出来的学生,最聪明,最好用,最高效。
• 国内大模型,就是国内各顶级名校培养出来的学生,在国内最聪明、最好用、最高效。
为什么人类会担心大模型诞生出“自我意识”
大模型,参考人类大脑结构和学习过程而来。
神经网络有输入层,隐藏层和输出层。其中,隐藏层有很多层,这个层,就是深度学习里的“深度“。这个隐藏层,也是最让人类担忧的地方---人类知道怎么训练他:不断调整参数和试错,从而获得期望的结果。但人类还无法完全理解隐藏层内部的运作机制。这些模型具有数千亿到上万亿的参数,其复杂性超出了人类直觉的范围。我们只知道how,不知道why。
大模型的参数,类比于人类大脑突触信号。GPT-4,据估计有1.7万亿个参数,而人类大脑有100万亿个突触,当GPT-n也有和大脑突触相同数量级的参数时,人工智能是否会产生自我意识?拭目以待。
Do3think
作为应用者
你需要知道大模型这些特点
www.do3think.com
大模型,可以看作是一种信息压缩工具。
大模型,是用数学上的高维来处理低维的信息(例如,1维的文本数据,2维的图像数据)。低维世界无法解决的海量信息间的关系、逻辑、差异、共性,在更高维度上,可被轻松的提炼、发现、总结和归纳出来。
宏观世界0维的点,在微观世界,是3维的球。
宏观世界1维的线,在微观世界,是3维的绳。
宏观世界2维的面,在微观世界,是3维的砖。
高维能发现更多的信息:提取共同的特征,发现信息间的关系和连接逻辑等。
高维对低维世界的理解,可以说是一种透过现象看本质的能力。通过高维的压缩,低维海量的信息,就被“存储”到大模型里。据估计,一些大模型的信息压缩比,约为8:1。

大模型在垂直领域的落地,是需要二次学习的,不能拿来就用。
大模型要应用到视觉行业的细分领域、垂直应用,是需要针对该领域,进行有针对性的学习和训练(喂应用数据和调参)----就像一个外行的人,进入视觉行业,也需要先学习:了解行业的特点、客户的需求、产品的功能等。
再好的大模型,没有学过对应的知识,在陌生领域,也是小白。男怕干错行,女怕嫁错郎,大模型怕没有二次学习的直接使用。
与传统的,也需要样本训练的AI相比,大模型有什么优势和不同?简单说来,就是大模型比传统AI,更高、更快、更强、更灵活。
同样的应用:
• 传统的AI,需要更多的样本训练,大模型需要较少的样本,甚至零样本(基于大模型是否已具备该应用所需的全部能力)。
• 传统的AI,训练和部署周期常需要几个月;大模型的训练和部署,可以更快,几周,甚至几天。
• 传统的AI,泛化能力较弱,当遇到与样本差异较大的数据时,处理结果不是很理想;而大模型的泛化能力较强,对与样本差异较大的数据,处理准确性更高。

针对细分领域、垂直应用,大模型可以小型化、精简化。
越通用的大模型,其训练和使用所需要的资源,也越多。对于一个垂直应用而言,把一个训练好的大模型,不做裁剪拿来就用,会导致超高的成本、效用也很低。
幸好,一个训练好的大模型,是可以裁剪的。这就是目前行业里所说的:大模型小型化,或,小的大模型。
以驾驶和做菜技能为例来说明。
驾驶和做菜,二者都需要具备对手的控制能力,但驾驶,不需要知道什么是鸡蛋,什么是西红柿;做菜,不需要识别红绿灯。
• 对手的控制,是驾驶和做菜应用都需要的能力,2个应用上都保留。
• 识别鸡蛋和西红柿的能力,在做菜应用上保留,在驾驶应用上删除。
• 识别红绿灯的能力,在驾驶应用上保留,在做菜应用上删除。
Do3think
越细分、越垂直的应用,其大模型越能小型化,低成本化。目前,业界已经有嵌入式的小的大模型方案面世,就是针对机器视觉这类碎片、垂直类应用。
算力、模型,都可以服务形式提供,算力as a Service, 模型as a Service。
对中小企业而言,成本,是大模型能否用起来的核心考量因素。中小企业不需要自己训练通用的大模型,但需要基于行业数据,在某类大模型上,训练行业专精大(小)模型。
基于垂直应用复杂度的不同,可以有多种模式选择:
1、 租用政府或大型事业单位提供的算力和模型平台,进行专用大模型的训练。
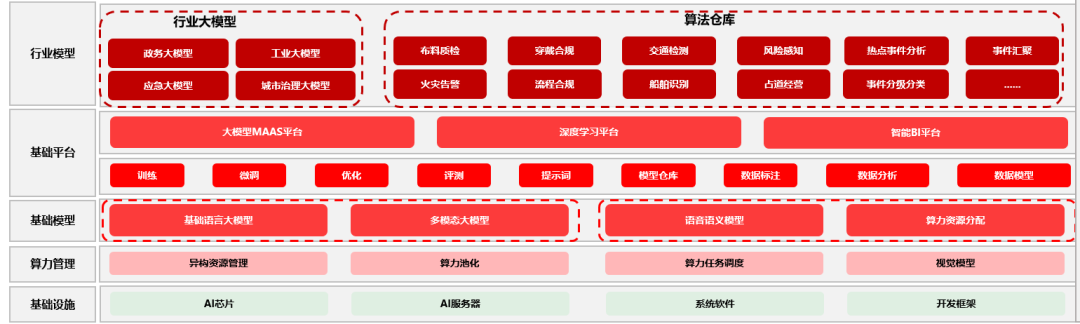
大模型基础设施规划
已经有多个地市政府在建设这类可对外出租硬件、算力和大模型的平台。要不了多久,为企业提供大模型租用服务,或将成为地方政府招商引资的标配。
2、 与中大型AI公司合作,训练模型。对于一些大行业,这类公司会先基于行业训练一个行业通用的大模型。中小公司,可在这类行业大模型上,裁剪训练自己的场景化的小模型,以确保模型应用的最优化。
3、 自建算力平台,训练模型。应用越细分,需要的模型越简单,所需的算力也就越少。在一些很小的行业,或很细分的领域,这种模式是可行的。
大模型能升级吗?
就目前的大模型进展而言,大模型是不能升级的,只能替换。
大模型,是基于海量数据训练,对神经网络的“神秘”改造而来。AI科学家都还弄不清大模型的机制,何谈升级呢?
对于垂直应用而言,基于1.0版本大模型训练出来的专用模型1.1,可以在1.1基础上继续训练、调参,获得更优的1.2, 1.3等版本。但如果要将可能更好的2.0版本大模型用于垂直应用上,以达到更好的效果,则需要在2.0版本大模型上,重新训练一遍,获得专用模型2.1、2.2。
不同代际大模型,不能升级,不能OTA,只能替换和重新训练,是大模型落地所必须面对的一个挑战。
机器人行业那么卷,具身智能会让机器人行业焕发第二春吗?
什么是具身智能?
像人一样能与环境交互感知,自主规划、决策、行动、执行能力的机器人,可称之为“具身智能机器人”。它的实现包含了人工智能领域内诸多的技术,例如计算机视觉、自然语言处理、机器人学等。用通俗点的话来说,具身智能,就是通用机器人。
Do3think
机器人和机器视觉,是2个交叉的行业,视觉系统为机器人提供基础的感知,机器人大脑基于感知,控制机器人完成各类动作。大模型出现以前的机器人方向,重点放在了运动控制,波士顿动力的机器狗,是其极致代表。但因为对外部世界的感知和处理不够智能和灵活,机器狗的商用落地进展缓慢。机器人行业,主要还是聚焦在各个细分领域,让机器人执行比较单一的任务和动作,可快速商用落地。

大模型出来后,业界看到了机器人具备“通用智能”的可能。机器人拥有一个聪明的大脑,能够听懂人类语言,然后,分解任务,规划子任务,移动中识别物体,与环境交互,最终完成相应任务。国外,有机构用三个大模型(视觉导航模型、大型语言模型、视觉语言模型)教会了机器人在不看地图的情况下按照语言指令到达目的地。
Tesla和Agility的人形机器人,都是具身智能的探索方向---在限定场景下的具身智能,已经有较大希望商用落地。

北京机器视觉大会,约起来
www.do3think.com
工业AI、工业大模型、视觉大模型、具身智能等概念,是2024年机器视觉行业的热门话题。5月21日-5月22日,北京机器视觉大会将在国家会议中心4,5号馆进行。众多大模型厂家、行业AI厂家、头部硬件厂家均有参加。度申也将在大会上做相关主题分享,欢迎聆听,并光临度申展位,一起探讨交流行业大势。
展会位置图
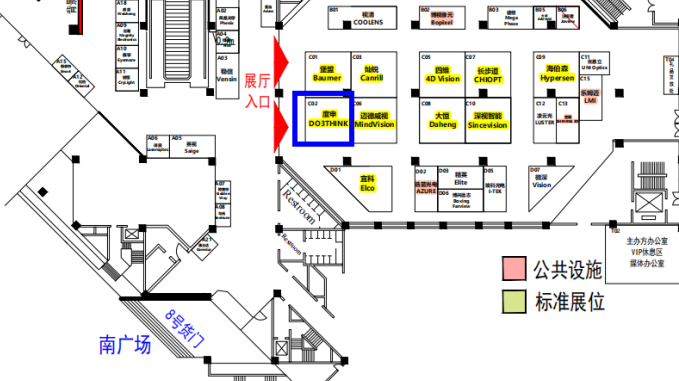

度申展位图

为全球工业智能制造
提供视觉灵魂产品和服务
— 度申科技 —