



Sora 是文生视频的集大成者,核心创新点在于时空编码和 DiT 模型。Sora 是 Open AI 推出的首个文本生视频模型,视频生成长度、逼真度等均 远超现有竞品。从技术上看,Sora 的核心创新点在于时空编码和 Diffusion Transformer 模型的应用。1)Spacetime patches 时空编码将一个完整视 频切分成带有时间维度的一系列 Tokens 输入 Transformer 模型,时空编 码的引入是 Sora 能够进行大规模视频数据训练的关键,同时为 Sora 的生 成结果具备三维一致性奠定了基础。2)DiT 模型结合了 Diffusion 扩散模 型和 Transformer 模型的优点,将传统扩散模型中采用的 U-Net 网络结构 替换成 Transformer,使得模型更擅长捕捉长距离的相关关系。
Sora 验证了 Diffusion+Transformer 的技术路线或是通往世界模型的 有效技术路径。神经网络模型的预测结果是概率输出,目前尚不具备因果 关系的推断能力,因此推理结果可能会出现常识错误或者违背现实物理规 律。而学界提出的世界模型概念旨在希望神经网络模型可以像人类一样理 解世界,具体可概括为具备以下三个特点:1)理解物理世界运行规律,像 人一样具备常识。2)具备泛化到训练样本以外的能力。3)可以基于记忆 进行自我演进。目前关于世界模型的技术路径尚有争议,但从 Open AI 的 官方展示视频来看,Sora 已经具备了世界模型的雏形,对于真实物理世界 有一定的模拟能力。因此我们认为 Sora 采用的 Diffusion+Transformer 的 技术路线或许是通往世界模型的有效技术路径。
特斯拉同样基于与 Sora 相似的技术路径已开始对世界模型进行探索。早在 2023 年 6 月召开的 CVPR 会议上,特斯拉已经分享了对于世界模型的 探索,Demo 展示效果惊艳:1)可以同时对车身周围八个摄像头周围未来 情况进行预测;2)可以精准的模拟过去难以描述的场景(如烟尘);3)可以根据动作指令调节;4)可以用来做分割任务。根据特斯拉 CVPR 上的演 讲及马斯克推特的公开回复,可以推断特斯拉大概率和 Open AI 一样采用 的是 Diffusion+Transformer 生成式 AI 的技术路线。而 Sora 的成功已经 率先在 AGI 领域验证了这条技术路线的可行性,由此我们认为 World Model 应用于智能驾驶的时代亦将加速到来。
世界模型中短期内应用于仿真环节,长期作为智驾基座大模型,引领行业迈向 L5 时代。世界模型在智能驾驶中的应用有望最先在仿真环节落地, 推动仿真场景泛化能力提升。当前智能驾驶仿真采用 NeRF+素材库排列组 合+游戏引擎的技术路线,虽然保证了场景的真实性但泛化性不足。世界模 型能够理解物理世界运行规律、同时具备泛化到训练样本以外的能力,因 此世界模型能够迅速生成非常真实和多样化的驾驶场景用于智能驾驶仿 真。长期来看世界大模型有望成为智驾的基座大模型,所有的智能驾驶下 游任务都可以通过简单的插入任务头来实现。届时,智能驾驶将不再存在 corner case,智能驾驶的驾驶安全性、驾驶效率都将占优于人类驾驶员。
1.Sora 验证了 DiT 模型的有效性,具备世界模型的雏形 1.1.Sora 是文生视频技术的集大成者,核心创新点在于时空编码及 DiT 模型 Sora 是 Open AI 推出的首个文生视频模型,效果远超现有竞品。一方面 Sora 大幅提升了行 业视频生成长度,Sora 可一次性生成 60s 高质量视频,远超此前 Pika 的 3 秒、Runaway Gen2 的 16 秒。并且 Sora 可在单个视频中进行多镜头切换,并保证了场景、物体在 3D 空间内的一致性。
从技术原理上看,Sora 本质上依然是基于 Transformer 模型,由 Transformer 三大 组件构成。包括:1)Visual Encoder 模块:根本目的是将一个视频通过一系列操作进行 Token 化(即时空编码 Spacetime patches);2)Diffusion Transformer 模块:用于视频的生成;3)Transformer Decoder:将生成的潜在表示映射回像素空间。其中 Sora 的核心创新点在于时空编码和 Diffusion Transformer 模型的应用。
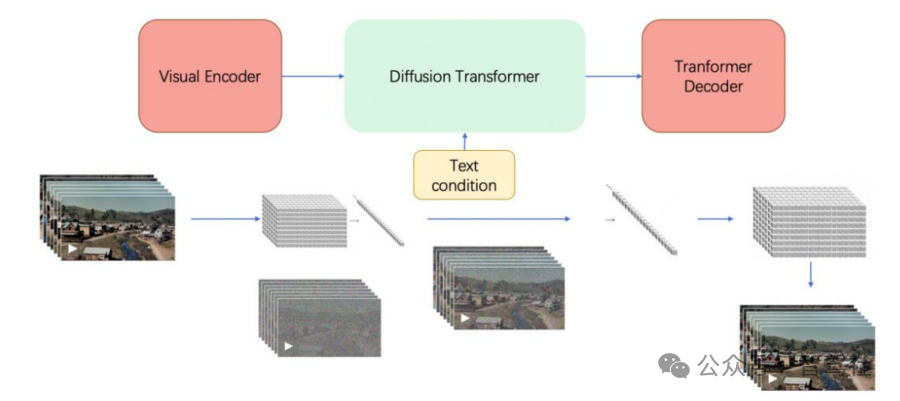
Sora 由 Transformer 三大组件构成
Spacetime patches(时空编码)的引入是 Sora 能够进行大规模视频数据训练的关键,同时 为 Sora 的生成结果具备三维一致性奠定了基础。Open AI 认为 LLM 范式的成功部分得益于 对 Tokens 的使用,这些 Token 统一了代码、数学和各种自然语言等不同模态的文本,语言模 型中的 Token 代表文本的最小单位,可以是单词、词组或者是标点符号等。将这个概念应用到视频领域,Sora 引入了 Spacetime patches(时空编码)作为视频的最小单位。Spacetime Patches 技术建立在 ViT(Vision Transformer)的研究基础之上。ViT 模型的思路是将图片 切成了多个 Patches(小块,类似于九宫格),再拉平成一系列 Tokens 输入 Transformer 模 型(目前自动驾驶行业中主流应用的“BEV+Transformer”也是以 ViT 为基础)。而 Spacetime Patches 在此基础上增加了时间维度,可以理解为 Sora 模型的一个 Patch 是一个小立方体。Spacetime patches 的引入使得 Sora 高效地训练大体量的视频数据(包括各种时长、分辨率、长宽比的视频数据)。并且 Spacetime patches 保证了前后帧之间的强相关关系,为 Sora 的生成结果具备三维一致性奠定了基础。
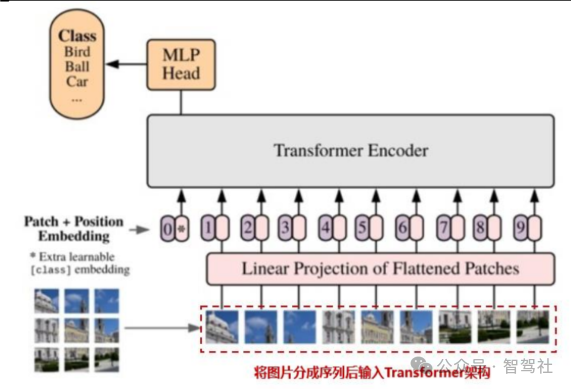
ViT 模型将图片切成多个 Patches
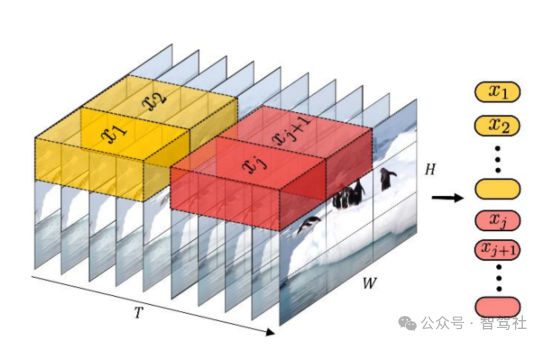
Spacetime patches 增加了时间维度
DiT 模型结合了 Diffusion 扩散模型和 Transformer 模型的优点。Diffusion 扩散模型本质作用,就是学习训练数据的分布,产出尽可能符合训练数据分布的真实图片。可以理解为根 据文本指令或者有噪音的图片模型“脑补”出完整图片/视频。“脑补”过程的思路是,从清晰 没有噪声的图像开始,每一步(timestep)都往上加一点噪声,得到噪声越来越大、越来越模糊的图像;同时在每一步里,都让模型根据当前步加噪后的图像去恢复出加噪前的图像, 也就是让模型学会去噪(加噪后的图像作为输入,加噪前的图像作为监督的正确答案,模型本质上是根据加噪前后的图像来学习拟合所添加的噪声)。这样训练完毕后,模型就可以从一 张纯噪声图像一步步还原出原始图片。在上述步骤里,一步步加噪的过程,就被称为 Diffusion Process;一步步去噪的过程,就被称为 Denoise Process。传统的 Diffusion 模 型采用 U-Net 网络架构,本质上是卷积神经网络。Sora 的创新之处在于用 Transformer 模型架构作为主干网络,通过 Transformer 来估测每一步加的噪音。这样做的好处在于将视频数据转换成 Token 之后,Transformer 更擅长捕捉长距离的相关关系。
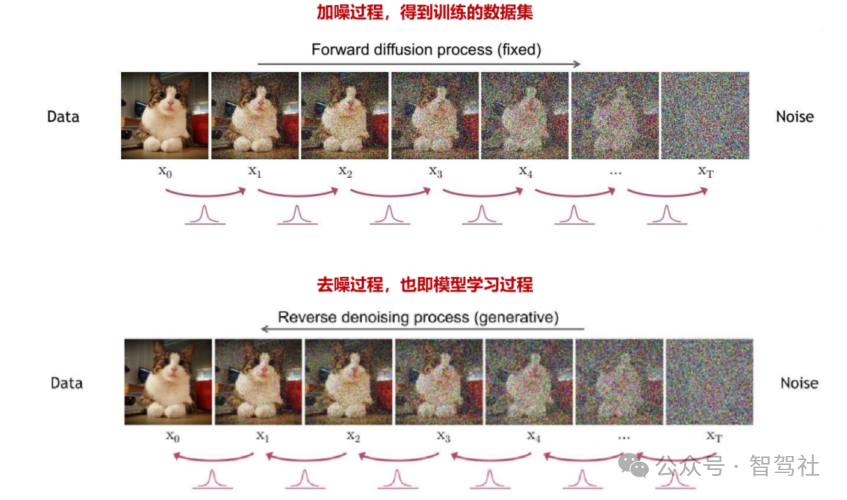
Diffusion 模型分为加噪和去噪两步
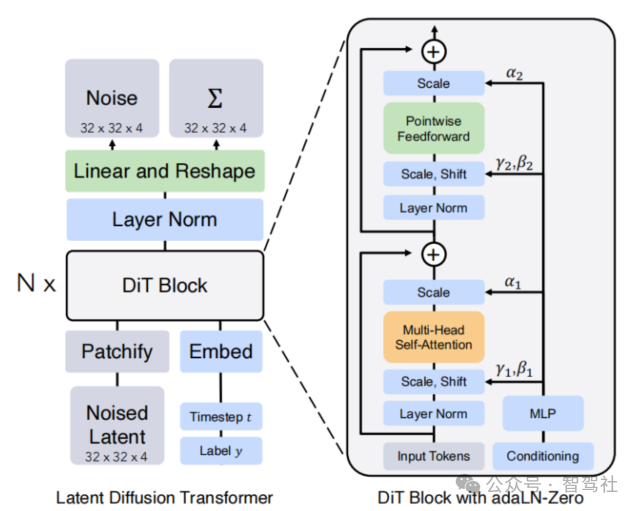
DiT 模型架构
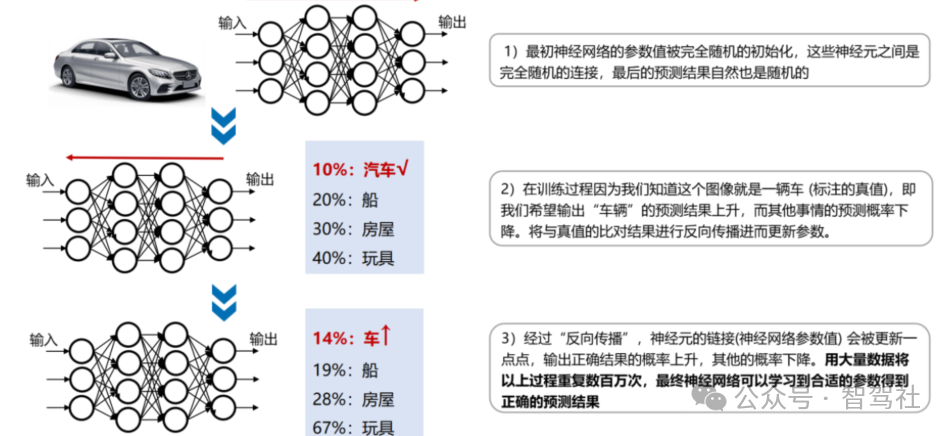
Sora 已初具世界模型雏形 神经网络模型预测结果是概率输出,现阶段尚不具备因果关系的推断能力,因此推理结果可能会出现常识错误或违背现实物理规律。神经网络模型通过反向传播和参数更新进行训练, 输出的结果是一个概率值:比如提供一张猫的图片给一个被训练用于识别猫的神经网络模型, 它的输出可能是“有 85%的概率是一只猫,有 10%的概率是一只狗,有5%的概率是一只老虎”, 随着不断的数据训练,模型输出猫的概率值会提升,但神经网络不真正“知道”什么是猫,不理解抽象的概念。再比如神经网络能够预测一个物体未来几帧中可能的轨迹,但它并不能理解这背后的物理规律(如重力、动力学等)。因为神经网络尚不理解底层事实,因此神经网络 的推理结果可能会出现常识错误或者违背现实物理规律。
World Model 世界模型的概念涵义来源于人类对世界体验和认知。人类可以通过观察、以及 通过无监督的方式进行交互来学习积累大量关于物理世界如何运行的常识,这些常识告诉人类什么是合理的、什么是不可能的,因此人类可以通过很少的试验学习新技能,可以预测自身行为的后果,所谓世界模型就是希望神经网络可以同样具备上述的能力。需要注意的是, 目前学界、业界对于 world model 世界模型并没有统一的定义,根据 Meta 首席科学家 LeCun 的演讲,我们总结世界大模型应该具备以下几个特点:1)能够理解物理世界运行规律,像人 一样具备“常识”,并能够基于对世界的理解来预测世界的演化;2)能够进行反事实推理,即对于数据中没有见过的决策,world model 也能推理出决策的结果,也可以理解为具备泛化 到训练样本以外的能力;3)具备基于记忆进行自我演进的能力。
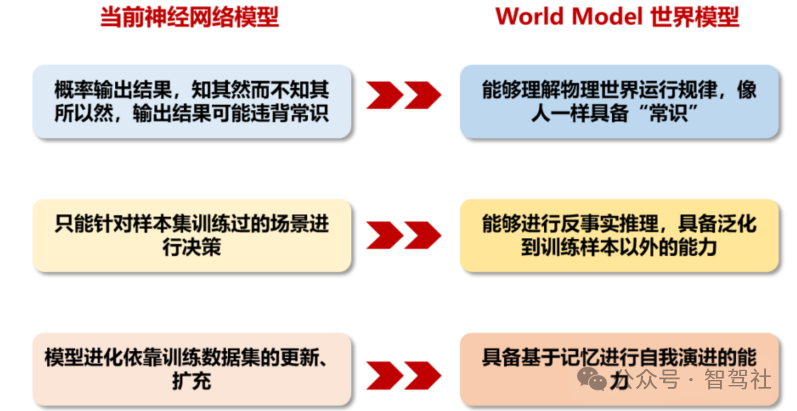
世界模型与当前神经网络模型对比
目前关于世界模型的技术路线尚有争议,Sora 采用的 Diffusion+Transformer 的技术路线 或许是通往世界模型的有效技术路径。当前关于探索世界模型的技术路线至少可以分为两类, 一类以 Meta 首席科学家 LeCun 代表,提出 JEPA 联合嵌入预测架构(非生成式 AI);另一类是以 Open AI 为代表的生成式 AI(主要基于 Diffusion+Transformer)技术路线,Open AI 在 Sora 技术文档中表示“扩展视频生成模型是构建物理世界通用模拟器的一条有前途的路 径。”从 Open AI 的官方展示视频来看,Sora 已经具备世界模型的雏形,对真实物理世界有了一定的模拟能力。如 Sora 生成的动态摄像机运动的视频,随着摄像机的移动旋转,人物和场景元素在三维空间中的移动是一致的。Sora 的负责人之一 Tim Brooks 表示工程师没有事 先设定这点,是 Sora 自己学习了大量关于 3D 几何的知识。同时,Sora 具备一定的和世界进 行互动的能力,如画家可以在画布上留下新的笔触,这些笔触会随着时间的推移而持续。

Sora 对真实物理世界具备一定的模拟能力
2.世界模型或将成为自动驾驶的最终解,引领行业迈向 L5 时代 2.特斯拉已开始对于世界模型的探索,将成为智驾模型的下阶段迭代方向 早在 2023 年 6 月召开的 CVPR 会议上,特斯拉和英国自动驾驶公司 Wayve 都分享了对于世界 模型的探索,其中 Wayve 将其命名为 GAIA-1,特斯拉则直接称之为 World Model。从特斯拉 展示的 Demo 来看,特斯拉 World Model 效果十分惊艳,具体表现在以下几方面:1) 视频预测:同时预测了汽车周围所有八个摄像头的情况,并且汽车颜色在各个摄像头之 间保持一致,物体的运动在三维空间中保持一致,这是模型自己学习的结果而非工程师设定。 2) 精准的模拟现实世界:一些过去难以描述的场景(如飘在空中的垃圾袋、烟尘等)都可 以在世界模型中得到准确表达。 3) 根据动作指令调节:如果要求模型直行,模型会直行;要求它变道,它就会变道。 4) 可以用来做分割任务(效果类似于 Meta 发布的 segment anything)。
 特斯拉 World Model 同时生成多视角预测情况
特斯拉 World Model 同时生成多视角预测情况
特斯拉 World Model 可用来做分割任务
 特斯拉 World Model 根据动作指令调节
特斯拉 World Model 根据动作指令调节
特斯拉尚未分享 World Model 具体的技术细节,但根据特斯拉在 CVPR 上的演讲内容、Demo 效果、以及马斯克在推特上的公开回复,可以推断特斯拉大概率和 Open AI 一样采用的是 Diffusion+Transformer 生成式 AI 的技术路线。而 Sora 的成功已经率先在 AGI 领域验证了 这条技术路线的可行性,由此我们认为 World Model 应用于智能驾驶的时代亦将加速到来。
世界模型有望大幅提升仿真的泛化能力,提升数据闭环效率 当前智能驾驶仿真主流的技术方案为 NeRF+素材库+游戏引擎,基于真实数据进行道路重建 保证和真实场景的相似程度,再依靠交通元素的不同排列组合进行有条件泛化,最后通过游 戏引擎输出高质量的仿真画面。以特斯拉 Simulation World Creator 为例:1)通过 NeRF+ 多趟重建的方式对真实场景数据进行道路重建。NeRF 神经辐射场解决的问题是多视角合成任 务,具体在智能驾驶场景下,可以理解为输入是某个十字路口一系列的 2D 图片,输出是该十 字路口的 3D 还原结果。2)利用素材库、导航地图添加道路旁植被、房屋、交通路牌、车辆 行人等交通要素,在这一过程中,通过道路街景随机生成以及车道链接关系的随机生成提高 了模型的泛化能力。3)用 Unreal 游戏引擎做运动学和动力学上的仿真使其满足真实物理时 间运行规律,同时做细节上的渲染使场景更加逼真。
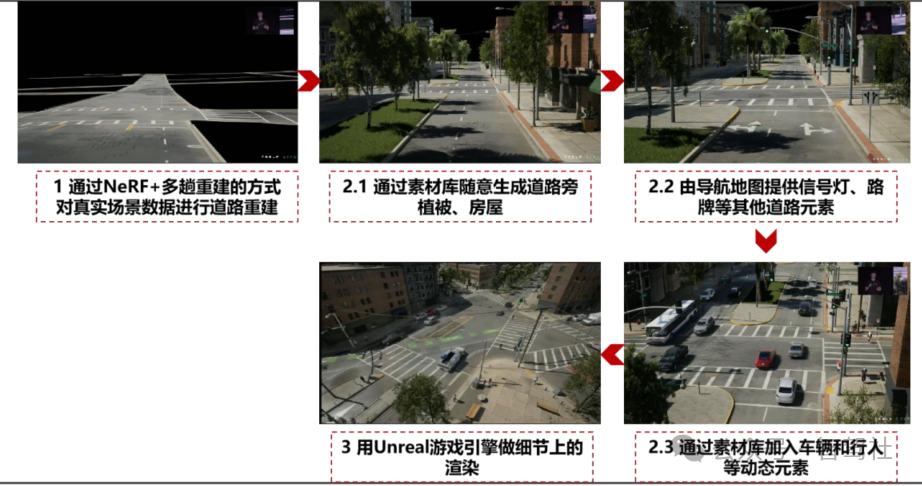
特斯拉 World Model 根据动作指令调节 仿真场景中对同一路口生成不同街景进行场景泛化
仿真场景中对同一路口生成不同街景进行场景泛化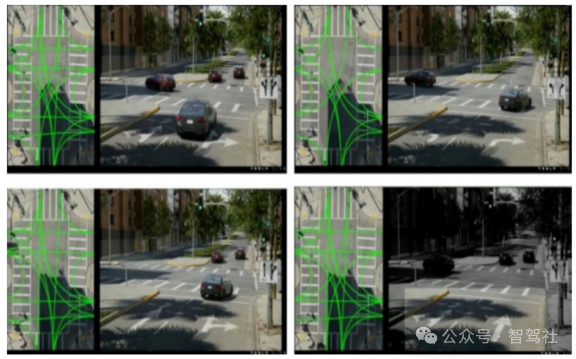 对同一路口生成不同车道关系进行场景泛化
对同一路口生成不同车道关系进行场景泛化
世界模型在智能驾驶中的应用有望最先在仿真环节落地,推动仿真场景大幅提升泛化能力。随着仿真数据质量的提升,智能驾驶厂商有望提高在模型训练中仿真数据的应用比例,从而 提高智能驾驶模型迭代速度、缩短开发周期。如前所述,当前智能驾驶仿真主要依赖 NeRF 对 于场景进行重建,NeRF 并非生成式 AI,因此相较于 Diffusion 的优势在于 NeRF 完全基于真 实场景进行还原,不会出现违背现实客观规律的情况。但基于 NeRF 做仿真的技术路线主要 通过人工进行泛化,即 NeRF 对真实场景进行重建后,再通过人为添加要素,如增添雨雾环 境、增加交通参与人数等方式对原始场景进行梯度泛化。但上述方式对场景的泛化能力依赖于工程师对于场景的理解,且存在经由手动添加元素后的场景与真实场景的拟合度不高的问题。如前所述,世界模型能够理解物理世界运行规律、同时具备泛化到训练样本以外的能力, 因此世界模型能够迅速生成非常真实和多样化的驾驶场景用于智能驾驶仿真。具体而言,特斯拉以及 Wayve 在 CVPR2023 中展示了世界模型应用于智能驾驶仿真的潜力:1)根据几秒钟的视频启动,世界模型可以生成多种可能的未来场景,且越往后差异越大,泛化能力强。2) 根据语言提示生成特定的假设场景,比如直行或者左右转、不同的环境、光影条件等,甚至可以生成世界模型从未见过的极端场景。根据九章智驾数据,当前智能驾驶厂商训练模型时 真实数据与仿真数据的比例为 7:3,我们认为世界模型应用仿真环节将大幅推动仿真数据质量,降低智能驾驶厂商对于真实数据的依赖度,从而提高智能驾驶模型训练效率。
 世界模型可以泛化出真实、多样化的驾驶场景用户智驾仿真
世界模型可以泛化出真实、多样化的驾驶场景用户智驾仿真
长期看,世界模型有望成为智能驾驶的基座大模型。如我们在报告中的分析,特斯拉从 2018 年开始尝试用 Hydranets 多任务网络来提高模型效率,模型具有一个共享的 backbone 骨干网络,再输出多个任务头,后续的 BEV、
Occupancy 模型也同样延续了这一思想。事实上,Occupancy 模型架构里很大一部分的作用是在向量空间内描述世界特征,然后再接多个任务头(task head)。比如 23 年 12 月特斯拉推出的高保真泊车辅助功能就是在 Occupancy 模型上接一个 Distance Field(距离场,用于显
示周围障碍物距离)任务头,进行回归测试以获得距离感。以此为延申,如果世界模型能够
包含物理世界的全部特征,那么就能够利用这些向量空间特征捕捉到智能驾驶所需要的相关信息,比如体积占用、路面、物体、车道线、红绿灯等等。因此,所有的智能驾驶下游任务
都可以通过简单地插入(plugging)任务头来实现。特斯拉 Autopilot 资深工程师 Phil Duan
在 2023 年 CVPR 上称“接下来的很多步骤将是在应用层面上的,以一种非常轻量化的方式来推
导不同场景下的应用”。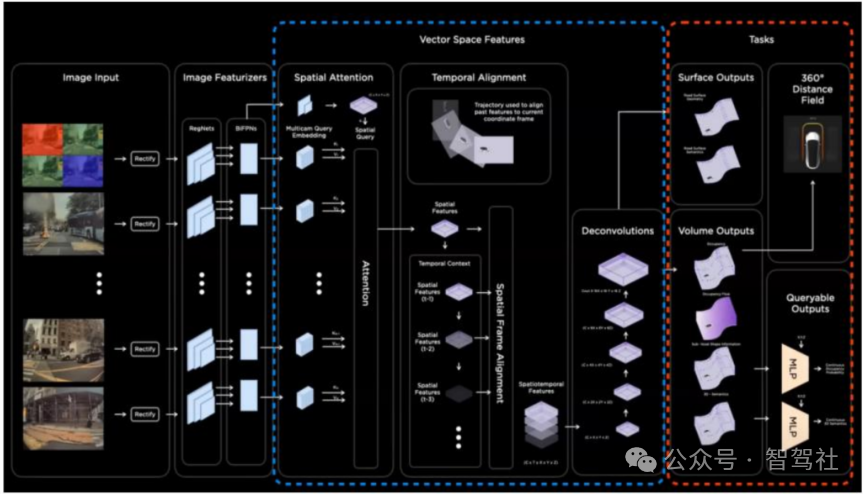 Occupancy 模型中很大一部分用于构建向量空间特征
Occupancy 模型中很大一部分用于构建向量空间特征 World Model 世界大模型作为下游所有任务的基座模型
World Model 世界大模型作为下游所有任务的基座模型
World Model 有望成为智能驾驶终极技术路线,带领智驾进入 L5 时代。回顾智能驾驶行业技 术发展方向,本质上都是在解决模型的泛化性问题。特斯拉 2020-2022 年间提出的“BEV+Occupancy”感知技术架构分别解决了智能驾驶对高精度地图的强依赖问题和一般障碍 物的识别问题,大幅提升了智能驾驶感知端的泛化能力,带领智能驾驶进入 L3 时代。但目前智能驾驶依然存在面对复杂的十字路口这种强博弈场景中通行效率低、对于未训练过的边缘 场景无法决策的问题,根本原因在于智能驾驶系统决策端无法对周围环境进行准确的预测, 而人类司机因为有大量“常识”的积累,在驾驶过程中可以更加准确的预判未来不久后的场景,这是目前智驾系统与人类司机的主要差异所在。而 World Model 类似于一种预演机制, 通过推测未来的方式对世界进行建模,同时由于 World Model 能够了解物理世界运行的底层规律,因此能够相对准确的对周围环境未来状态进行预测。并且,由前所述,World Model 具备泛化到训练数据集以外的能力,因此基于 World Model 的智驾系统遇到未见过的场景也能 采用最小风险策略进行决策,届时,智能驾驶将不再存在 corner case,智能驾驶的驾驶安全性、驾驶效率都将占优于人类驾驶员。
材料来源 国投证券