



зӮ№еҮ»дёҠж–№и“қиүІеӯ—дҪ“е…іжіЁжҲ‘们

ж ҮйўҳпјҡNovel Joint Transfer Network for Unsupervised Bearing Fault Diagnosis From Simulation Domain to Experimental Domain
жңҹеҲҠпјҡIEEE-ASME TRANSACTIONS ON MECHATRONICSВ В В В пјҲ2022пјү
и§ЈеҶізҡ„й—®йўҳпјҡиҝҒ移иҜҠж–ӯеңәжҷҜд»…йҷҗдәҺе®һйӘҢеҹҹпјҢи·Ёеҹҹиҫ№зјҳеҲҶеёғе’ҢжқЎд»¶еҲҶеёғйҡҫд»ҘеҗҢж—¶еҜ№йҪҗпјҢжҜҸдёӘжәҗеҹҹж ·жң¬еңЁеҹҹиҮӘйҖӮеә”иҝҮзЁӢдёӯиў«еҲҶй…ҚеҗҢзӯүйҮҚиҰҒгҖӮ
и§ЈеҶізҡ„ж–№жі•пјҡNJTNпјҲдёҖз§Қж–°зҡ„д»Һд»ҝзңҹеҹҹеҲ°е®һйӘҢеҹҹзҡ„ж— зӣ‘зқЈиҪҙжүҝж•…йҡңиҜҠж–ӯиҒ”еҗҲдј иҫ“зҪ‘з»ңпјү
еҲӣж–°пјҡ
в‘ жҺўзҙўж•°жҚ®-зү©зҗҶиҖҰеҗҲй©ұеҠЁж•…йҡңиҜҠж–ӯж–№ејҸпјҲеҲ©з”Ёдё°еҜҢж•…йҡңж ҮзӯҫдҝЎжҒҜзҡ„д»ҝзңҹж•°жҚ®жһ„е»әжәҗеҹҹпјҢеҮҸе°‘еҜ№иҜ•йӘҢеҸ°зҡ„дҫқиө–пјҢж»Ўи¶ідёҚеҗҢе·ҘеҶөдёӢж•…йҡңж•°жҚ®иҰҒжұӮгҖӮпјү
в‘Ўи®ҫи®ЎJMMDпјҲеөҢе…ҘиҒ”еҗҲMMDпјүзҡ„ж”№иҝӣжҚҹеӨұеҮҪж•°пјҢе®һзҺ°ж— зӣ‘зқЈеңәжҷҜдёӢиҫ№зјҳеҲҶеёғе’ҢжқЎд»¶еҲҶеёғеҗҢж—¶еҜ№йҪҗгҖӮ
в‘ўеҹәдәҺеҹҹзӣёдјјеәҰејҖеҸ‘дәҶдёҖз§ҚжқғйҮҚеҲҶй…ҚжңәеҲ¶пјҢжҠ‘еҲ¶иҙҹиҝҒ移гҖӮ
01В еҲӣж–°1зҡ„е…·дҪ“еҶ…е®№
йҮҮз”ЁйӣҶдёӯиҙЁйҮҸжі•е»әз«ӢиҪ¬еӯҗ-иҪҙжүҝзі»з»ҹд»ҝзңҹжЁЎеһӢжқҘз”ҹжҲҗжҢҜеҠЁе“Қеә”д»Ҙжһ„е»әжәҗеҹҹ
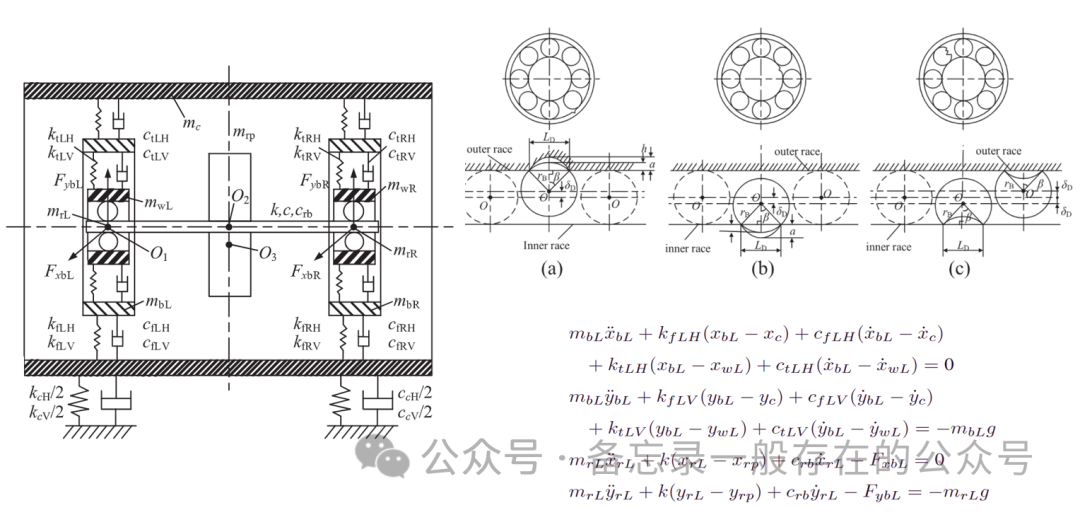
йҮҮз”ЁйӣҶдёӯеҸӮж•°жі•жқҘе»әз«ӢиҪ¬еӯҗ-йҪҝиҪ®зҡ„дёӨдёӘзі»з»ҹзҡ„д»ҝзңҹжЁЎеһӢжқҘз”ҹжҲҗйңҮеҠЁе“Қеә”жқҘжһ„е»әжәҗеҹҹпјҢеҫ—еҲ°дёүз§ҚдёҚеҗҢзҡ„зҠ¶жҖҒпјҡеӨ–еңҲгҖҒеҶ…еңҲгҖҒж»ҡеӯҗд»ҘеҸҠжӯЈеёёзҡ„гҖӮ
пјҲе…¬ејҸжҳҜе»әз«Ӣд»ҝзңҹжЁЎеһӢзҡ„иҝҗеҠЁж–№зЁӢпјү
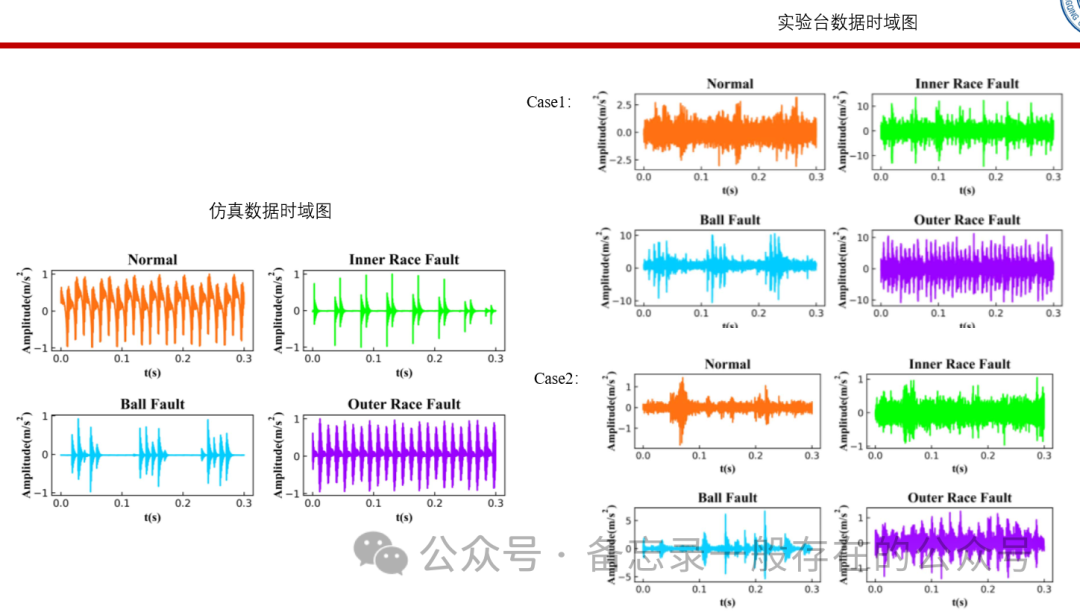
еҫ—еҲ°зҡ„д»ҝзңҹж•°жҚ®ж—¶еҹҹеӣҫеҰӮдёӢпјҢеҸҜд»ҘзңӢеҲ°д»ҝзңҹж•°жҚ®дёҺиҜ•йӘҢеҸ°еҫ—еҲ°зҡ„ж•°жҚ®зҡ„еҪўжҖҒжҳҜйқһеёёйқһеёёдёҚдёҖиҮҙзҡ„пјҢдҪҶжҳҜз»ҶзңӢзҡ„иҜқ他们жҳҜжңүз•Ҙеҫ®зӣёдјјд№ӢеӨ„гҖӮжҜ”еҰӮд»ҘеҶ…еңҲдёәдҫӢпјҢдёҖиӮЎдёҖиӮЎзҡ„и·ҹд»ҝзңҹзҡ„дёҖиӮЎдёҖиӮЎзҡ„еңЁеӨ§дҪ“дёҠзҡ„иҪ®е»“дёҠжҳҜжңүдёҖе®ҡзӣёдјјеәҰзҡ„пјҢеҗҢж ·пјҢиҝҷдёӘж»ҡеӯҗд№ҹжҳҜдёҖж ·зҡ„пјҢдёҖиӮЎдёҖиӮЎдёҖиӮЎгҖӮиҝҷе°ұжҳҜиҜҙиҝҷдёӘзү©зҗҶзҡ„жЁЎеһӢзЎ®е®һжҳҜи•ҙеҗ«дәҶе®һйӘҢж•°жҚ®дёӯзҡ„дёҖдәӣзү№еҫҒдҝЎжҒҜзҡ„пјҢиҜҙжҳҺ他们зҡ„йўҶеҹҹйҖӮй…ҚжҳҜжңүдёҖе®ҡйҒ“зҗҶзҡ„гҖӮеҪ“然пјҢеңЁиҝҷйҮҢиҫ№пјҢжҲ‘们еҸҜд»ҘиҖғиҷ‘иҝӣдёҖжӯҘзҡ„и°ғеҸӮгҖҒеҠ жӣҙй«ҳзҡ„зәҰжқҹгҖҒеҠ еҷӘеЈ°зӯүпјҢ让他们зҡ„зӣёдјјеәҰжӣҙжҺҘиҝ‘пјҢжӣҙиҙҙеҗҲе®һжөӢзҺҜеўғгҖӮгҖҗCase1е’ҢCase2еҲҶеҲ«жҳҜи®әж–ҮдёӯеҒҡзҡ„дёӨдёӘе®һдҫӢзҡ„е®һйӘҢж•°жҚ®еӣҫгҖ‘
02В еҲӣж–°2зҡ„е…·дҪ“еҶ…е®№
и®әж–Үеә”з”Ёзҡ„з»Ҹе…ёзҪ‘з»ңжҳҜDANNпјҢеҰӮдёӢпјҡ

е…¶дёӯпјҡ
зү№еҫҒжҸҗеҸ–еҷЁGfпјҡз”ЁдәҺеӯҰд№ еҹҹдёҚеҸҳе’ҢеҲӨеҲ«зү№еҫҒиЎЁзӨәпјӣеҲҶзұ»еҷЁGy:иҙҹиҙЈеҲҶзұ»пјӣеҹҹйүҙеҲ«еҷЁGd:еҢәеҲҶGfеҸҳжҚўзҡ„зү№еҫҒиЎЁзӨәжҳҜжқҘиҮӘжәҗеҹҹиҝҳжҳҜзӣ®ж ҮеҹҹгҖӮе…¶дёӯGfе’ҢGdз”ұжўҜеәҰеҸҚиҪ¬еұӮиҝһжҺҘпјҲжўҜеәҰеҸҚиҪ¬еұӮзҡ„дҪңз”ЁжҳҜеңЁдёҚеҗҢеҲҶеёғзҡ„жәҗеҹҹе’Ңзӣ®ж Үеҹҹд№Ӣй—ҙиҝӣиЎҢйўҶеҹҹеҜ№йҪҗгҖӮйҖҡиҝҮжўҜеәҰеҸҚиҪ¬еұӮпјҢжәҗеҹҹзү№еҫҒжҸҗеҸ–еҷЁеӯҰд№ еҲ°зҡ„зү№еҫҒеҸҜд»ҘеңЁзӣ®ж ҮеҹҹдёҠеҫ—еҲ°жӣҙеҘҪзҡ„жіӣеҢ–пјҢд»ҺиҖҢжҸҗй«ҳж·ұеәҰеӯҰд№ жЁЎеһӢеңЁи·Ёеҹҹж•…йҡңиҜҠж–ӯд»»еҠЎдёӯзҡ„жҖ§иғҪгҖӮпјү
ОҳfпјҢОёyпјҢОёdеҲҶеҲ«жҳҜ他们зҡ„еҸӮж•°пјҢз”ұдәҺжәҗеҹҹиҫ“иҝӣеҺ»зҡ„еӣҫзүҮжҲ–иҖ…дҝЎеҸ·жңүlabelпјҢеӣ жӯӨеҸҜд»Ҙз®—еҮә他们зҡ„LossгҖӮ
жӯЈеҲҷеҢ–зі»ж•°зҡ„дҪңз”Ёпјҡ
1.е№іиЎЎжҚҹеӨұеҮҪж•°пјҡжӯЈеҲҷеҢ–зі»ж•°еҸҜд»Ҙе№іиЎЎзұ»еҲ«дәӨеҸүзҶөжҚҹеӨұпјҲLyпјүе’ҢеҹҹеҲӨеҲ«дәӨеҸүзҶөжҚҹеӨұпјҲLdпјүпјҢд»ҺиҖҢеңЁзҪ‘з»ңи®ӯз»ғиҝҮзЁӢдёӯе®һзҺ°еҜ№дёӨз§ҚжҚҹеӨұзҡ„жңүж•ҲжқғиЎЎгҖӮ
2.и®ӯз»ғзЁіе®ҡжҖ§пјҡжӯЈеҲҷеҢ–зі»ж•°жңүеҠ©дәҺжҺ§еҲ¶жЁЎеһӢеӨҚжқӮеәҰпјҢйҳІжӯўиҝҮжӢҹеҗҲпјҢд»ҺиҖҢжҸҗй«ҳжЁЎеһӢзҡ„жіӣеҢ–иғҪеҠӣе’Ңи®ӯз»ғзЁіе®ҡжҖ§гҖӮ
3.еҹҹйҖӮеә”иғҪеҠӣпјҡжӯЈеҲҷеҢ–зі»ж•°еҸҜд»Ҙи°ғж•ҙеҹҹеҲӨеҲ«еҷЁпјҲGdпјүзҡ„еӯҰд№ йҖҹзҺҮпјҢдҪҝе…¶жӣҙеҝ«ең°йҖӮеә”жәҗеҹҹе’Ңзӣ®ж Үеҹҹд№Ӣй—ҙзҡ„еҲҶеёғе·®ејӮпјҢд»ҺиҖҢжӣҙеҘҪең°иҝӣиЎҢж— зӣ‘зқЈи·Ёеҹҹж•…йҡңиҜҠж–ӯгҖӮ
KsпјҡеҒҘеә·зҠ¶жҖҒзҡ„ж•°йҮҸпјӣGykпјҲВ·пјүпјҡиҫ“еҮәзҡ„第kдёӘе…ғзҙ пјӣI[В·]пјҡжҢҮзӨәеҮҪж•°гҖӮ
еөҢе…ҘJMMDзҡ„ж”№иҝӣжҚҹеӨұеҮҪж•°зҡ„и®ҫи®ЎиҝҮзЁӢ

е°Ҫз®Ўе…¬ејҸпјҲ3йӮЈйҮҢпјүжҚ•иҺ·дәҶиҒ”еҗҲеҲҶеёғВ PsВ е’ҢВ PtВ дёӯдёҚеҗҢеҸҳйҮҸд№Ӣй—ҙзҡ„дәӨдә’пјҢ并жҳҫејҸи®Ўз®—жәҗеҹҹе’Ңзӣ®ж Үеҹҹд№Ӣй—ҙзҡ„иҒ”еҗҲеҲҶеёғе·®ејӮпјҢдҪҶйҖҡеёёд»Қ然①дёҚи¶ід»ҘеҮҶзЎ®иЎЁеҫҒеҠЁжҖҒеҸҳеҢ–зҡ„ж•°жҚ®еҲҶеёғгҖӮиҖҢDANNеӯҰд№ зҡ„е·®ејӮжҳҜдёҖдёӘйҡҗејҸи·қзҰ»пјҢеҸҜд»ҘеңЁж•°жҚ®дёӯеҠЁжҖҒеӯҰд№ пјҢжүҖд»Ҙе°ұе°ҶиҝҷдёӘе…¬ејҸеөҢе…ҘеҲ°DANNзҡ„е…¬е…ұжҚҹеӨұеҮҪж•°дёӯгҖӮв‘ЎJMMDеҜ№йҪҗжәҗеҹҹе’Ңзӣ®ж Үеҹҹзҡ„иҒ”еҗҲеҲҶеёғпјҢDANNеҮҸе°‘иҫ№зјҳеҲҶеёғе·®ејӮпјҢиҝҷдёӨдёӘеҸҜд»ҘеҗҢж—¶её®еҠ©еңЁж— зӣ‘зқЈеңәжҷҜдёӯи°ғж•ҙ他们зҡ„жқЎд»¶еҲҶеёғпјҢе…ӢжңҚдәҶеҚ•зӢ¬иҫ№зјҳеҲҶеёғеҜ№йҪҗзҡ„еұҖйҷҗжҖ§гҖӮ
и®әж–ҮжҸҗеҮәзҡ„жЁЎеһӢеҰӮдёӢпјҡ

д»ҝзңҹжөҒиө°дәҶдёҖиӮЎпјҢе®һйӘҢжөҒиө°дәҶдёҖиӮЎгҖӮ然еҗҺеңЁзү№еҫҒйҖӮй…ҚеҒҡдәҶдҝЎжҒҜдәӨдә’гҖӮиҝҷе’ҢзҺ°еңЁеҸ‘иЎЁзҡ„еӨ§йҮҸи®әж–ҮжҳҜйқһеёёзӣёдјјзҡ„пјҢж— йқһеҺҹжқҘе°ұжҳҜд»Һе®һйӘҢ1еҲ°е®һйӘҢ2пјҢзҺ°еңЁжҳҜд»Һд»ҝзңҹеҲ°дәҶе®һйӘҢгҖӮ
03В еҲӣж–°3зҡ„е…·дҪ“еҶ…е®№
жәҗеҹҹж ·жң¬жқғйҮҚеҲҶй…ҚжңәеҲ¶пјҡ

жҚҹеӨұзҡ„ж”№иҝӣйқһеёёжңүеҝ…иҰҒпјҡи®Ўз®—ејӮеёёж ·жң¬е’ҢжӯЈеёёж ·жң¬жҚҹеӨұд№Ӣй—ҙзҡ„еӨ§е°ҸпјҢе°ҶжҚҹеӨұеҫҖе°Ҹзҡ„ж–№еҗ‘дјҳеҢ–гҖӮ
жқғйҮҚеҲҶй…ҚжңәеҲ¶зҡ„дҪңз”ЁжҳҜдёәжәҗеҹҹж ·жң¬еҲҶй…ҚдёҚеҗҢзҡ„жқғйҮҚпјҢд»ҘжҠ‘еҲ¶иҙҹиҝҒ移并жҸҗй«ҳиҜҠж–ӯеҮҶзЎ®жҖ§гҖӮиҝҷз§ҚжңәеҲ¶йҖҡиҝҮжөӢйҮҸжәҗеҹҹж ·жң¬дёҺзӣ®ж Үеҹҹж ·жң¬д№Ӣй—ҙзҡ„зӣёдјјжҖ§жқҘиҮӘйҖӮеә”ең°дёәжҜҸдёӘжәҗеҹҹж ·жң¬еҲҶй…Қзү№е®ҡжқғйҮҚгҖӮ
е®һйӘҢеҸҠе…¶йғЁеҲҶз»“жһңпјҲaccпјүеұ•зӨәеҲҶжһҗ:

е®һйӘҢз»“жһңдёҚеҘҪпјҲжҢҮзҡ„жҳҜиҝҷдәӣж–№жі•йғҪжңӘи¶…иҝҮ90%пјүзҡ„еҸҜиғҪеҺҹеӣ пјҡд»ҝзңҹж•°жҚ®дёҺе®һйӘҢж•°жҚ®зӣёе·®еӨ§гҖӮгҖҗи§ЈеҶіеҠһжі•еүҚйқўд№ҹжҸҗеҲ°иҝҮдәҶпјҢеҸҜд»Ҙз»ҷд»ҝзңҹзҡ„ж•°жҚ®еҠ зәҰжқҹпјҢжҜ”еҰӮеҠ еҷӘеЈ°гҖҒиҝӣдёҖжӯҘзҡ„и°ғеҸӮзӯүпјҢдё»иҰҒе°ұжҳҜеҜ№иҫ“е…Ҙзҡ„жәҗеҹҹеҒҡдёҖдәӣж•°жҚ®йў„еӨ„зҗҶпјҢи®©е®ғжӣҙжҺҘиҝ‘дәҺе®һйӘҢж•°жҚ®гҖ‘
1пјҡи®әж–ҮжҸҗеҮәзҡ„В 2пјҡж ҮеҮҶеҚ·з§ҜзҘһз»ҸзҪ‘з»ңпјӣ3пјҡDANNпјӣ4пјҡж·ұеәҰйҖӮеә”зҪ‘з»ңпјӣ5пјҡиҒ”еҗҲйҖӮеә”зҪ‘з»ңпјӣ6пјҡCORALпјӣ7пјҡеөҢе…ҘJMMD+дёәжәҗеҹҹеҲҶй…Қзҡ„жқғйҮҚзҡ„жҚҹеӨұ+DANNзҡ„жҚҹеӨұпјӣпјҳпјҡд»…дҪҝз”ЁжқғйҮҚеҲҶй…ҚжңәеҲ¶гҖӮ
жңӘжқҘзҡ„еұ•жңӣпјҡ
1гҖҒиҖғиҷ‘еҲ°жәҗеҹҹе’Ңзӣ®ж Үеҹҹж ҮзӯҫйӣҶеңЁе®һйҷ…еә”з”Ёдёӯйҡҫд»ҘдҝқжҢҒдёҖиҮҙпјҢеҸҜд»ҘжҺўзҙўеҰӮдҪ•еңЁж ҮзӯҫдёҚдёҖиҮҙзҡ„еңәжҷҜдёӯе®ҢжҲҗдј иҫ“ж•…йҡңиҜҠж–ӯд»»еҠЎпјӣ
2гҖҒеҚ•дёӘжәҗеҹҹдёҚи¶ід»Ҙи®©еҲҶзұ»еҷЁеӯҰд№ жңүе…іж•…йҡңзү№еҫҒзҡ„и¶іеӨҹдҝЎжҒҜпјҢеҸҜд»Ҙз ”з©¶еӨҡдёӘжәҗеҹҹзҡ„ж•…йҡңиҜҠж–ӯзҹҘиҜҶиҪ¬з§»еҲ°зӣ®ж ҮеҹҹгҖӮ
иӢҘеҜ№еҺҹж–Үж„ҹе…ҙи¶Је»әи®®з»ҶиҜ»~
еҰӮжңүйңҖиҰҒпјҢи®әж–ҮжұҮжҠҘзҡ„pptеҸҜеҗҺеҸ°иҒ”зі»иҺ·еҸ–гҖӮ
еҸҰпјҡиҜҘж–Үиө„ж–ҷжәҗиҮӘзҪ‘з»ңпјҢд»…з”ЁеӯҰжңҜеҲҶдә«пјҢдёҚеҒҡе•Ҷдёҡз”ЁйҖ”пјҢиӢҘжңүдҫөжқғпјҢеҗҺеҸ°иҒ”зі»иҝӣиЎҢеҲ йҷӨгҖӮ

01
иө„ж–ҷеҲҶдә«
зҢ«зӢ—ж•°жҚ®йӣҶпјҲи®ӯз»ғйӣҶжөӢиҜ•йӣҶеҲ’еҲҶеҘҪзҡ„пјҢж Үзӯҫexcelд№ҹжңүпјү
й“ҫжҺҘпјҡhttps://pan.baidu.com/s/18eVSQZuSY_3SqL9GMnTRIg
жҸҗеҸ–з Ғпјҡ6547
02
еҫҖжңҹеӣһйЎҫ
PPT NO.4 жӣҙж”№PPTвҖңеҸҰеӯҳдёәвҖқеҲҶиҫЁзҺҮ
PPT NO.5 В з§‘з ”з»ҳеӣҫеёёз”Ёж“ҚдҪңеҝ«жҚ·й”®
03
еҚ•иҜҚз§ҜзҙҜ
a pyramid feature fusion moduleВ йҮ‘еӯ—еЎ”зү№еҫҒиһҚеҗҲжЁЎеқ—
a layer hopping connection moduleВ еұӮи·іжҺҘиҝһжҺҘжЁЎеқ—
convergence 收ж•ӣжҖ§
saliency detectionВ жҳҫи‘—жҖ§жЈҖжөӢ
a retinal network и§ҶзҪ‘иҶңзҪ‘з»ң


еҠ vxиҝӣдәӨжөҒзҫӨ

жү«жҸҸдәҢз»ҙз Ғ
е…іжіЁе…¬дј—еҸ·
