




ж•°жҚ®йқһдҫқиө–йҮҮйӣҶпјҲDIAпјүиҙЁи°ұиӣӢзҷҪиҙЁз»„еӯҰдә§з”ҹеҸҜйҮҚеӨҚзҡ„иӣӢзҷҪиҙЁз»„ж•°жҚ®гҖӮжң¬з ”究иҜ„дј°дәҶдә”з§Қе·Ҙе…·пјҲOpenSWATHгҖҒEncyclopeDIAгҖҒSkylineгҖҒDIA-NNе’ҢSpectronautпјүеңЁTripleTOFгҖҒOrbitrapе’ҢTimsTOF Proд»ӘеҷЁдёҠдҪҝз”Ёе…ӯдёӘDIAж•°жҚ®йӣҶзҡ„жҖ§иғҪгҖӮйҖҡиҝҮжҜ”иҫғйүҙе®ҡе’Ңе®ҡйҮҸжҢҮж ҮпјҢд»ҘеҸҠи·Ёе·Ҙе…·йүҙе®ҡзҡ„е…ұдә«е’ҢзӢ¬зү№д№ӢеӨ„пјҢиҜ„дј°дәҶеҹәдәҺеә“е’Ңж— еә“ж–№жі•гҖӮз»“жһңжҳҫзӨәпјҢеҪ“е…үи°ұеә“дёҚеӨҹе…Ёйқўж—¶пјҢж— еә“ж–№жі•дјҳдәҺеҹәдәҺеә“зҡ„ж–№жі•гҖӮ然иҖҢпјҢжһ„е»әе…Ёйқўеә“еңЁеӨ§еӨҡж•°DIAеҲҶжһҗдёӯд»Қе…·жңүдјҳеҠҝгҖӮиҜҘз ”з©¶дёәDIAж•°жҚ®еҲҶжһҗе·Ҙе…·жҸҗдҫӣдәҶз»јеҗҲжҢҮеҜјпјҢжңүзӣҠдәҺDIA-MSжҠҖжңҜзҡ„жңүз»ҸйӘҢе’Ңж–°жүӢз”ЁжҲ·гҖӮ
з ”з©¶е·ҘдҪңжөҒзЁӢпјҢж¶үеҸҠеҲ©з”Ёз”ұдёүз§Қзұ»еһӢзҡ„иҙЁи°ұд»Әз”ҹжҲҗзҡ„е…ӯдёӘж•°жҚ®йӣҶ
з ”з©¶и®ҫи®ЎеҢ…жӢ¬дәҶеҹәдәҺеә“е’Ңж— еә“зҡ„дёӨз§Қж–№жі•пјҢ并йҮҮз”Ёз»Ҹе…ёзҡ„зӣ®ж Ү-дјӘзӣ®ж ҮйӘҢиҜҒе’Ңз»ҸйӘҢйӘҢиҜҒзӣёз»“еҗҲзҡ„ж–№ејҸжқҘиҜ„дј°е·Ҙе…·жҖ§иғҪгҖӮйҰ–е…ҲпјҢд»ҺдёҚеҗҢиҙЁи°ұд»Әз”ҹжҲҗзҡ„еӨҡзү©з§Қж•°жҚ®йӣҶиҝӣиЎҢеҲҶжһҗпјҢеҰӮTripleTOFгҖҒOrbitrapе’ҢTimsTOF ProпјҢиҰҶзӣ–дәҶдёҚеҗҢзұ»еһӢзҡ„е®һйӘҢж ·жң¬гҖӮе…¶ж¬ЎпјҢжҜ”иҫғдәҶе·Ҙе…·еңЁйүҙе®ҡе’Ңе®ҡйҮҸж–№йқўзҡ„иЎЁзҺ°пјҢеҢ…жӢ¬и·Ёе·Ҙе…·йүҙе®ҡзҡ„дёҖиҮҙжҖ§е’Ңе·®ејӮжҖ§пјҢд»ҘеҸҠеә“е’Ңж— еә“ж–№жі•зҡ„ж•ҲжһңгҖӮ
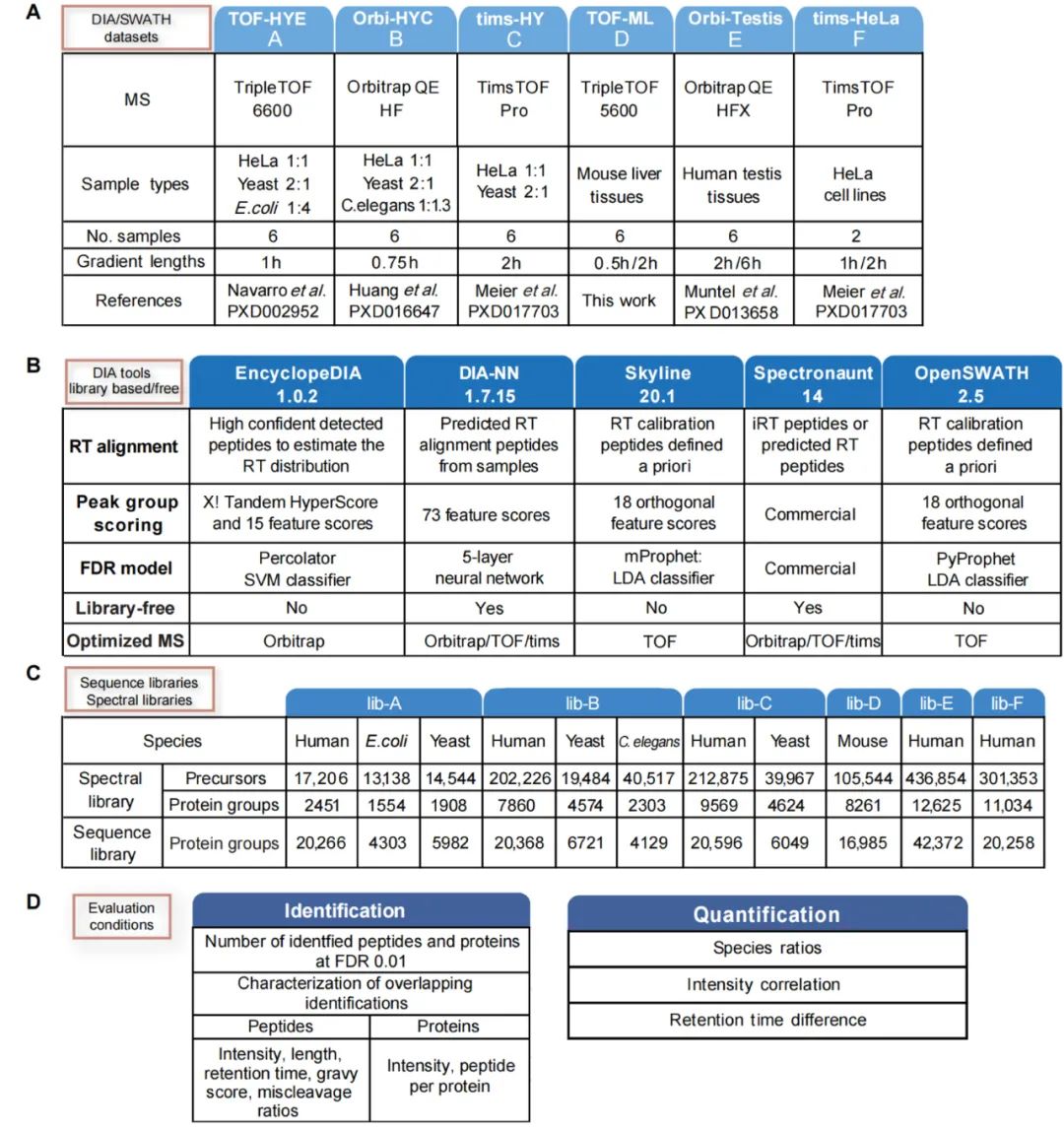
з ”з©¶з»ҶиҠӮВ В (A)з”ЁдәҺиҜ„дј°ж•°жҚ®еҲҶжһҗе·Ҙе…·зҡ„ DIA ж•°жҚ®йӣҶзҡ„иҜҰз»ҶдҝЎжҒҜпјӣ(B)еҜ№дәҺжҜҸдёӘж•°жҚ®йӣҶпјҢиҝҷйҮҢиҜҰз»Ҷд»Ӣз»ҚдәҶе®ғ们зҡ„е…үи°ұеә“е’ҢеәҸеҲ—еә“зҡ„з»„жҲҗпјӣ(C) дёүдёӘдё»иҰҒж–№йқўеҢ…еҗ«дәҶжҲ‘们иҜ„дј°зҡ„ DIA ж•°жҚ®еҲҶжһҗе·Ҙе…·зҡ„жңҖзӣёе…ізү№еҫҒпјҡRTжҜ”еҜ№гҖҒеі°з»„иҜ„еҲҶе’Ң FDR жЁЎеһӢпјӣ(D) з”ЁдәҺиҜ„дј°иҜҶеҲ«е’ҢйҮҸеҢ–з»“жһңзҡ„жҢҮж Үзҡ„иҜҰз»ҶдҝЎжҒҜгҖӮ
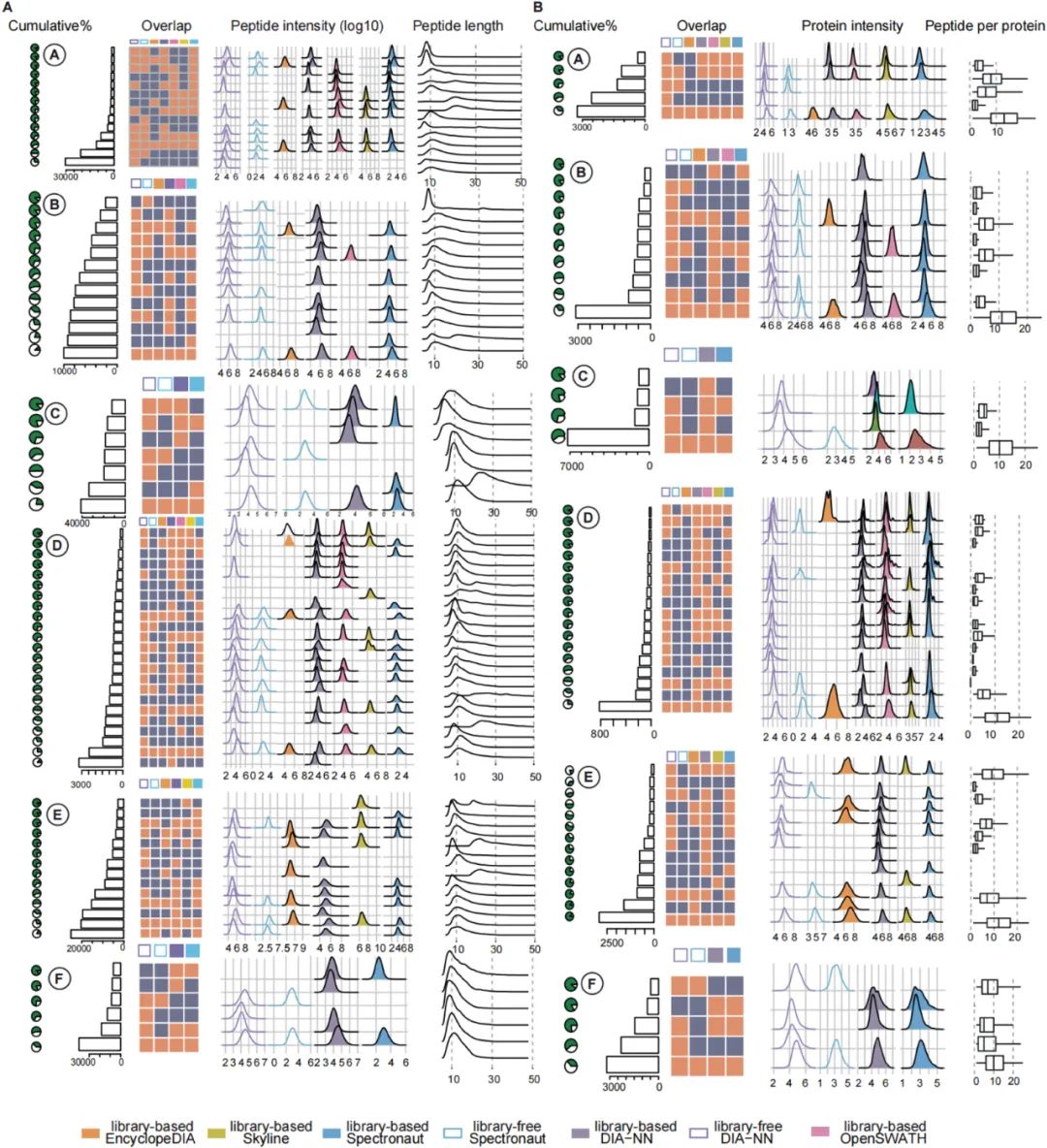
з ”з©¶з»“жһңжҳҫзӨәпјҢDIA-NNеңЁйүҙе®ҡж•°йҮҸж–№йқўжҳҺжҳҫдјҳдәҺе…¶д»–е·Ҙе…·пјҢе…¶йүҙе®ҡж•°йҮҸи¶…иҝҮ第дәҢеҗҚе·Ҙе…·Spectronaut 59.6%иҮі33.5%гҖӮSpectronautеңЁдёҖдәӣж•°жҚ®йӣҶдёӯиЎЁзҺ°еҮәиүІпјҢEncyclopeDIAеңЁзү№е®ҡж•°жҚ®йӣҶдёҠжҖ§иғҪиҫғеҘҪпјҢиҖҢOpenSWATHе’ҢSkylineеңЁжҹҗдәӣж•°жҚ®йӣҶдёҠд№ҹеҸ–еҫ—дәҶиүҜеҘҪзҡ„жҲҗз»©гҖӮеә“е’Ңж— еә“ж–№жі•зҡ„жҜ”иҫғиЎЁжҳҺпјҢеңЁеә“иҫғе°Ҹзҡ„жғ…еҶөдёӢпјҢж— еә“ж–№жі•еҸҜд»ҘдјҳдәҺеә“ж–№жі•пјҢдҪҶжҳҜеңЁеӨ§еӨҡж•°жғ…еҶөдёӢпјҢжһ„е»әе…Ёйқўзҡ„еә“д»Қ然具жңүдјҳеҠҝгҖӮ
жӯӨеӨ–пјҢз ”з©¶иҝҳиҜ„дј°дәҶдёҚеҗҢе·Ҙе…·д№Ӣй—ҙзҡ„дәӨеҸүдёҖиҮҙжҖ§пјҢеҸ‘зҺ°е®ғ们еңЁйүҙе®ҡе’Ңе®ҡйҮҸж–№йқўзҡ„з»“жһңе…·жңүй«ҳеәҰзҡ„дёҖиҮҙжҖ§гҖӮжӯӨеӨ–пјҢиҝҳз ”з©¶дәҶеҹәдәҺеә“е’Ңж— еә“зҡ„жҗңзҙўзӯ–з•Ҙд»ҘеҸҠе…¬е…ұеә“е’Ңж··еҗҲеә“зҡ„дҪҝз”ЁпјҢдёәз”ЁжҲ·жҸҗдҫӣдәҶе…Ёйқўзҡ„жҖ§иғҪжҜ”иҫғгҖӮз ”з©¶иҝҳжҸҗдҫӣдәҶдёҖдёӘз»ҹдёҖзҡ„ж јејҸе’ҢжҜ”иҫғе№іеҸ°пјҢз”ЁдәҺж ҮеҮҶеҢ–е’Ңи§ЈйҮҠдёҚеҗҢе·Ҙе…·з”ҹжҲҗзҡ„з»“жһңгҖӮ
然иҖҢпјҢз ”з©¶д№ҹеӯҳеңЁдёҖдәӣеұҖйҷҗжҖ§пјҢдҫӢеҰӮж•°жҚ®йӣҶзҡ„йҖүжӢ©иҫғдёәжңүйҷҗпјҢе®һйҷ…ж ·жң¬зҡ„еӨҚжқӮжҖ§еҸҜиғҪжңӘиғҪе®Ңе…Ёж¶өзӣ–гҖӮжӯӨеӨ–пјҢз”ұдәҺиҪҜ件е·Ҙе…·дёҚж–ӯжӣҙж–°пјҢз ”з©¶зҡ„иҜ„дј°з»“жһңеҸҜиғҪдјҡеӣ иҪҜ件зүҲжң¬зҡ„еҸҳеҢ–иҖҢжңүжүҖдёҚеҗҢгҖӮе°Ҫз®ЎеҰӮжӯӨпјҢиҝҷйЎ№з ”з©¶дёәDIAж•°жҚ®еҲҶжһҗе·Ҙе…·зҡ„йҖүжӢ©е’Ңеә”з”ЁжҸҗдҫӣдәҶжңүзӣҠзҡ„жҢҮеҜјпјҢдёәз§‘з ”дәәе‘ҳеңЁе®ҡйҮҸиӣӢзҷҪиҙЁз»„еӯҰйўҶеҹҹеҒҡеҮәжӣҙеҠ жҳҺжҷәзҡ„еҶізӯ–жҸҗдҫӣдәҶеё®еҠ©гҖӮ

- жң¬ж–ҮеҖҹеҠ©дәҶChatGPTиҝӣиЎҢиҫ…еҠ©и§ЈиҜ»пјҢз ”з©¶иҜҰжғ…иҜ·еҸӮи§Ғи®әж–ҮеҺҹж–ҮгҖӮи§ЈиҜ»иӢҘжңүй”ҷжјҸд№ӢеӨ„пјҢж¬ўиҝҺеӨ§е®¶жҢҮжӯЈ -


Guomics
йғӯеӨ©еҚ—з ”з©¶е‘ҳиҜҫйўҳз»„ (https://www.guomics.com)В й•ҝжңҹд»ҺдәӢиӣӢзҷҪиҙЁз»„еӯҰзӣёе…із ”究пјҢиҒ”еҗҲдәәе·ҘжҷәиғҪпјҢи§Јжһҗз”ҹзү©иҝҮзЁӢзҡ„еҺҹзҗҶпјҢеҠ©еҠӣз–ҫз—…иҜҠз–—гҖӮеӣўйҳҹиҜҡйӮҖдјҳз§Җз ”з©¶з”ҹеҸҠеҚҡеЈ«еҗҺз ”з©¶дәәе‘ҳеҠ зӣҹпјҒ