



еҜјиҜ»В жң¬ж–Үе°ҶеҲҶдә«ж•°е…ғзҒөиҝ‘жңҹеҹәдәҺAIGCеңЁз”өе•ҶйўҶеҹҹзҡ„ж–ҮжЎҲз”ҹжҲҗе’ҢеӣҫеғҸз”ҹжҲҗж–№еҗ‘зҡ„е®һи·өпјҢдё»иҰҒеҶ…е®№еҢ…жӢ¬д»ҘдёӢеҮ еӨ§йғЁеҲҶпјҡ
еҜјиЁҖ
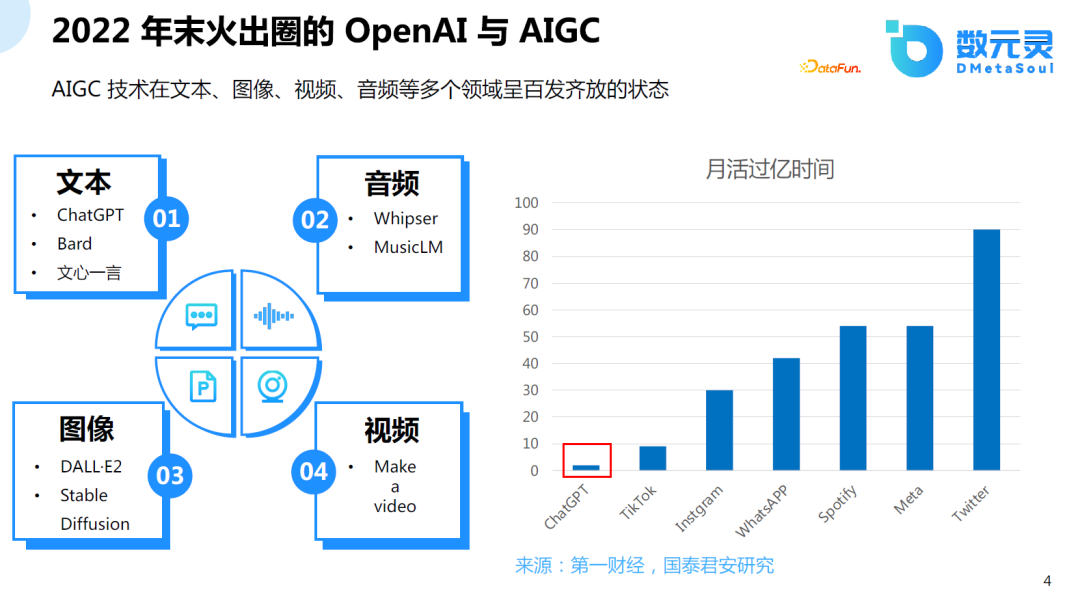
2022е№ҙжҳҜAIеҺҶеҸІдёҠе…·жңүйҮҢзЁӢзў‘ж„Ҹд№үзҡ„дёҖе№ҙпјҢAIеҸ‘еұ•дёәдҪң家гҖҒ画家гҖҒйҹід№җ家гҖҒеҜјжј”зӯүпјҢзү№еҲ«жҳҜChatGPTи®©AIеҪ»еә•еҮәеңҲпјҢдёҚж–ӯжңүйқһи®Ўз®—жңәдё“дёҡзҡ„дәәи°Ҳи®әAIжҳҜеҗҰиғҪеӨҹйў иҰҶе·Іжңүзҡ„жЁЎејҸгҖӮChatGPTд№ҹжҲҗдёә继жҠ–йҹід»ҘеҗҺпјҢжңҖеҝ«зҡ„жңҲжҙ»иҝҮдәҝзҡ„дә§е“ҒгҖӮ
е…ҲеӣһйЎҫдёҖдёӢиҝҮеҺ»еҚҒе№ҙжқҘ AIGC йўҶеҹҹдёӯжҜ”иҫғйҮҚиҰҒзҡ„е·ҘдҪңгҖӮ2013е№ҙиҮі2017е№ҙдё»иҰҒеӨ„дәҺеҹәзЎҖзҗҶи®әйҖҗжёҗе®Ңе–„зҡ„йҳ¶ж®өпјҢеңЁиҝҷдёӘйҳ¶ж®өVAEгҖҒGANгҖҒTransformerзӯүж·ұеәҰзҘһз»ҸзҪ‘з»ңжЁӘз©әеҮәдё–пјҢеӨ„дәҺеҹәзЎҖ组件йҖҗжёҗиҜһз”ҹе’Ңе®Ңе–„зҡ„йҳ¶ж®өпјӣ2018е№ҙиҮі2021е№ҙпјҢи¶…еӨ§и§„жЁЎзҡ„жЁЎеһӢйҖҗжёҗжөҒиЎҢпјҢеӨҡжЁЎжҖҒйҖҗжёҗиһҚеҗҲпјҢ并且еӨ§иҜӯиЁҖжЁЎеһӢзҡ„йў„и®ӯз»ғзҡ„еӯҰд№ ж–№ејҸжҲҗдёәеҸҜиғҪпјҢ Few Shot Learningе’ҢIncontext LearningзӯүеӯҰд№ иҢғејҸиў«жҸҗеҮәпјӣд»Һ2022е№ҙеҲ°зҺ°еңЁеӨ„дәҺ第дёүдёӘйҳ¶ж®өпјҢAIGCйӣҶдёӯзҲҶеҸ‘пјҢжЁЎеһӢж•Ҳжһңзҡ„зңҹе®һжҖ§гҖҒи®Ўз®—ж•ҲзҺҮе…ЁйқўжҸҗеҚҮгҖӮжңҖиҝ‘пјҢеҫ®иҪҜеҸ‘иЎЁж–Үз« иҜҙжҳҺеӨ§жЁЎеһӢиғҪеҠӣж¶ҢзҺ°пјҢејәдәәе·ҘжҷәиғҪе·Із»ҸејҖе§ӢеҮәзҺ°гҖӮ

02
е•Ҷе“Ғж–ҮжЎҲз”ҹжҲҗ
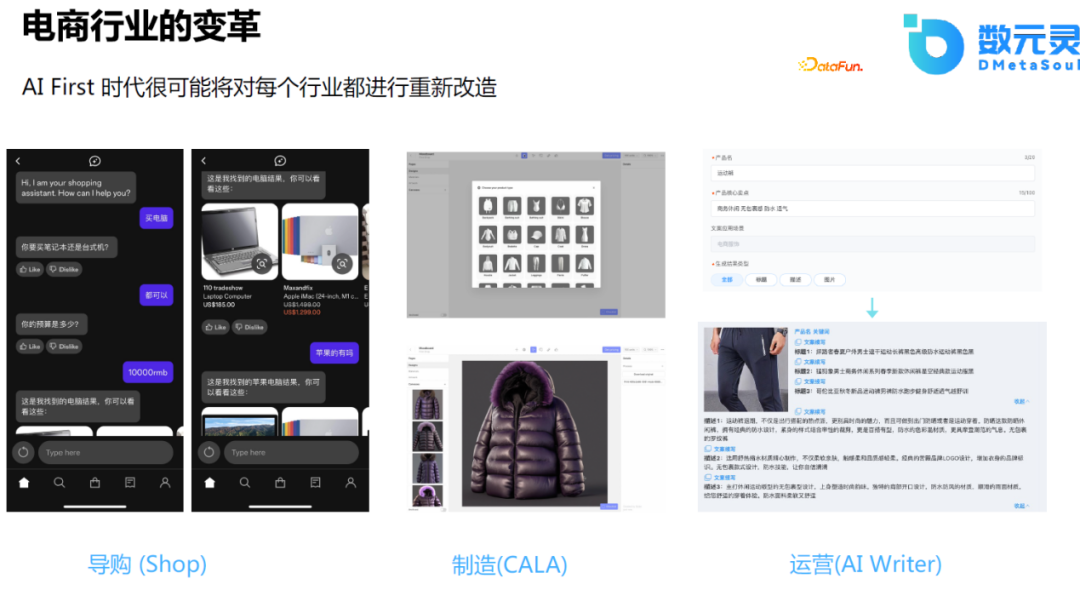
дә§е“Ғж–ҮжЎҲеҜ№дәҺз”өе•ҶеҜјиҙӯиҝҮзЁӢжҳҜйқһеёёйҮҚиҰҒзҡ„пјҢеӣ дёәеҫҲеӨҡиҙӯзү©иҖ…еҸҜиғҪйҰ–е…Ҳдјҡиў«дә§е“Ғзҡ„ж ҮйўҳжүҖеҗёеј•пјҢеҫҲеӨҡзҡ„е”®еҗҺй—®йўҳеҸҜиғҪжәҗдәҺдә§е“Ғзҡ„жҸҸиҝ°й”ҷиҜҜпјҲдә§е“ҒдёҺжҸҸиҝ°дёҚз¬ҰпјүгҖӮдҪҶжҳҜпјҢзј–еҶҷдә§е“Ғзҡ„ж–ҮжЎҲжҳҜдёҖ件д»ӨдәәеӨҙз–јзҡ„дәӢжғ…пјҢеӣ дёәеҘҪзҡ„ж–ҮжЎҲйңҖиҰҒйҰ–е…ҲдәҶи§ЈдәәзҫӨзҡ„з”»еғҸпјҢиҝҳйңҖиҰҒеҫҲеӨҡSEOзҡ„жҠҖе·§пјҢжғіиҰҒжҢҒз»ӯдә§еҮәй«ҳиҙЁйҮҸзҡ„ж–ҮжЎҲйңҖиҰҒжҠ•е…ҘеӨ§йҮҸзҡ„дәәеҠӣгҖӮ
йҡҸзқҖAIжҠҖжңҜзҡ„еҸ‘еұ•пјҢиҮӘеҠЁз”ҹжҲҗй«ҳиҙЁйҮҸзҡ„дә§е“Ғж–ҮжЎҲпјҢдёҚдҪҶеҸҜд»Ҙж»Ўи¶іе®ўжҲ·зҡ„йңҖжұӮпјҢиҝҳеҸҜд»ҘжҢҒз»ӯиҝҪиёӘзғӯй—ЁдәӢ件пјҢдёҚж–ӯжҸҗеҚҮж–ҮжЎҲзҡ„иҙЁйҮҸе’ҢзЁіе®ҡжҖ§гҖӮ
дёӢеӣҫеҸідҫ§жҳҜдёӨдёӘдҫӢеӯҗпјҢдёҖдёӘжҳҜдј з»ҹзҡ„жңҚйҘ°з”өе•ҶпјҢеҸҰдёҖдёӘжҳҜй…’ж—…иЎҢдёҡгҖӮе®ўжҲ·еҸӘйңҖз»ҷеҮәдә§е“Ғзҡ„зү№зӮ№пјҢеӨ§иҜӯиЁҖжЁЎеһӢжҠҖжңҜзӣҙжҺҘз”ҹжҲҗзӣёеә”зҡ„ж–ҮжЎҲгҖӮ

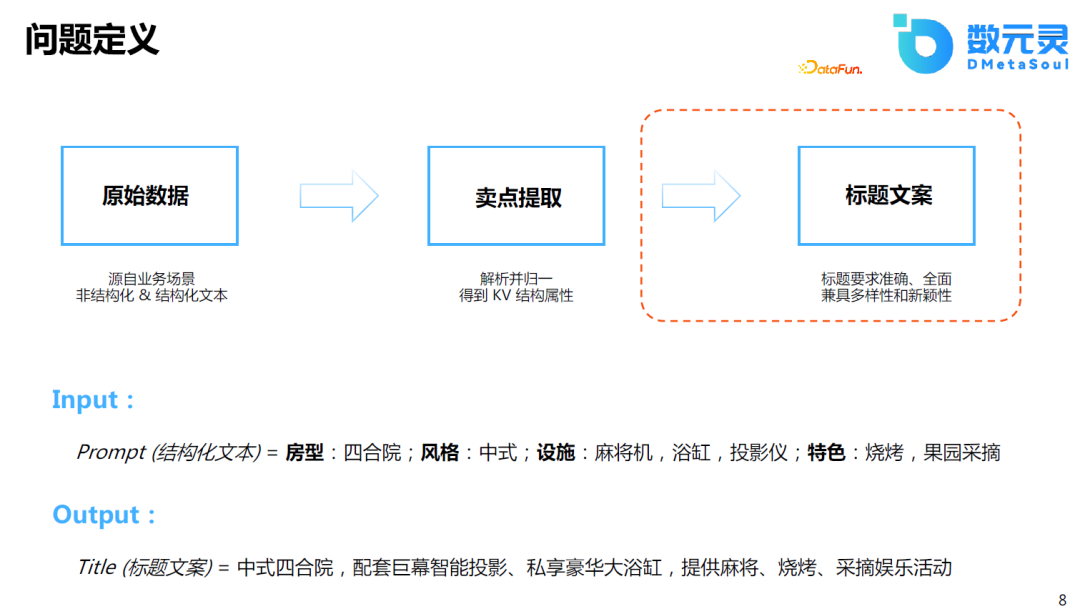
йӮЈд№ҲиҜҘеҰӮдҪ•е®ҡд№үиҜҘй—®йўҳпјҹд»Ҙж°‘е®ҝж–ҮжЎҲи®ҫи®ЎдёәдҫӢпјҢеңЁе®һйҷ…зҡ„еә”з”ЁдёӯпјҢеҺҹе§Ӣж•°жҚ®еҸҜиғҪжҳҜдёҖдәӣз»“жһ„еҢ–жҲ–йқһз»“жһ„еҢ–зҡ„ж•°жҚ®пјҢе®ўжҲ·еҸҜиғҪд№ҹдёҚжё…жҘҡдә§е“Ғзҡ„еҚ–зӮ№жҳҜд»Җд№ҲгҖӮеҰӮдҪ•еҒҡеҚ–зӮ№жҸҗеҸ–пјҢеҚ–зӮ№жҸҗеҸ–д»ҘеҗҺеҰӮдҪ•з”ҹжҲҗж ҮйўҳгҖӮиҝҷдәӣйғҪйңҖиҰҒе…¶е®ғжҠҖжңҜд»Ӣе…ҘгҖӮ
з”ұдәҺд»ҠеӨ©еҲҶдә«зҡ„жҳҜAIGCзҡ„ж–№еҗ‘пјҢжүҖд»Ҙдё»иҰҒиҒҡз„ҰдәҺеҚ–зӮ№е·ІзҹҘзҡ„жғ…еҶөдёӢпјҢеҰӮдҪ•з”ҹжҲҗиҫғеҘҪзҡ„ж–ҮжЎҲгҖӮеҰӮе®ўжҲ·еҸӘйңҖиҰҒз®ҖеҚ•ең°иҫ“е…ҘжҲҝеһӢгҖҒйЈҺж јзӯүзү№еҫҒзҡ„жҸҸиҝ°пјҢжЁЎеһӢе°ұиғҪеӨҹиҜҶеҲ«еҮәе…¶дёӯжҜ”иҫғйҮҚиҰҒзҡ„дҝЎжҒҜпјҢ并д»ҘжҜ”иҫғеҘҪзҡ„ж–ҮйҮҮеҜ№дә§е“Ғзҡ„ж ҮйўҳжҲ–жҸҸиҝ°иҝӣиЎҢж¶ҰиүІжҲ–з”ҹжҲҗгҖӮ
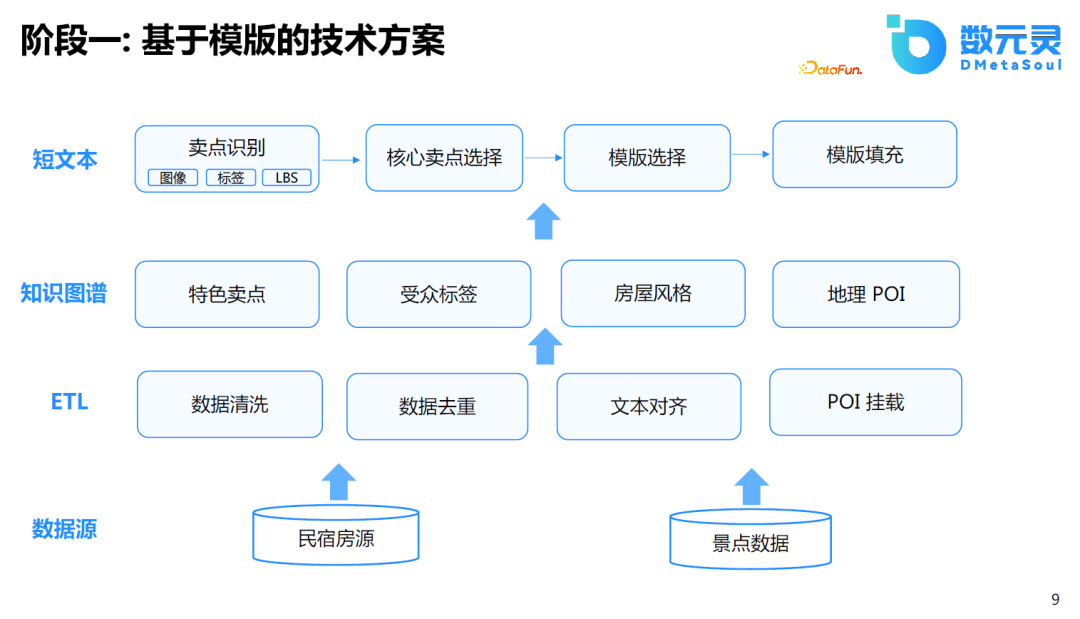
еҮ е№ҙеүҚпјҢжҲ‘们д№ҹе°қиҜ•иҝҮдҪҝз”ЁеҹәдәҺжЁЎжқҝзҡ„ж–№ејҸеҒҡзұ»дјјзҡ„д»»еҠЎгҖӮеҒҡжі•жҳҜйҰ–е…ҲжҸҗеҸ–дә§е“Ғзҡ„зҹҘиҜҶпјҢеҜ№зҹҘиҜҶиҝӣиЎҢз»“жһ„еҢ–еӨ„зҗҶпјҢеҪўжҲҗзҹҘиҜҶеӣҫи°ұгҖӮеңЁзҹҘиҜҶеӣҫи°ұзҡ„еҹәзЎҖдёҠпјҢеҒҡж ёеҝғеҚ–зӮ№зҡ„йҖүжӢ©гҖҒжЁЎжқҝзҡ„йҖүжӢ©е’ҢеҚ–зӮ№зҡ„еЎ«е……гҖӮиҝҷз§ҚеҒҡжі•дё»иҰҒеҹәдәҺжЁЎжқҝе®һзҺ°пјҢеҸ—йҷҗдәҺжЁЎжқҝж•°йҮҸе’Ңдәәдёәзҡ„жҖ»з»“пјҢзӣёеҜ№жқҘиҜҙжҜ”иҫғжӯ»жқҝгҖӮ
з»“еҗҲиҝ‘жңҹжҠҖжңҜзҡ„иҝӣжӯҘпјҢжҲ‘们иҖғиҷ‘з»“еҗҲзәҜзІ№зҡ„з”ҹжҲҗејҸиҜӯиЁҖжЁЎеһӢзҡ„ж–№жЎҲжҳҜеҗҰеҸҜиЎҢгҖӮзү№еҲ«жҳҜеңЁChatGPTеҮәжқҘд№ӢеҗҺпјҢ GPTзі»еҲ—зҡ„жЁЎеһӢе·Із»ҸеҸҜд»Ҙеё®еҠ©дәә们е®һзҺ°дёҖдәӣиҜ„и®әгҖҒйӮ®д»¶зҡ„еҶҷдҪңпјҢеӣ жӯӨиҖғиҷ‘дҪҝз”Ёзұ»дјјзҡ„з”ҹжҲҗжЁЎеһӢе®ҢжҲҗдёҠиҝ°зҡ„д»»еҠЎгҖӮеңЁеҲқжӯҘзҡ„е®һйӘҢеҗҺпјҢеҸ–еҫ—зҡ„ж•ҲжһңжҜ”еҹәдәҺжЁЎжқҝзҡ„з»“жһңжӣҙеҘҪгҖӮеңЁиҝҷд№ӢеҗҺпјҢжҲ‘们еҸҲиҝӣиЎҢз®—жі•дёҠзҡ„иҝӯд»ЈгҖӮеңЁж·ұе…ҘиҝҷйғЁеҲҶеҶ…е®№еүҚпјҢжҲ‘们е…ҲжқҘеӣһйЎҫдёҖдёӢ GPT зі»еҲ—жЁЎеһӢзҡ„еҹәжң¬еҺҹзҗҶгҖӮ
еңЁжӯЈејҸд»Ӣз»Қе…·дҪ“зҡ„жҠҖжңҜж–№жЎҲеүҚпјҢе…Ҳд»Ӣз»ҚдёҖдёӢGPTзҡ„еҺҹзҗҶгҖӮGPTзҡ„ж ёеҝғжҖқжғіжҜ”иҫғз®ҖеҚ•пјҢеҚідәәзұ»зҡ„зҹҘиҜҶи•ҙеҗ«дәҺдәәзұ»зҡ„иҜӯиЁҖдёӯпјҢеҰӮжһңиғҪе®ҢзҫҺең°йў„жөӢдёӢдёҖдёӘиҜҚпјҢйӮЈд№ҲжЁЎеһӢд№ҹеҸҜд»ҘжЁЎжӢҹдәәзұ»зҡ„жҖқз»ҙпјҢд№ҹе°ұе…·жңүдәҶжҷәиғҪгҖӮеҒҮи®ҫеҪ“n=tж—¶пјҢеҸҜзҹҘпјҢеҪ“n=t+1ж—¶пјҢд№ҹеҸҜд»Ҙйў„жөӢгҖӮд»»дҪ•дёҺиҜӯиЁҖзӣёе…ізҡ„д»»еҠЎпјҢеҸҜд»ҘжҠҪиұЎдёәиҝҷзұ»з”ҹжҲҗд»»еҠЎпјҢйғҪеҸҜд»Ҙз”ЁиҜӯиЁҖжЁЎеһӢзҡ„ж–№ејҸжұӮи§ЈгҖӮ
дҪҶе’Ңж•°еҚҒе№ҙеүҚзҡ„иҜӯиЁҖжЁЎеһӢдёҚеҗҢзҡ„жҳҜпјҢзҺ°еңЁзҡ„иҜӯиЁҖжЁЎеһӢйҖҡиҝҮеӨ§и§„жЁЎTransformerзҡ„ж·ұеәҰзҘһз»ҸзҪ‘з»ңиҝӣиЎҢе»әжЁЎгҖӮеҘҪеӨ„жҳҜпјҡ
еҸҜд»ҘжӣҙеҮҶзЎ®ең°е»әжЁЎдёӢдёҖдёӘиҜҚзҡ„жҰӮзҺҮпјӣ
еҸҜд»ҘиҝӣиЎҢй«ҳж•Ҳзҡ„жЁЎеһӢи®ӯз»ғе’ҢжҺЁзҗҶпјӣ
еҸҜд»Ҙи§ЈеҶіеҹәдәҺй•ҝи·қзҰ»зҡ„иҜӯд№үдҫқиө–гҖӮ

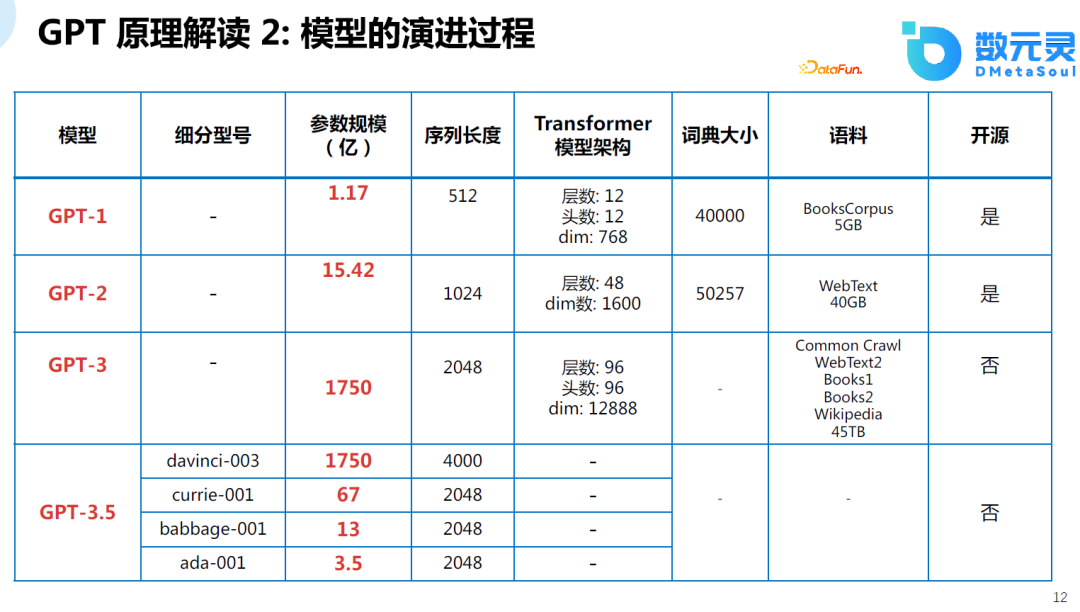
з”ұOpenAIзҡ„жҠҖжңҜиҝӯд»ЈиҝҮзЁӢеҸҜд»ҘеҸ‘зҺ°пјҢдёҚд»…жЁЎеһӢзҡ„规模и¶ҠжқҘи¶ҠеӨ§пјҢж•°жҚ®зҡ„规模д№ҹеңЁеўһеҠ гҖӮеңЁеӨ§и§„жЁЎиҜӯж–ҷж•°жҚ®гҖҒеӨ§и§„жЁЎжЁЎеһӢзҡ„еҹәзЎҖдёҠпјҢжЁЎеһӢзҡ„иғҪеҠӣд№ҹи¶ҠжқҘи¶ҠејәпјҢеҸ‘еұ•еҲ°GPT-4дёҚд»…еҸҜд»ҘеӨ„зҗҶж–Үжң¬иҜӯиЁҖпјҢд№ҹеҸҜд»ҘеӨ„зҗҶеӨҡжЁЎжҖҒзҡ„ж•°жҚ®гҖӮз”ұдәҺ GPT-4д»Һе…¬ејҖзҡ„иө„ж–ҷдёӯиғҪиҺ·еҸ–зҡ„дҝЎжҒҜйқһеёёжңүйҷҗпјҢиҝҷйҮҢд»…еҲ—дёҫдёҖдёӢ GPT-3.5 д№ӢеүҚOpenAIжҺЁеҮәзҡ„жЁЎеһӢзӣёе…іеҸӮж•°пјҲGPT-3.5жҳҜOpenAIжҺЁеҮәзҡ„дёҖеҲ—жЁЎеһӢпјҢChatGPT еҸҲз§° GPT-3.5-TurboпјҢдҪҶдёҚеңЁжӯӨиЎЁдёӯпјүгҖӮ
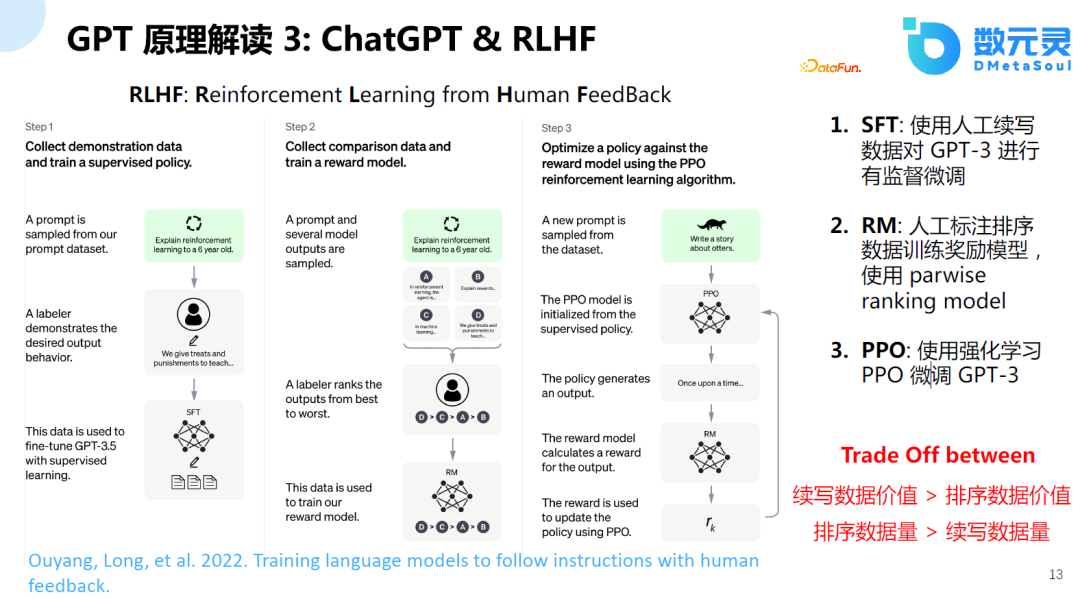
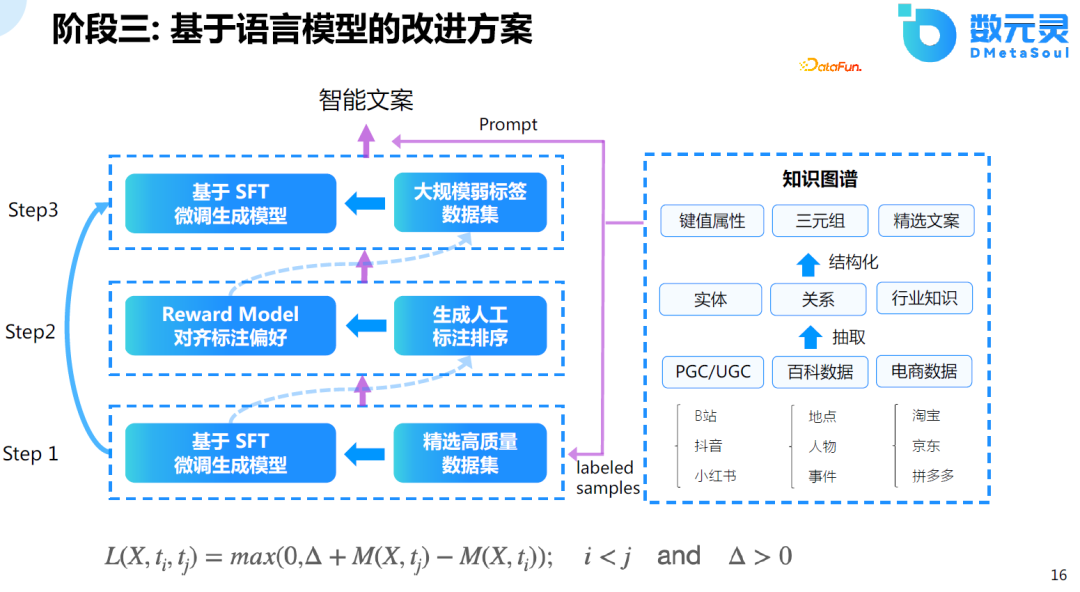
еҺ»е№ҙе№ҙжң«пјҢOpenAIеҸҲжҸҗеҮәдәҶChatGPTпјҲGPT-3.5-TurboпјүеҸҠдәәе·ҘејәеҢ–еӯҰд№ еҸҚйҰҲзҡ„жҠҖжңҜпјҢеҜ№ж•ҙдёӘзӨҫдјҡйҖ жҲҗдәҶе·ЁеӨ§зҡ„еҪұе“ҚгҖӮйҖҡиҝҮиҜҘжҠҖжңҜпјҢе®һзҺ°AIеҜ№йҪҗдәәзұ»еҒҸеҘҪзҡ„иғҪеҠӣгҖӮChatGPTд№ӢеүҚзҡ„жЁЎеһӢе·Із»Ҹе…·еӨҮдәҶеҫҲеҘҪзҡ„ж–Үжң¬з”ҹжҲҗзҡ„иғҪеҠӣпјҢдҪҶжҳҜз”ҹжҲҗзҡ„ж–Үжң¬е’Ңдәәзұ»зҡ„еҒҸеҘҪжІЎжңүеҜ№йҪҗпјҢChatGPTдё»иҰҒй’ҲеҜ№дәәзұ»зҡ„еҒҸеҘҪиҝӣиЎҢеҜ№йҪҗгҖӮ
иҝҷдёӘи®ӯз»ғиҝҮзЁӢдё»иҰҒеҲҶдёәдёүдёӘйҳ¶ж®өпјҡ
SFTйҳ¶ж®ө: дҪҝз”Ёдәәе·Ҙз»ӯеҶҷж•°жҚ®еҜ№text-davinci-003жЁЎеһӢиҝӣиЎҢжңүзӣ‘зқЈеҫ®и°ғпјӣ
RMйҳ¶ж®ө:В дәәе·Ҙж ҮжіЁжҺ’еәҸж•°жҚ®пјҢдҪҝз”Ёpairwaise ranking жЁЎеһӢи®ӯз»ғеҘ–еҠұжЁЎеһӢпјӣ
RLHFйҳ¶ж®өпјҡдҪҝз”ЁејәеҢ–еӯҰд№ PPOеҫ®и°ғеӨ§иҜӯиЁҖжЁЎеһӢгҖӮ
йңҖиҰҒиҜҙжҳҺзҡ„жҳҜпјҢж–ҜеқҰзҰҸеӨ§еӯҰеңЁзҫҠй©јзҡ„еҹәзЎҖдёҠпјҢдҪҝз”ЁSelf-InstructжҠҖжңҜиҝӣиЎҢи®ӯз»ғпјҢ并没жңүдҪҝз”ЁRLHFзҡ„и®ӯз»ғж–№ејҸпјҢеҸ–еҫ—зҡ„ж•Ҳжһңд№ҹдёҚй”ҷгҖӮ
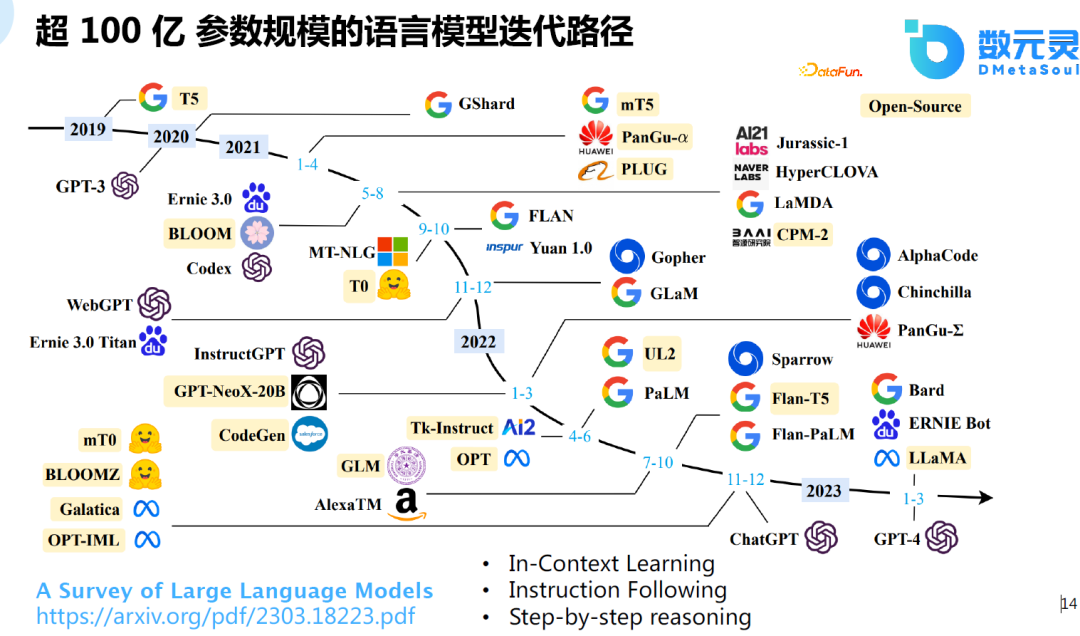
иҝ‘жңҹзҡ„дёҖзҜҮз»јиҝ°ж–Үз« пјҢи°ғз ”дәҶи¶…100дәҝеҸӮ数规模зҡ„иҜӯиЁҖжЁЎеһӢиҝӯд»Ји·Ҝеҫ„гҖӮдёәд»Җд№ҲжҳҜ100дәҝпјҹжЁЎеһӢеңЁ100дәҝеҸӮж•°ж—¶дјҡеҮәзҺ°ж¶ҢзҺ°зҡ„иғҪеҠӣпјҢиҖҢиҝҷеңЁд»ҘеүҚзҡ„е°ҸжЁЎеһӢдёӯжҳҜдёҚеӯҳеңЁзҡ„гҖӮе®һйӘҢеҸ‘зҺ°пјҢжЁЎеһӢеңЁ60-70дәҝеҸӮж•°йҮҸж—¶пјҢжЁЎеһӢзҡ„иғҪеҠӣдјҡжҳҫи‘—жҸҗеҚҮпјҢиҝҷд№ҹжҳҜChatGPTжҲ–зұ»дјјжЁЎеһӢжңүеҰӮжӯӨејәеӨ§зҡ„еҠҹиғҪзҡ„еҹәзЎҖгҖӮ
иҝҷйҮҢдё»иҰҒеҢ…еҗ«дәҶд»ҘдёӢеҮ дёӘж–№йқўпјҢйҰ–е…ҲжҳҜIn-Context learningпјҢеҚідёҠдёӢж–ҮеӯҰд№ пјҢжҳҜOpenAIжҸҗеҮәзҡ„дёҖз§ҚжЁЎејҸпјҢдёҚйңҖиҰҒжўҜеәҰжӣҙж–°пјҢеҸӘйңҖз»ҷеҮәдёҖдәӣдҫӢеӯҗпјҢжЁЎеһӢиғҪеӨҹзҹҘйҒ“иҜҘдҫӢеӯҗзҡ„еҗ«д№үпјҢеҜ№дәҺж–°зҡ„д»»еҠЎпјҢжЁЎеһӢиғҪеӨҹз»ҷеҮәдёҚй”ҷзҡ„йў„жөӢз»“жһңгҖӮ第дәҢжҳҜInstruction FollowingпјҢжЁЎеһӢиғҪеӨҹеҗ¬жҮӮжҢҮд»ӨпјҢдҫӢеҰӮпјҢз»ҷеҮәжҢҮд»Өпјҡеё®жҲ‘еҶҷд»Јз ҒпјҢжЁЎеһӢиғҪеӨҹз»ҷеҮәиҫғеҘҪзҡ„responseгҖӮжңҖеҗҺе°ұжҳҜStep-by-step reasoningпјҢд№ӢеүҚзҡ„иҜӯиЁҖжЁЎеһӢеңЁи§Јж•°еӯҰйўҳж—¶иЎЁзҺ°дёҚеҘҪпјҢи°·жӯҢжҸҗеҮәдәҶtrain of sourceзҡ„е·ҘдҪңпјҢдҪҝжЁЎеһӢеҸҜд»ҘдёҖжӯҘжӯҘең°еӯҰд№ пјҢеңЁеёёиҜҶжҺЁзҗҶгҖҒйҖ»иҫ‘жҺЁзҗҶеҸҠж•°еӯҰйўҳдёӯиЎЁзҺ°иҫғеҘҪпјҢиҝҷд№ҹжҳҜеӨ§жЁЎеһӢеңЁ100дәҝеҸӮж•°йҮҸзҡ„еҹәзЎҖдёҠеҸҜиғҪдјҡж¶ҢзҺ°еҮәжқҘзҡ„иғҪеҠӣгҖӮ
з”ұдәҺз®—еҠӣзҡ„йҷҗеҲ¶пјҢжҲ‘们йҰ–е…ҲеңЁGPT2зҡ„еҹәзЎҖдёҠиҝӣиЎҢеҫ®и°ғпјҢеҸ‘зҺ°ж•ҲжһңжҜ”еҹәдәҺжЁЎжқҝзҡ„з»“жһңжӣҙеҘҪгҖӮдҪҶеңЁе…¶дёӯд№ҹеҸ‘зҺ°дәҶдёҖдәӣй—®йўҳпјҢз”ҹжҲҗзҡ„дҝЎжҒҜиҷҪ然еӨҡж ·гҖҒдё°еҜҢпјҢдҪҶеҸӘиғҪдә§з”ҹиҫғй«ҳйў‘зҡ„еҶ…е®№пјҢеҜ№дәҺдҪҺйў‘зҡ„еҶ…е®№ж•Ҳжһңиҫғе·®гҖӮеӣ дёәеҜ№дәҺж°‘е®ҝжқҘиҜҙпјҢиҝҷжҳҜдёҖдёӘйқһж Үе“ҒпјҢеҰӮжһңжүҖжңүзҡ„ж–ҮжЎҲйғҪи®Іиҝ°зӣёеҗҢзҡ„еҶ…е®№пјҢ并дёҚиғҪжңүж•Ҳең°еҗёеј•е®ўжҲ·гҖӮеӣ жӯӨпјҢеңЁиҝҷеҹәзЎҖдёҠпјҢеёҢжңӣжЁЎеһӢиғҪеӨҹеҜ№йҪҗдәәзұ»зҡ„еҒҸеҘҪгҖӮеӣ жӯӨпјҢеңЁGPT2зҡ„еҹәзЎҖдёҠпјҢеҒҡдәҶ第дәҢйҳ¶ж®өзҡ„дјҳеҢ–пјҢе°Ҷе…¶еә”з”ЁдәҺз”ҹжҲҗд»»еҠЎгҖӮ
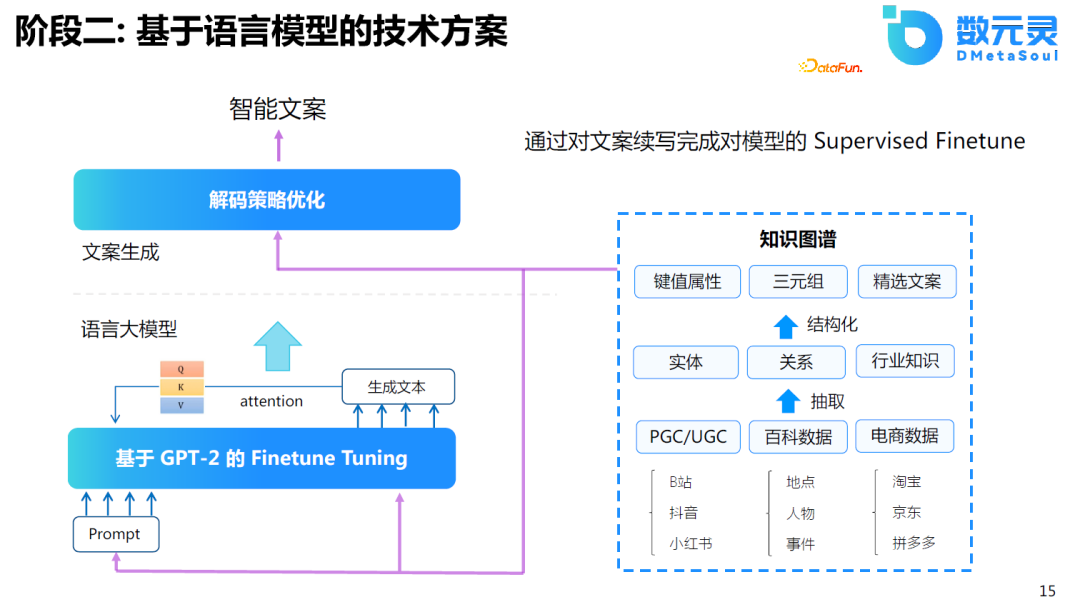
еҸ—йҷҗдәҺеҪ“ж—¶зҡ„и§ЈеҶіж–№жЎҲеҸҠз®—еҠӣзҡ„еҪұе“ҚпјҢж•ҲжһңдёҚеӨӘзҗҶжғігҖӮеӣ жӯӨпјҢеҸӮиҖғдәҶChatGPTзҡ„и®ӯз»ғж–№ејҸпјҢйҮҮз”Ёдёүйҳ¶ж®өиҝӣиЎҢи®ӯз»ғгҖӮйҰ–е…ҲпјҢ收йӣҶиҙЁйҮҸиҫғеҘҪзҡ„ж•°жҚ®пјҢеҜ№жЁЎеһӢиҝӣиЎҢеҫ®и°ғгҖӮе…¶ж¬ЎпјҢдҪҝз”ЁжЁЎеһӢз”ҹжҲҗж•°жҚ®ж ·жң¬пјҢ并еҜ№иҝҷдәӣж•°жҚ®иҝӣиЎҢжҺ’еәҸгҖӮжңҖеҗҺпјҢеҲ©з”ЁжҺ’еәҸе®Ңзҡ„ж•°жҚ®еҜ№жЁЎеһӢиҝӣиЎҢ第дәҢж¬Ўзҡ„еҫ®и°ғгҖӮеңЁи®ӯз»ғдёӨиҪ®еҗҺпјҢеҸ‘зҺ°жЁЎеһӢ收ж•ӣзҡ„ж•ҲжһңиҝҳжҜ”иҫғеҘҪгҖӮ
д»ҘдёӢжҳҜдёҖдәӣз»“жһңзҡ„CaseеҲҶжһҗпјҢеҜ№жҜ”дәҺGPT2зҡ„еҫ®и°ғжЁЎеһӢжқҘиҜҙпјҢж”№иҝӣеҗҺзҡ„ж–№жЎҲиғҪеӨҹиҜҶеҲ«зү№иүІеҚ–зӮ№пјҢ并且еңЁжҺ’еәҸдёҠиғҪеӨҹжӣҙеҠ зӘҒеҮәиҝҷз§ҚеҚ–зӮ№гҖӮиҝҷзӣёеҪ“дәҺжЁЎеһӢеҜ№йҪҗдәҶдәәзұ»зҡ„иҜ„дј°ж ҮеҮҶгҖӮ
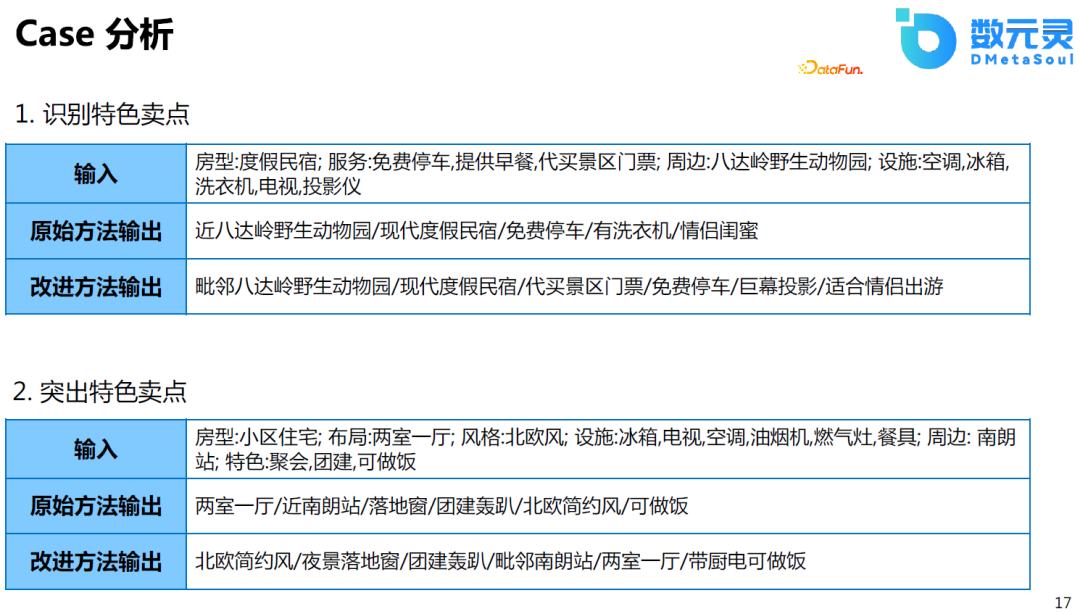
жҲ‘们зҡ„ж–№жі•йҰ–е…ҲжҳҜеҹәдәҺGPT2зҡ„жЁЎеһӢиҝӣиЎҢеҫ®и°ғпјҢжЁЎеһӢ规模иҫғе°ҸгҖӮе…¶ж¬ЎпјҢжҲ‘们зҡ„д»»еҠЎжӣҙеҠ з®ҖеҚ•пјҢеҸӘйҷҗдәҺж–ҮжЎҲзҡ„з”ҹжҲҗгҖӮеңЁз¬¬дёҖйҳ¶ж®өпјҢChatGPTйҮҮз”Ёдәәе·Ҙж ҮжіЁзҡ„ж–№ејҸпјҢжҲ‘们зҡ„ж–№жЎҲйҖүз”Ёзҡ„жҳҜзІҫйҖүж•°жҚ®йӣҶпјҢеӣ дёәжҲ‘们зҡ„еңәжҷҜпјҢеҸҜд»Ҙжӣҙй«ҳж•Ҳзҡ„иҺ·еҸ–зӣ‘зқЈж•°жҚ®пјҢеӣ жӯӨиҜҘйҳ¶ж®өж— йңҖдәәе·Ҙж ҮжіЁгҖӮеңЁз¬¬дәҢйҳ¶ж®өпјҢд№ҹеҹәдәҺpair-wiseжҚҹеӨұи®ӯз»ғдәҶrankingзҡ„жЁЎеһӢгҖӮеңЁз¬¬дёүйҳ¶ж®өпјҢеҹәдәҺеӨ§и§„жЁЎзҡ„ж•°жҚ®ж ҮзӯҫиҝӣиЎҢдёӨиҪ®еҫ®и°ғгҖӮ
03
е•Ҷе“ҒеӣҫеғҸз”ҹжҲҗ
1.дёәд»Җд№ҲйңҖиҰҒAIз”ҹжҲҗдә§е“ҒеӣҫзүҮ
еңЁз”өе•ҶйўҶеҹҹпјҢеӣҫзүҮжҳҜйқһеёёйҮҚиҰҒзҡ„пјҢдҪҶжҳҜе®һйҷ…зҡ„жӢҚж‘„иҝҮзЁӢжҳҜйқһеёёеӨҚжқӮзҡ„пјҢжҲҗжң¬д№ҹжҜ”иҫғй«ҳпјҢдҪҶдә§е“Ғзҡ„иҝӯд»Јж—¶й—ҙеҚҙжҜ”иҫғзҹӯпјҢеҜ№еӣҫзүҮжңүеӨ§йҮҸзҡ„дјҳеҢ–зҡ„йңҖжұӮгҖӮеҹәдәҺAIпјҢд»ҘзӣёеҜ№з®ҖеҚ•зҡ„ж–Үжң¬зәҰжқҹзҡ„ж–№ејҸпјҢз”ҹжҲҗдә§е“ҒеӣҫзүҮпјҢзү№еҲ«жҳҜеҜ№дәҺжңҚйҘ°дә§дёҡпјҢеҸҜд»ҘеӨ§йҮҸзј©зҹӯеӣҫзүҮз”ҹжҲҗзҡ„ж—¶й—ҙпјҢйҷҚдҪҺеҺҹжөҒзЁӢзҡ„ж—¶й—ҙгҖҒжҲҗжң¬гҖӮеӣ жӯӨпјҢжҲ‘们еңЁиҝҷдёӘж–№еҗ‘дёҠиҝӣиЎҢжҺўзҙўгҖӮ

йҰ–е…Ҳд»Ӣз»ҚйғЁеҲҶе…ідәҺж–Үжң¬з”ҹжҲҗеӣҫеғҸзҡ„дёҖдәӣе…·жңүйҮҢзЁӢзў‘ж„Ҹд№үзҡ„е·ҘдҪңгҖӮ2021е№ҙпјҢDALL-E 1зҡ„еҮәзҺ°е…·жңүеҲ’ж—¶д»Јзҡ„ж„Ҹд№үпјҢдҪҝеҫ—д»Һж–ҮеҲ°еӣҫзҡ„з”ҹжҲҗжЁЎеһӢе…·жңүе•ҶдёҡиҗҪең°зҡ„жҪңеҠӣгҖӮд№ӢеҗҺпјҢдёҚж–ӯжңүдәәеңЁиҝҷдёҖйўҶеҹҹиҝӣиЎҢз ”з©¶пјҢеҢ…жӢ¬DALL-E 2пјҢдёҚдҪҶе®һзҺ°дәҶж•Ҳжһңзҡ„жҸҗеҚҮпјҢиҝҳйҷҚдҪҺдәҶеҸӮж•°йҮҸгҖӮStable Diffusionзҡ„еҮәзҺ°д№ҹжҳҜзҹіз ҙеӨ©жғҠзҡ„дёҖйЎ№е·ҘдҪңпјҢдёҚдҪҶз”ҹжҲҗзҡ„ж•ҲжһңеҘҪпјҢиҖҢдё”еҸҜд»ҘеңЁж¶Ҳиҙ№зә§зҡ„жҳҫеҚЎдёҠе·ҘдҪңпјҢйҷҚдҪҺдәҶAIGCзҡ„й—Ёж§ӣгҖӮжңҖиҝ‘йқһеёёзҒ«зҲҶзҡ„LoRAжҠҖжңҜпјҢдёҚдҪҶеҸҜд»ҘеңЁж¶Ҳиҙ№зә§зҡ„жҳҫеҚЎдёҠдҪҝз”ЁпјҢиҝҳеҸҜд»ҘеҜ№жЁЎеһӢиҝӣиЎҢеҫ®и°ғпјҢжӣҙеҠ йҷҚдҪҺдәҶеҸӮдёҺзҡ„й—Ёж§ӣпјҢдҝғдҪҝеӨ§йҮҸзҡ„дәәе’Ңиө„жң¬ж¶Ңе…ҘиҝҷдёҖйўҶеҹҹгҖӮ

иҝҷйҮҢд»ҘдәәеғҸзӯүиҮӘеҠЁз”ҹжҲҗдёәдҫӢпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҡд»Һ21е№ҙзҡ„VQGAN-CLIPеҲ°Stable Diffusionзҡ„еҝ«йҖҹжј”иҝӣпјҢжҠҖжңҜжӯЈеңЁеҝ«йҖҹиҝӣжӯҘгҖӮиҖҢиҝ‘жңҹзҡ„ControlNetеҸҜд»Ҙж №жҚ®дәәзҡ„е§ҝеҠҝжҲ–зәҝе…үеӣҫзӣҙжҺҘз”ҹжҲҗз»“жһңпјҢиҝҷжӣҙжҳҜе…·еӨҮдәҶе•ҶдёҡиҗҪең°зҡ„еҸҜиғҪжҖ§гҖӮ

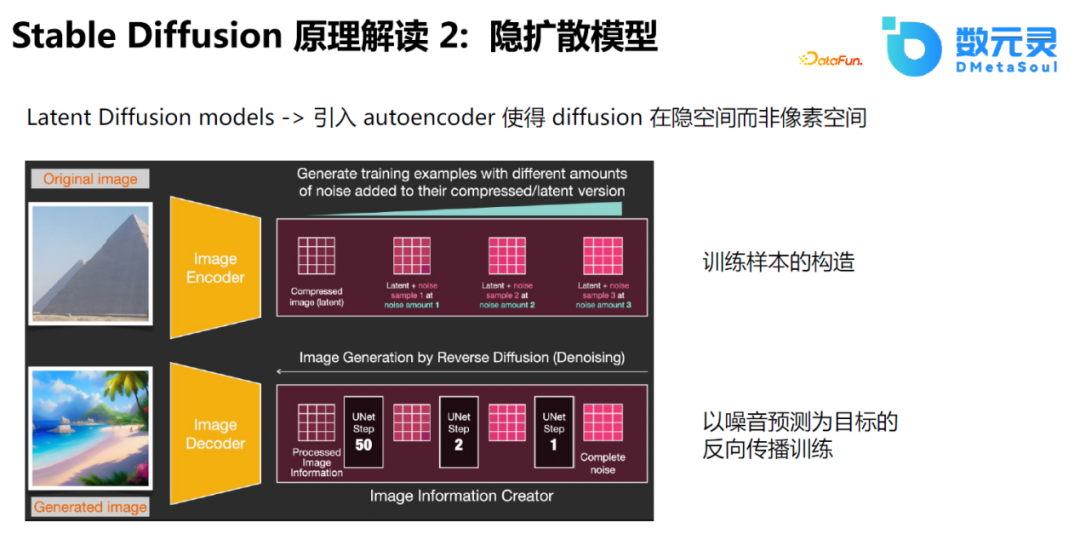
Stable Diffusionзҡ„жҖқи·ҜжҜ”иҫғз®ҖеҚ•пјҢзӣёеҪ“дәҺдҪҝз”ЁU-Netйў„жөӢеҷӘйҹіпјҢеҚідёҚж–ӯеңЁеҺҹеӣҫзҡ„еҹәзЎҖдёҠеўһеҠ еҷӘеЈ°пјҢе°ҶеёҰеҷӘйҹізҡ„ж•°жҚ®дҪңдёәиҫ“е…ҘпјҢдҪҝз”ЁU-Netйў„жөӢеҺҹе§ӢеӣҫеғҸеҸҠеҠ еҷӘеЈ°зҡ„иҝҮзЁӢгҖӮйҖҡиҝҮиҝҷз§ҚжЁЎејҸпјҢдҪҝйҖҡиҝҮеҷӘйҹіз”ҹжҲҗеӣҫеғҸз§°дёәеҸҜиғҪгҖӮ
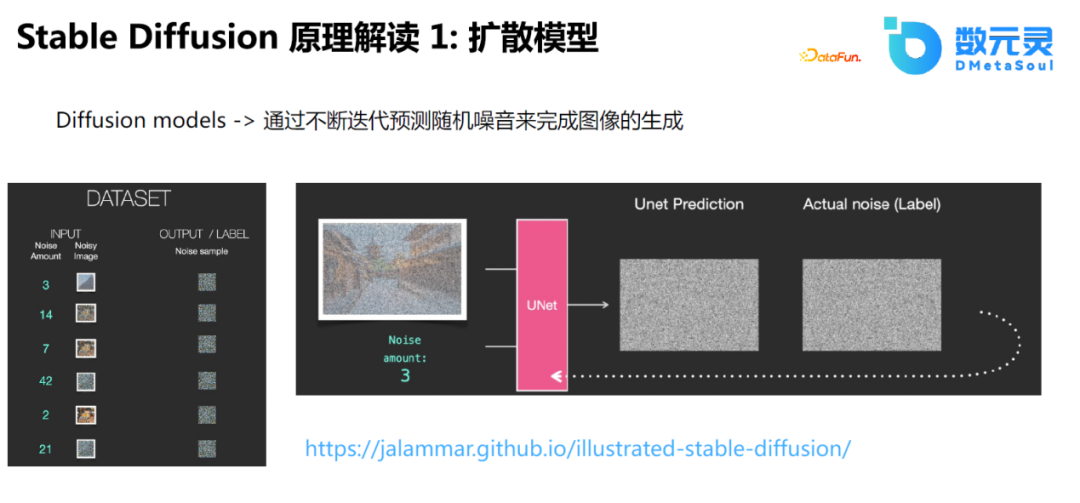
еңЁStable Diffusionзҡ„еҹәзЎҖдёҠпјҢиҝҳжҸҗеҮәдҪҝз”Ёйҡҗеҗ‘йҮҸзҡ„и®ӯз»ғж–№ејҸгҖӮеҺҹе…Ҳзҡ„DiffusionеҠ еҷӘйҹізҡ„иҝҮзЁӢдҪңз”ЁдәҺеӣҫзүҮпјҢеҚідёӯй—ҙиҝҮзЁӢе’ҢеҺҹе§ӢиҝҮзЁӢжҺҘиҝ‘гҖӮиҖҢйҡҗжү©ж•ЈжЁЎеһӢдҪҝз”ЁAuto Encoderе°Ҷдёӯй—ҙиҝҮзЁӢжҳ е°„еҲ°йҡҗз©әй—ҙдёӯпјҢиҝҷжңүеҲ©дәҺе°Ҷдёӯй—ҙиҝҮзЁӢиҝӣиЎҢйҷҚз»ҙи®Ўз®—пјҢеңЁй«ҳз»ҙз©әй—ҙиҝӣиЎҢи§Јз ҒпјҢиҝҷд№ҹжҳҜе®ғиғҪеӨҹж”ҜжҢҒеӨ§еҲҶиҫЁзҺҮеӣҫеғҸпјҢйҷҚдҪҺжҳҫеӯҳи®Ўз®—иө„жәҗзҡ„дё»иҰҒеҺҹеӣ гҖӮ
еҜ№дәҺж–Үеӯ—йғЁеҲҶзҡ„зј–з ҒпјҢStable Diffusionеј•е…ҘдәҶCLIPпјҢ并йҖҡиҝҮcross attentionзҡ„ж–№ејҸиһҚе…ҘжЁЎеһӢдёӯгҖӮдҪҝз”ЁCLIPеҜ№PromptиҝӣиЎҢзј–з ҒпјҢйҖҡиҝҮU-NetгҖҒcross attentionдҪңдёәжҺ§еҲ¶жқЎд»¶еј•еҜјеӣҫеғҸзҡ„з”ҹжҲҗиҝҮзЁӢгҖӮжҖ»зҡ„жқҘиҜҙпјҢStable DiffusionйҖҡиҝҮжһ„е»әLDMпјҢи§ЈеҶідәҶзӣҙжҺҘеңЁй«ҳз»ҙз©әй—ҙиҝӣиЎҢи®Ўз®—еёҰжқҘзҡ„иө„жәҗж¶ҲиҖ—е’ҢзІҫеәҰжҺ§еҲ¶зҡ„йҷҗеҲ¶пјҢ并且еҸ–еҫ—дәҶйқһеёёеҘҪзҡ„ж•ҲжһңгҖӮжңҖе…ій”®зҡ„жҳҜпјҢж•ҙдёӘз»“жһ„еҸҜд»ҘеңЁж¶Ҳиҙ№зә§зҡ„жҳҫеҚЎдёҠиҝӣиЎҢдҪҝз”ЁпјҢжһҒеӨ§ең°дҝғиҝӣдәҶAIGCиЎҢдёҡзҡ„еҸ‘еұ•гҖӮ
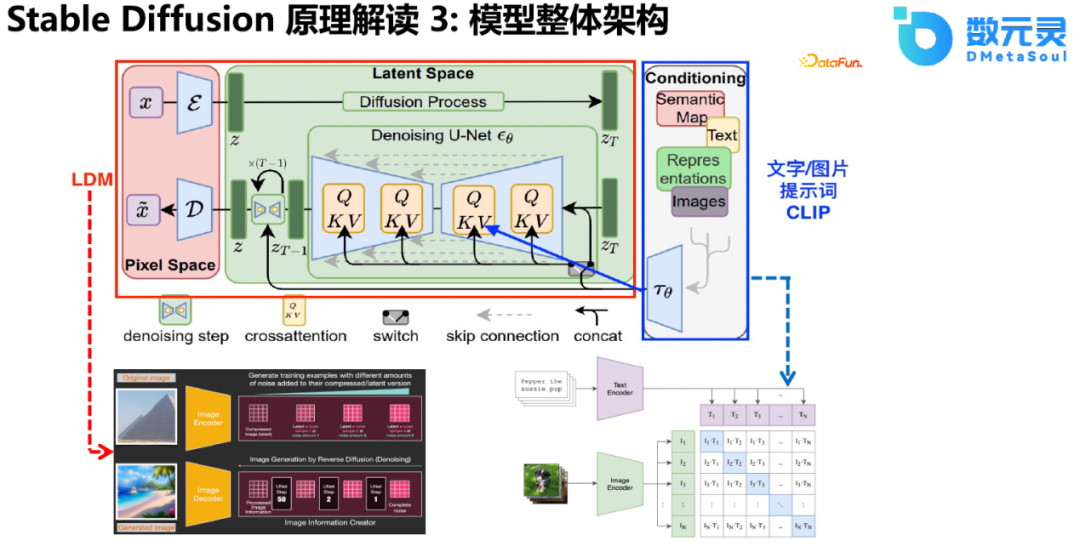
еңЁStable Diffusionд№ӢеҗҺпјҢжңҖиҝ‘д№ҹжңүи®ёеӨҡзӣёе…іе·ҘдҪңзҡ„иҝӯд»ЈпјҢеҢ…жӢ¬Textual InversionгҖҒDreamBoothгҖҒControlNetе’ҢLoRAпјҢиҝҷдәӣжЁЎеһӢдҪҝеҫ—з”ҹжҲҗзҡ„еӣҫеғҸжӣҙеҠ йҖјзңҹпјҢ并且用жҲ·еҸҜд»ҘжҸҗдҫӣжӣҙеӨҡзҡ„жҺ§еҲ¶жқЎд»¶пјҢеҫ®и°ғи®ӯз»ғзҡ„йҖҹеәҰжӣҙеҝ«пјҢеҫ®и°ғзҡ„еҸӮж•°йҮҸжӣҙе°‘пјҢйңҖиҰҒзҡ„жҳҫеӯҳжӣҙе°‘гҖӮ

8.AIВ WriterеӣҫзүҮз”ҹжҲҗеұ•зӨә
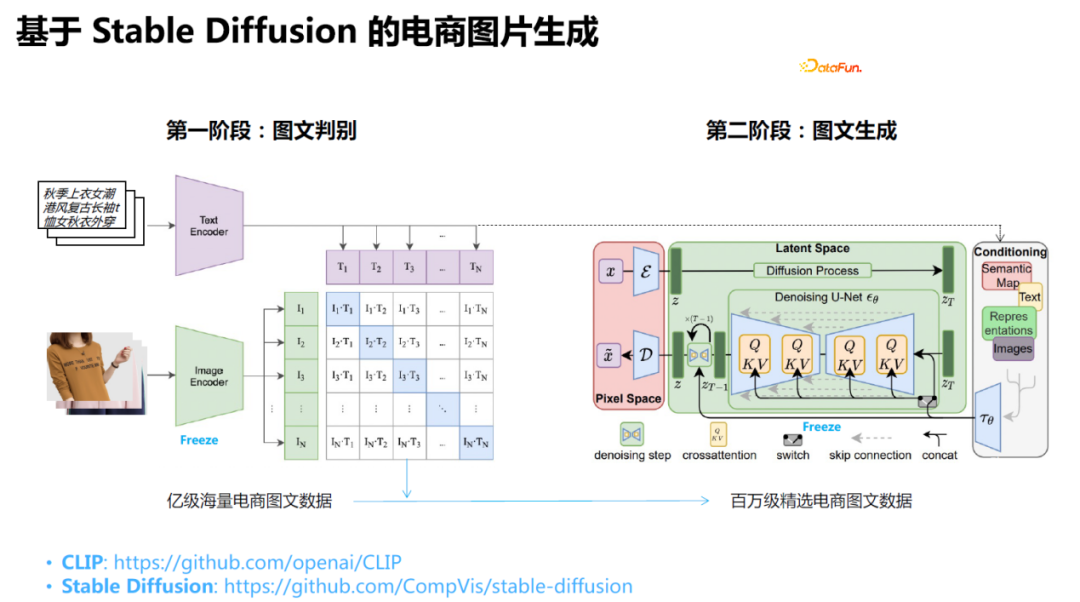
жҲ‘们еңЁиҝҷж–№йқўзҡ„е·ҘдҪңдё»иҰҒйӣҶдёӯеңЁз”өе•Ҷзҡ„еӣҫзүҮз”ҹжҲҗпјҢеҰӮжҸҗдҫӣдёҖдәӣе•Ҷе“Ғзҡ„д№°зӮ№е…ій”®иҜҚпјҢ然еҗҺз”ұжЁЎеһӢиҮӘеҠЁз”ҹжҲҗзӣёеә”зҡ„еӣҫзүҮгҖӮ

е…·дҪ“еҒҡжі•жҳҜпјҡйҮҮж ·Stable DiffusionжЁЎеһӢиҝӣиЎҢеҫ®и°ғпјҢдё»иҰҒеҫ®и°ғCLIPйғЁеҲҶгҖӮйҰ–е…ҲзҲ¬еҸ–з”өе•Ҷж•°жҚ®пјҢеңЁжӯӨеҹәзЎҖдёҠпјҢйҖҡиҝҮз”ЁжҲ·зҡ„иҜ„и®әж•°йҮҸгҖҒ收и—Ҹж•°йҮҸгҖҒжҲҗдәӨзӯүдҝЎжҒҜиҝӣиЎҢзӯӣйҖүпјҢ然еҗҺпјҢдҪҝз”ЁCLIPеҜ№иҝҷдәӣеҶ…е®№иҝӣиЎҢжү“еҲҶпјҢдҝқз•ҷж Үйўҳе’ҢеӣҫзүҮзӣёе…іеәҰиҫғй«ҳзҡ„ж•°жҚ®дҪңдёәи®ӯз»ғйӣҶиҝӣиЎҢи®ӯз»ғгҖӮ
еҺҹе§Ӣзҡ„з”өе•ҶжңҚйҘ°дә§е“ҒеӣҫзүҮеҲ¶дҪңжөҒзЁӢеҢ…жӢ¬пјҡж‘„еҪұеёҲжӢҚз…§пјҢжЁЎзү№ж‘ҶжӢҚпјҢзҫҺе·ҘеҗҺжңҹеӨ„зҗҶгҖҒдәӨд»ҳзӯүпјҢдҪҝз”ЁжЁЎеһӢиҝӣиЎҢеӣҫзүҮз”ҹжҲҗпјҢеҸҜд»Ҙе…ҚеҺ»жЁЎзү№гҖҒж‘„еҪұеёҲжҲҗжң¬пјҢеҸҜд»Ҙж №жҚ®иҝҗиҗҘйңҖжұӮеҸҠж—¶и°ғж•ҙгҖӮ
з»ҸиҝҮжҲ‘们еҜ№еёӮеңәзҡ„и°ғз ”пјҢеҸ‘зҺ°з”өе•ҶиЎҢдёҡеҶ…еҜ№еӣҫзүҮзҙ жқҗзҡ„иҮӘеҠЁз”ҹжҲҗйңҖжұӮеҫҲеӨ§гҖӮдҪҶд»ҺжҠҖжңҜдёҠжқҘиҜҙпјҢзӣ®еүҚж•ҙдёӘеӣҫзүҮз”ҹжҲҗзҡ„е·ҘдҪңиҝҳеӨ„дәҺжҺўзҙўйҳ¶ж®өпјҢиҷҪ然жөҒзЁӢе·Із»Ҹжү“йҖҡпјҢдҪҶжҳҜеҜ№иҙЁйҮҸиҰҒжұӮиҫғй«ҳзҡ„еӣҫзүҮзҡ„з”ҹжҲҗиҝҳжңүдёҖе®ҡзҡ„еұҖйҷҗжҖ§гҖӮиҝҷдёӘйўҶеҹҹзҡ„иҝӣеұ•йқһеёёеҝ«пјҢжҲ‘们д№ҹеңЁдёҚж–ӯзҡ„еҗёеҸ–з»ҸйӘҢпјҢдёҚж–ӯиҝӯд»ЈдјҳеҢ–пјҢе°ұзӣ®еүҚиҖҢиЁҖпјҢе°ҸеӣҫгҖҒжҰӮеҝөеӣҫгҖҒзј©з•Ҙеӣҫзҡ„з”ҹжҲҗз»“жһңиҫғеҘҪпјҢй«ҳжё…еӨ§еӣҫиҝҳеҫҲйҡҫдёҖж¬ЎжҲҗзүҮгҖӮ
04
з»“иҜӯ
ж–Үз« ејҖеӨҙеӣһйЎҫдәҶиҝ‘жңҹж–Үжң¬гҖҒеӣҫеғҸзӯүзӣёе…ійўҶеҹҹзҡ„йҮҚиҰҒе·ҘдҪңпјҢи®Ёи®әдәҶеӨ§жЁЎеһӢеңЁз”өе•ҶйўҶеҹҹеёҰжқҘж–°зҡ„жңәйҒҮдёҺжҢ‘жҲҳпјӣйҡҸеҗҺпјҢжҲ‘们д»Ӣз»ҚдәҶж•°е…ғзҒөеңЁз”өе•Ҷж–ҮжЎҲз”ҹжҲҗеҹәдәҺGPT жЁЎеһӢзҡ„е®һи·өпјҢеҜ№жҜ”дёҚеҗҢзүҲжң¬зҡ„жЁЎеһӢзҡ„иҝӯд»Јж•Ҳжһң并иҝӣиЎҢдәҶеҲҶжһҗпјӣжңҖеҗҺпјҢд»Ӣз»ҚдәҶж•°е…ғзҒөеңЁз”өе•ҶеӣҫеғҸз”ҹжҲҗеҹәдәҺStable Diffusion зҡ„е®һи·өгҖӮ
AIGCзӣ®еүҚзҡ„еҸ‘еұ•йҖҹеәҰеҫҲеҝ«пјҢжңӘжқҘжҲ‘们д№ҹеҸҜиғҪеҹәдәҺжңҖж–°зҡ„жҠҖжңҜиҝӣеұ•иҝӣдёҖжӯҘиҝӯд»ЈжЁЎеһӢгҖӮж–°жҠҖжңҜеҫ—еҮәзҺ°пјҢи®©д»ҘеүҚеҸҜиғҪйңҖиҰҒйқһеёёеӨ§и®Ўз®—иө„жәҗжүҚиғҪеҒҡзҡ„дә§е“ҒпјҢзҺ°еңЁеҸҜиғҪдёҚйңҖиҰҒйӮЈд№ҲеӨҡиө„жәҗд№ҹиғҪеҗҜеҠЁгҖӮ

дёӢйқўи°ҲдёҖдёӢй’ҲеҜ№з”өе•ҶйўҶеҹҹпјҢAIGCеҸҜиғҪдјҡеёҰжқҘд»ҘдёӢеҸҳйқ©пјҡ
еҜјиҙӯй“ҫи·ҜпјҡжҜ”еҰӮе’ҢOpenAIеҗҲдҪңзҡ„ShopпјҢд»ҘеҜ№иҜқзҡ„еҪўејҸиҝӣиЎҢдәӨдә’пјҢе®ўжҲ·жҸҗеҮәжғіжі•гҖҒйңҖжұӮпјҢжЁЎеһӢжҺЁиҚҗдёҚеҗҢзҡ„дә§е“ҒпјҢж–°зҡ„жҠҖжңҜеҮәзҺ°и®©иҝҷз§Қдә§е“ҒдәӨдә’жЁЎејҸжҲҗдёәеҸҜиғҪгҖӮ
еҲ¶йҖ е’Ңдҫӣеә”й“ҫпјҡиҷҪ然еҜ№дәҺиҙЁйҮҸиҫғй«ҳзҡ„еӣҫзүҮз”ҹжҲҗпјҢзӣ®еүҚзҡ„жҠҖжңҜиҝҳдёҚиғҪе®һзҺ°гҖӮдҪҶеҜ№дәҺеҲ¶йҖ ж–№еҗ‘пјҢеҰӮCALAеҸҜд»Ҙз”ҹжҲҗи®ҫи®ЎеӣҫпјҢиҝҷиғҪеӨҹйҷҚдҪҺжңҚиЈ…и®ҫи®Ўзҡ„й—Ёж§ӣпјҢйҷҚдҪҺи®ҫи®Ўзҡ„жҲҗжң¬гҖӮ
иҝҗиҗҘж•ҲзҺҮпјҡеҰӮAI WriterеҸҜд»ҘиҮӘеҠЁз”ҹжҲҗеӨҡжқЎиҝҗиҗҘж–ҮжЎҲпјҢиҝҗиҗҘеҗҢеӯҰеҸҜд»Ҙи°ғж•ҙз”ҹжҲҗзҡ„еӣ еӯҗпјҢжҢ‘йҖүеҗҲйҖӮзҡ„ж–ҮжЎҲгҖӮиҝҷз§Қж–№ејҸиғҪеӨҹйҷҚдҪҺиҝҗиҗҘжҲҗжң¬пјҢжҸҗй«ҳиҝҗиҗҘж•ҲзҺҮгҖӮжҜ•з«ҹйҖүжӢ©йўҳиҰҒжҜ”дё»и§ӮйўҳеҒҡиө·жқҘе®№жҳ“еҫ—еӨҡгҖӮ
дёӢеӣҫдёӯзҡ„зҪ‘з«ҷз»ҷеҮәдәҶи®ёеӨҡзҡ„еӨ§жЁЎеһӢеә”з”ЁеңәжҷҜпјҢдёҚд»…д»…еұҖйҷҗдәҺChatGPTпјҢиҝҳжңүBardзӯүгҖӮ

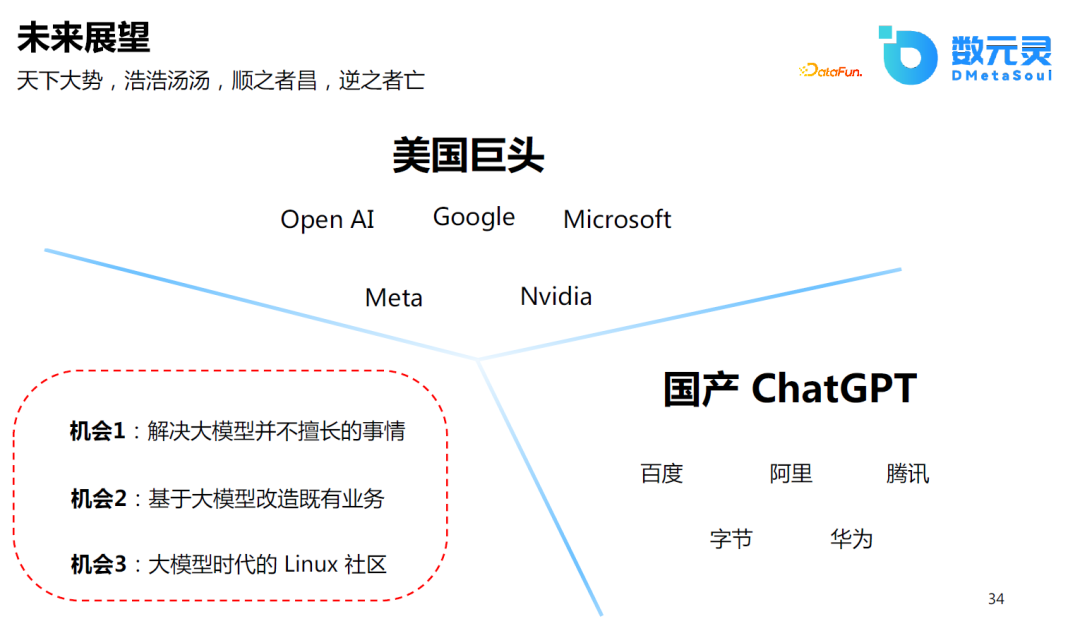
зӣ®еүҚпјҢеңЁеӣҪеҶ…еҒҡйҖҡз”ЁеӨ§жЁЎеһӢжҲ–еӣҪдә§зҡ„ChatGPTеҸҜиғҪ并дёҚжҳҜдёҖдёӘжңҖдјҳзҡ„йҖүжӢ©пјҢеӣ дёәиҝҷйңҖиҰҒеӨ§йҮҸзҡ„з§ҜзҙҜпјҢеҜ№дәҺжҲ‘们жҷ®йҖҡеҲӣдёҡиҖ…е’ҢејҖеҸ‘е·ҘзЁӢжқҘиҜҙпјҢеҸҜиғҪдјҡжңүд»ҘдёӢжңәдјҡпјҡ
и§ЈеҶіеӨ§жЁЎеһӢ并дёҚж“…й•ҝзҡ„дәӢжғ…пјҢеҰӮеӨ„зҗҶй•ҝж–Үжң¬пјҢжӣҙеҸҠж—¶ең°зҹҘиҜҶзҡ„жӣҙж–°зӯүпјӣ
еҹәдәҺеӨ§жЁЎеһӢж”№йҖ ж—ўжңүдёҡеҠЎпјҢеҢ…жӢ¬з”өе•ҶиЎҢдёҡжҲ–е…¶д»–иЎҢдёҡпјҢеҸҜиғҪжҜҸдёӘиЎҢдёҡеңЁиҝҷдёӘж—¶д»ЈйғҪдјҡйҮҚж–°еҒҡдёҖйҒҚпјӣ
еӨ§жЁЎеһӢж—¶д»Јзҡ„LinuxзӨҫеҢәпјҢзӣ®еүҚејҖжәҗзӨҫеҢәе·Із»ҸжҳҜйҒҚең°ејҖиҠұзҡ„зҠ¶жҖҒпјҢеӨ§иҜӯиЁҖжЁЎеһӢзҡ„iPhoneж—¶еҲ»е·ІиҝҮпјҢзӣёдҝЎAndroidж—¶еҲ»жңӘиҝңд№ҹпјҒ

05
Q&A
A:В иҝҷйңҖиҰҒж №жҚ®жЁЎеһӢзҡ„еӨ§е°ҸжқҘзЎ®е®ҡпјҢе°ұзӣ®еүҚжқҘзңӢпјҢеҰӮжһңжЁЎеһӢзҡ„еҸӮж•°е°ҸдәҺ100дәҝпјҢдёҚеӨӘеҸҜиғҪеҮәзҺ°йҖҡз”Ёзҡ„иғҪеҠӣпјҢеҜ№дәҺдё–з•ҢзҹҘиҜҶжҲ–жҢҮд»Өзҡ„зҗҶи§ЈгҖҒжҺЁзҗҶиғҪеҠӣжҜ”иҫғе·®пјҢиҮіе°‘еҸҜиғҪйңҖиҰҒ60-70дәҝеҸӮж•°зҡ„жЁЎеһӢжүҚдјҡйҖҗжёҗеҮәзҺ°иҝҷз§ҚйҖҡз”Ёзҡ„иғҪеҠӣгҖӮ
Aпјҡиҝҷд№ҹжҳҜжҲ‘们жӯЈеңЁеҒҡзҡ„дәӢжғ…пјҢзӣ®еүҚжҳҜйҖҡиҝҮPromptеј•еҜјжЁЎеһӢз”ҹжҲҗдёҚеҗҢйЈҺж јзҡ„ж–ҮжЎҲгҖӮеҸҰеӨ–пјҢеҸҜиғҪйңҖиҰҒдёҖдәӣжҠ–йҹігҖҒе°Ҹзәўд№ҰйЈҺж јзҡ„ж ҮжіЁж•°жҚ®пјҢеҶҚз”ҹжҲҗж—¶йҖҡиҝҮPromptеј•еҜјжЁЎеһӢгҖӮ
Aпјҡж–ҮжЎҲдёӯеҮәзҺ°е№»и§үжҲ–иҷҡеҒҮдҝЎжҒҜйғҪжҳҜеҸҜиғҪзҡ„гҖӮзӣ®еүҚзҡ„и§ЈеҶіж–№жЎҲжҳҜз”ҹжҲҗеӨҡдёӘеҖҷйҖүпјҢ然еҗҺиҝӣиЎҢеҗҺеӨ„зҗҶгҖӮ
AпјҡжңҖйҮҚиҰҒзҡ„еә”иҜҘжҳҜ收йӣҶй«ҳиҙЁйҮҸзҡ„ж•°жҚ®гҖӮе…¶ж¬ЎеҸҜиғҪжҳҜеҰӮдҪ•еҜ№жЁЎеһӢиҝӣиЎҢеҫ®и°ғгҖӮ
AпјҡиҝҷжҳҜеҸҜд»Ҙзҡ„пјҢд№ҹжҳҜжҲ‘们зӣ®еүҚжӯЈеңЁеҒҡзҡ„дәӢжғ…пјҢиҖҢдё”еҸӮж•°зҡ„规模еҸҜиғҪдёҚйңҖиҰҒйӮЈд№ҲеӨ§гҖӮ
AпјҡиҝҷжҳҜеҸҜд»Ҙзҡ„гҖӮ
AпјҡеҰӮжһңжҳҜеҫ®и°ғжЁЎеһӢпјҢ8еқ—A100иӮҜе®ҡжҳҜеҸҜд»Ҙзҡ„гҖӮеҰӮжһңжІЎжңүA100пјҢV100д№ҹжҳҜеҸҜд»Ҙзҡ„гҖӮе…·дҪ“зҡ„и®ҫеӨҮиҰҒжұӮе’ҢжЁЎеһӢеҸӮж•°йҮҸгҖҒж•°жҚ®йҮҸгҖҒи®ӯз»ғж—¶й•ҝйғҪжңүе…ізі»пјҢйңҖиҰҒе…·дҪ“жғ…еҶөе…·дҪ“еҲҶжһҗгҖӮ
Aпјҡhugging faceдёҠеә”иҜҘжңүеҫҲеӨҡдёӯж–Үзҡ„еӨ§жЁЎеһӢеҸҜд»ҘдҪҝз”ЁгҖӮ
Aпјҡиҝҷд№ҹжҳҜжҲ‘们ејҖе§Ӣе°қиҜ•ж—¶йҒҮеҲ°зҡ„й—®йўҳгҖӮеңЁж №жҚ®е•Ҷе“ҒеұһжҖ§з”ҹжҲҗеӣҫзүҮж—¶пјҢж•ҲжһңдёҚзҗҶжғігҖӮжҲ‘们зҡ„и§ЈеҶіж–№жЎҲжҳҜйҰ–е…Ҳе°Ҷе•Ҷе“Ғж•°жҚ®иҝӣиЎҢеҪ’дёҖеҢ–еӨ„зҗҶпјҢе…¶ж¬ЎпјҢе°ҶжҜ”иҫғзЁҖз–Ҹзҡ„еұһжҖ§иҝҮж»ӨпјҢеҰӮдҪҝз”ЁTF-IDFжҢ‘йҖүеҮәйҮҚиҰҒзҡ„еұһжҖ§зӯүгҖӮиҝҷдёӘй—®йўҳдё»иҰҒжқҘжәҗдәҺж•°жҚ®иҙЁйҮҸгҖӮ
Aпјҡзӣ®еүҚжҜ”иҫғйҡҫзҡ„еә”иҜҘжҳҜи§Ҷйў‘з”ҹжҲҗзҡ„йўҶеҹҹгҖӮMetaжҸҗеҮәзҡ„Make-A-Videoд№ҹеҸӘиғҪз”ҹжҲҗдёҖдәӣзҹӯи§Ҷйў‘пјҢиҖҢдё”иҙЁйҮҸд№ҹдёҚзҗҶжғігҖӮй«ҳеҲҶиҫЁеӣҫзүҮдёӯз»ҶиҠӮзҡ„йғЁдҪҚз”ҹжҲҗзҡ„ж•Ҳжһңд№ҹжҳҜдёҖдёӘйҡҫйўҳгҖӮ
AпјҡзҗҶи®әдёҠиҜҙпјҢдјҡиҜқзҡ„жЁЎејҸеҸҜд»Ҙи§ЈеҶіжүҖжңүе’Ңе•Ҷ家гҖҒе®ўжҲ·жІҹйҖҡзҡ„дәӢжғ…пјҢиҝҷйғҪжҳҜChatGPTиғҪеӨҹи§ЈеҶізҡ„дәӢжғ…гҖӮжҜ”еҰӮпјҢзӣ®еүҚеӨ§еӨҡж•°зҡ„е®ўжңҚжңәеҷЁдәәйғҪжҳҜйҖҡиҝҮ规еҲҷжқҘе®һзҺ°зҡ„пјҢеңЁChatGPTеҗҺеҸҜд»ҘйҖҡиҝҮChatGPTе’ҢзҹҘиҜҶзӣёз»“еҗҲзҡ„ж–№ејҸжқҘе®Ңе–„гҖӮ
AпјҡBERTйҖҡеёёз”ЁдәҺеҲҶзұ»гҖҒе®һдҪ“иҜҶеҲ«зӯүиҜҶеҲ«зұ»д»»еҠЎгҖӮGPTеҸҜиғҪжӣҙж“…й•ҝз”ҹжҲҗзұ»зҡ„д»»еҠЎгҖӮеҸҜд»ҘеңЁBERTжңҖеҗҺдёҖеұӮжҺҘдёҠдёҚеҗҢзҡ„д»»еҠЎеұӮпјҢеҒҡиҜҶеҲ«зұ»зҡ„д»»еҠЎпјҢеҰӮдә®зӮ№иҜҶеҲ«зӯүгҖӮ
AпјҡиҝҷйңҖиҰҒж №жҚ®йңҖжұӮжқҘзЎ®е®ҡгҖӮеҰӮжө·еӨ–з”өе•ҶйҖҡеёёдҪҝз”ЁйӮ®д»¶иҝӣиЎҢдәӨжөҒпјҢиҝҷд№ҹжҳҜдёҖдёӘиЎҢдёҡз—ӣзӮ№гҖӮдә§е“Ғи®ҫи®ЎеӣҫгҖҒжҰӮеҝөеӣҫзҡ„з”ҹжҲҗд№ҹжҳҜжҜ”иҫғеҘҪзҡ„ж–№еҗ‘гҖӮ
Aпјҡжңүзҡ„пјҢй“ҫжҺҘпјҡhttp://nlg-demo.dmetasoul.com/ecommerceгҖӮдҪҶжҳҜеӣ дёәз®—еҠӣзҡ„йҷҗеҲ¶пјҢйғЁзҪІз”Ёзҡ„жЁЎеһӢеҸӘжҳҜдёҖдёӘе°ҸжЁЎеһӢгҖӮ


еҲҶдә«еҳүе®ҫ
INTRODUCTION

еӯҷеҮҜ
ж•°е…ғзҒө
йҰ–еёӯ科еӯҰ家
дёӯ科йҷўж•°еӯҰжүҖеҚҡеЈ«пјҢе…ҲеҗҺе°ұиҒҢдәҺ IBMпјҢйҳҝйҮҢе·ҙе·ҙпјӣеңЁжңәеҷЁеӯҰд№ гҖҒжҺЁиҚҗзі»з»ҹгҖҒж—¶й—ҙеәҸеҲ—йў„жөӢзӯүж–№еҗ‘жӢҘжңүеӨҡе№ҙејҖеҸ‘е’ҢдјҳеҢ–з»ҸйӘҢгҖӮзӣ®еүҚеңЁеҢ—дә¬ж•°е…ғзҒө科жҠҖжңүйҷҗе…¬еҸёжӢ…д»»йҰ–еёӯ科еӯҰ家пјҢдё»иҰҒиҙҹиҙЈз®—жі•ж–№еҗ‘зҡ„з ”еҸ‘е·ҘдҪңгҖӮ
жӣҫеңЁйҳҝйҮҢе·ҙе·ҙйӣҶеӣўжӢ…д»»иө„ж·ұ算法专家пјҢе…ҲеҗҺеңЁйЈһзҢӘпјҢLazada йғЁй—ЁеёҰйўҶеӣўйҳҹеңЁжҺЁиҚҗзі»з»ҹгҖҒдҫӣеә”й“ҫдјҳеҢ–гҖҒе•ҶдёҡиөӢиғҪзӯүж–№еҗ‘иҝӣиЎҢж”»еқҡпјҢиҺ·еҫ—еӨ§е№…еәҰзҡ„дёҡеҠЎж•ҲжһңжҸҗеҚҮпјҢе…·жңүдё°еҜҢзҡ„з®—жі•иҗҪең°иөӢиғҪз»ҸйӘҢгҖӮ
зү№еҲ«иҜҙжҳҺпјҡжң¬ж–Үд»…з”ЁдәҺеӯҰжңҜдәӨжөҒпјҢеҰӮжңүдҫөжқғиҜ·еҗҺеҸ°иҒ”зі»е°Ҹзј–еҲ йҷӨгҖӮ
- END -
иҪ¬иҪҪжқҘжәҗпјҡDataFunTalk
иҪ¬иҪҪзј–иҫ‘пјҡжқҺеҖ©жҘ
е®Ўж ёпјҡзҺӢиҙҮВ е®ҒйқҷВ В з”°иҙқиҘҝВ В ж®өжҳҺиҙө


иө„и®ҜжҺЁиҚҗ

в–¶ жҠҖжңҜдёҺе·Ҙе…·
й«ҳзә§иҜ‘е‘ҳзҡ„з§ҳеҜҶжӯҰеҷЁвҖ”вҖ”иҜӯж–ҷеә“еӨ§е…ЁйӣҶ
еӣҪеҶ…еӨ–еёёи§ҒиҜӯж–ҷе·Ҙе…·дёҖи§Ҳ
еӣҪеҶ…еӨ–еёёи§ҒжңҜиҜӯз®ЎзҗҶе·Ҙе…·
зҝ»иҜ‘еҝ…еӨҮжңҜиҜӯеә“е’ҢиҜӯж–ҷеә“еҗҲйӣҶпјҲйҷ„зҪ‘еқҖпјү
зҝ»иҜ‘еҝ…еӨҮзҡ„и®Ўз®—жңәзҝ»иҜ‘иҫ…еҠ©иҪҜ件пјҲйҷ„зҪ‘еқҖпјү
AntConcпјҡе®һз”Ёзҡ„жң¬ең°иҜӯж–ҷеә“жЈҖзҙўе·Ҙе…·
TREXпјҡжңүжө·йҮҸдҫӢеҸҘгҖҒдё°еҜҢиҜӯж–ҷзҡ„еңЁзәҝиҜҚе…ё
NetspeakпјҡдёҖж¬ҫе…Қиҙ№зҡ„еҚ•иҜҚжҗӯй…ҚжЈҖзҙўе·Ҙе…·
WantWordsеҸҚеҗ‘иҜҚе…ёпјҢеҶ…еҗ«ејҖеҸ‘еӣўйҳҹе…¬ејҖж–ҮжЎЈ
Cymo BoothпјҡеҗҢеЈ°дј иҜ‘е‘ҳзҡ„дё“еұһиҷҡжӢҹеҗҢдј й—ҙ
MateCatпјҡдёҖж¬ҫе…Қиҙ№зҡ„еңЁзәҝCATе·Ҙе…·
VisuwordsпјҡеҸҜи§ҶеҢ–еңЁзәҝиҜҚе…ёпјҢеё®дҪ дёҖй”®жһ„йҖ и®°еҝҶе®«ж®ҝ
LinggleпјҡиҜӯж–ҷ+жҗӯй…ҚжЈҖзҙўе·Ҙе…·пјҲе®һж“Қжј”зӨәпјү
Ludwig: ең°йҒ“иӢұж–ҮеҶҷдҪңиҫ…еҠ©зҘһеҷЁпјҢе‘ҠеҲ«дёӯејҸиӢұиҜӯ
Reversoпјҡиҫ…еҠ©еҶҷдҪңдёҺзҝ»иҜ‘зҘһеҷЁ
в–¶ еӣҪйҷ…иҜӯиЁҖжңҚеҠЎеҠЁжҖҒ
| зҝ»иҜ‘е…¬еҸёзҜҮ | TransPerfectз®Җд»Ӣ
| зҝ»иҜ‘е…¬еҸёзҜҮ | е…Ёзҗғ第2еҗҚ RWSеҰӮж–ҮжҖқ
| зҝ»иҜ‘е…¬еҸёзҜҮ | вҖң收иҙӯзӢӮйӯ”вҖқKeywords Studios
| е’ЁиҜўжңәжһ„зҜҮ | Slator з®Җд»Ӣ
| е’ЁиҜўжңәжһ„зҜҮ | CSA Research з®Җд»Ӣ
| иЎҢдёҡжңәжһ„зҜҮ | еӣҪйҷ…зҝ»иҜ‘家иҒ”зӣҹFIT
| иЎҢдёҡжңәжһ„зҜҮ | зҫҺеӣҪзҝ»иҜ‘еҚҸдјҡATA
| иЎҢдёҡжңәжһ„зҜҮ | еҠ жӢҝеӨ§иҒ”йӮҰзҝ»иҜ‘еұҖ Canada's Translation Bureau
| зҝ»иҜ‘йҷўж ЎзҜҮ | жҳҺеҫ·еӨ§еӯҰи’ҷзү№йӣ·еӣҪйҷ…з ”з©¶еӯҰйҷўпјҲMIISпјү
| зҝ»иҜ‘йҷўж ЎзҜҮ | ж јжӢүж–Ҝе“ҘеӨ§еӯҰ
| зҝ»иҜ‘йҷўж ЎзҜҮ | еҹғеЎһе…Ӣж–ҜеӨ§еӯҰ
| зҝ»иҜ‘йҷўж ЎзҜҮ | еҲ©е…№еӨ§еӯҰ
| зғӯзӮ№иҝҪиёӘ | ChatGPTзҡ„дјҰзҗҶй—®йўҳпјҲдёҠпјү
|В зғӯзӮ№иҝҪиёӘ | ChatGPTзҡ„дјҰзҗҶй—®йўҳпјҲдёӢпјү
| зғӯзӮ№иҝҪиёӘ | GPT-4йқўдё–вҖ”вҖ”AIеј•йўҶиҜӯиЁҖиЎҢдёҡйқ©ж–°
в–¶ дё“и®ҝ
зҺӢеҚҺж ‘пјҡжңәеҷЁзҝ»иҜ‘е°ҶиҰҒеҸ–д»Јдәәе·Ҙзҝ»иҜ‘еҗ—пјҹ
еҙ”еҗҜдә®пјҡжңәеҷЁзҝ»иҜ‘еҜ№иҜӯиЁҖжңҚеҠЎдјҒдёҡжңүеӨҡеӨ§дҪңз”Ёпјҹ
йҹ©жһ—ж¶ӣпјҡж–Ү科з”ҹеҰӮдҪ•еӯҰд№ жңәеҷЁзҝ»иҜ‘пјҹ
йӯҸеӢҮй№ҸпјҡжңәеҷЁзҝ»иҜ‘иҙЁйҮҸиҜ„дј°дёәд»Җд№ҲйҮҚиҰҒпјҹ
еҫҗеҪ¬пјҡзҶҹз»ғжҺҢжҸЎзҝ»иҜ‘жҠҖжңҜпјҢе°ұиғҪеҒҡеҮәжјӮдә®зҡ„жҙ»е„ҝ
жӣ№йҰ–е…үпјҡеҰӮдҪ•жү“йҖ дёҖж¬ҫеҸ—ж¬ўиҝҺзҡ„жңәеҷЁзҝ»иҜ‘дә§е“ҒпјҹВ
жқҺжў…пјҡжңәеҷЁзҝ»иҜ‘еҜ№жңӘжқҘзҝ»иҜ‘ж•ҷиӮІжңүдҪ•еҪұе“Қпјҹ
е‘Ёе…ҙеҚҺпјҡй«ҳж Ўзҝ»иҜ‘ж•ҷеёҲеҰӮдҪ•еӯҰд№ зҝ»иҜ‘жҠҖжңҜпјҹ
дёҒдёҪпјҡиҜ‘еҗҺзј–иҫ‘дәәе‘ҳдёҺиҜ‘иҖ…иә«д»ҪжҳҜеҗҰеҜ№зӯүпјҹ
зҺӢе·Қе·Қпјҡз–«жғ…иғҢжҷҜдёӢиҝңзЁӢеҸЈиҜ‘зҡ„жҢ‘жҲҳе’Ңеә”еҜ№
еҚўе®¶иҫүгҖҒйҷҲжҷЁпјҡеҸЈиҜ‘е‘ҳеңЁиҝңзЁӢеҸЈиҜ‘дёӯйқўдёҙзҡ„дё»иҰҒй—®йўҳ
в–¶ иЎҢдёҡжҙһеҜҹ
2021е№ҙиҜӯиЁҖжңҚеҠЎиЎҢдёҡеӣһйЎҫдёҺеұ•жңӣ
2022е№ҙе…ЁзҗғзҷҫејәиҜӯиЁҖжңҚеҠЎе•ҶжҰңеҚ•
2022е№ҙзҝ»иҜ‘иЎҢдёҡе°ҶиҝҺжқҘе“Әдәӣж–°еҸҳеҢ–
еҗҺз–«жғ…ж—¶д»ЈпјҢиҜӯиЁҖжңҚеҠЎиЎҢдёҡеҰӮдҪ•еҸ‘еұ•иҪ¬еһӢпјҹ
дҪ•й’ҰпјҡдёӯеӣҪз”өеҪұеҜ№еӨ–иҜ‘д»Ӣзҡ„зҺ°зҠ¶дёҺжҖқиҖғ
еҶҜеҝ—дјҹпјҡе…ідәҺжңәеҷЁзҝ»иҜ‘иЎҢдёҡеҸ‘еұ•зҡ„дёүзӮ№е»әи®®
еј йң„еҶӣпјҡдјҰзҗҶи§Ҷи§’дёӢпјҢжңәеҷЁзҝ»иҜ‘зҡ„иғҪдёҺдёҚиғҪ
й»„еҸӢд№үпјҡеҰӮдҪ•зӘҒз ҙдёӯеӨ–ж–ҮеҢ–е·®ејӮпјҢи®©дё–з•ҢжӣҙдәҶи§ЈдёӯеӣҪпјҹ
в–¶ ж•ҷиӮІеҲӣж–°
жқҺй•ҝж “пјҡMTIи®әж–ҮеҚғзҜҮдёҖеҫӢпјҢеҰӮдҪ•з ҙеұҖпјҹ
зҺӢеҚҺж ‘ еҲҳдё–з•Ңпјҡж•°еӯ—дәәж–Үи§ҶеҹҹдёӢиҜ‘иҖ…ж•°еӯ—зҙ е…»з ”з©¶пјҡеҶ…ж¶өгҖҒй—®йўҳдёҺе»әи®®
зҺӢеҚҺж ‘ еҲҳдё–з•Ңпјҡдәәе·ҘжҷәиғҪж—¶д»Јзҝ»иҜ‘жҠҖжңҜиҪ¬еҗ‘з ”з©¶
зҺӢеҚҺж ‘ еҲҳдё–з•Ңпјҡжҷәж…§зҝ»иҜ‘ж•ҷиӮІз ”究: зҗҶеҝөгҖҒи·Ҝеҫ„дёҺи¶ӢеҠҝ
жӣ№иҫҫй’ҰВ жҲҙй’°ж¶өпјҡдәәе·ҘжҷәиғҪж—¶д»Јй«ҳж Ўзҝ»иҜ‘жҠҖжңҜе®һи·өзҺҜеўғе»әи®ҫз ”з©¶
жқҺжў…пјҡеҰӮдҪ•з»ҷвҖңжҠҖжңҜе°ҸзҷҪвҖқ ејҖи®ҫи®Ўз®—жңәиҫ…еҠ©зҝ»иҜ‘иҜҫзЁӢпјҹ
е®һи·өеҜјеҗ‘зҡ„MTIдәәжүҚеҹ№е…»жЁЎејҸвҖ”вҖ”д»ҘеҜ№еӨ–з»ҸжөҺиҙёжҳ“еӨ§еӯҰдёәдҫӢ
ж•°еӯ—еҢ–еҸЈиҜ‘ж•ҷеӯҰиө„жәҗе»әи®ҫпјҡ欧жҙІз»ҸйӘҢдёҺеҗҜзӨә
еҰӮдҪ•е°Ҷзҝ»иҜ‘йЎ№зӣ®з®ЎзҗҶжЁЎејҸеә”з”ЁеҲ°CATж•ҷеӯҰиҜҫе Ӯдёӯпјҹ

