昆仑芯脱胎于百度芯片智能架构部,从2011年开始研发FPGA,在2015年出货量达到了5000片,在2017年部署达到1.2万片,并在同年发布了昆仑芯的XPU架构。通过五六年的发展,基于团队对整个AI发展趋势的理解,意识到FPGA已不满足芯片和AI发展趋势的要求。因此,需要寻找独特的发展路径。2018年正式启动昆仑芯系列产品设计,到2020年14纳米的芯片大规模部署。2021年4月,昆仑芯独立融资,同年8月,7纳米的第二代芯片开始量产,至今仍是主打产品。整体来看,百度昆仑芯是一个成立于2021年的公司,但实际走过了近十年的历程。

芯片的架构方面,百度作为最早提出"All in AI"的科技企业,昆仑芯先是理解了AI,然后再转向硬件开发。这意味着出发点是基于特定的场景、行业需求和生态系统来确定所需的算力。百度在ChatGPT之前已经有了深厚的技术沉淀。基于对场景的深入理解和对性能的追求,公司知道自己所需的方向。这两年,大模型对算力的需求呈指数级增长,如何高效地解决大模型计算的效率和成本问题,已经成为行业的一个挑战。昆仑芯从芯片的角度出发,结合十年经验,提出了三个解决思路:架构的创新、产品定义的创新和软件栈的创新。
首先,从架构角度看,可以通过对比CPU、GPU和XPU的控制单元、通用单元和加速单元来理解它们的设计差异。XPU架构专为当前的AI场景设计,与文心一言及其他大型模型形成完美的适配,有更多的AI加速单元,并且又有很好的可编辑性,比如可以通过C和C++的编程,做到高性能和可编程,帮助提升AI计算的效率。

其次,关于产品定义打磨。昆仑芯第二代产品具备优越的参数,与同等价位的产品相比,更能满足大模型的需求。大模型的参数量巨大,很多时候单卡、单机都难以支撑。因此,公司在产品设计时已经考虑到这一点,增加了大规模互联能力,支持芯片与芯片间200G的高速互联,确保大模型的分布式推理和训练。总之,昆仑芯希望通过这些独到的产品定义和技术优势,为大模型时代提供高性价比的计算力产品,满足各种客户的需求。

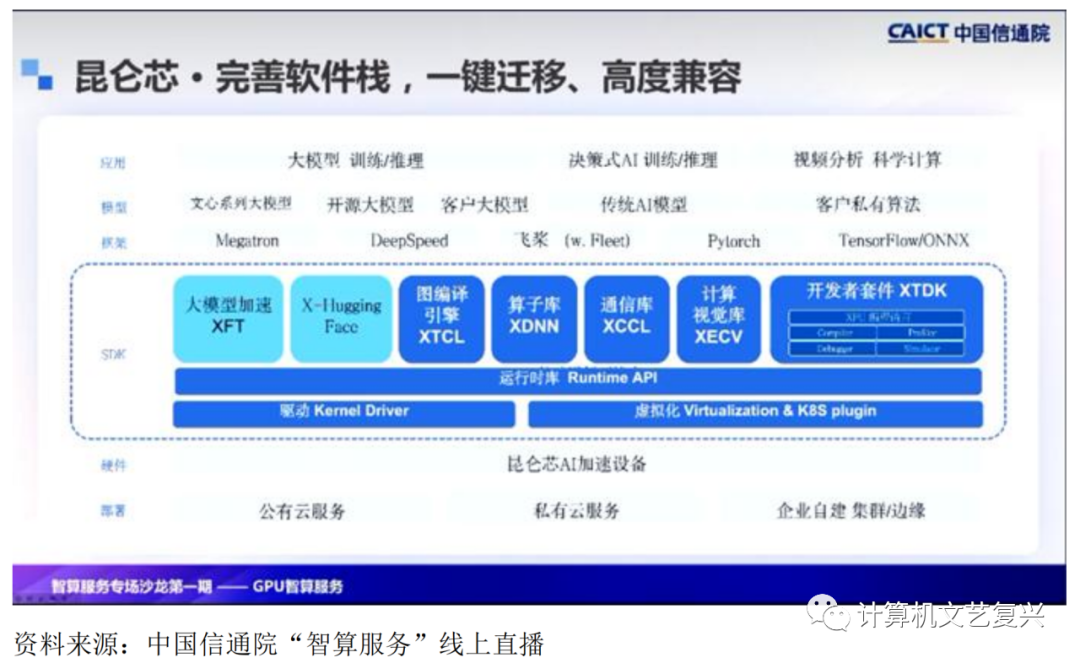
昆仑芯的背后是一套完善的软件栈。目前形成了一整套的SDK体系,从底层驱动到一套完整的运行库,语言使得开发者可以更快速地上手,包括一系列的图片引擎、算子库、通信库,然后形成一整套的SKT,然后能够支持各个场景的推理和训练。同时,也与Pytorch有良好的兼容性。与上层模型包括传统模型、小模型和大模型,与客户的私有算法也有良好的兼容性,能够满足一键迁移的需求。
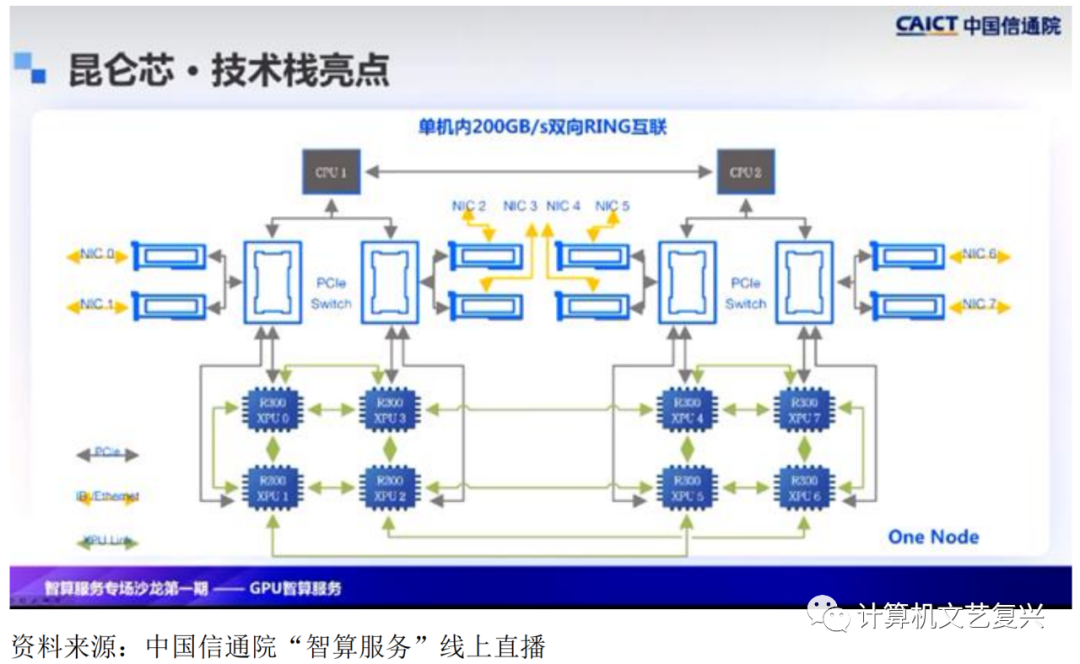
技术上,引入了ship to ship的互联技术,实现了单机内八卡的高速互联,达到200G的聚合带宽,实现了芯片之间跨机的低延时的通信。通过技术,昆仑芯实现了大规模集群的分布式训练和推理的能力。服务器单节点利用芯片互联技术实现了8XPU的互联,通信链通过两个闭环提供200G聚合带宽,服务器上的每个节点的每个芯片通过PCle switch直连一张2G网卡,每8个服务器节点通过一个NIC层网络连接,编织一个UT网络,形成一整套闭环,能达到32UT,形成一个POD集群。每个POD最大可以支撑2048芯片的互联,完整支持大模型时代的挑战。
这些芯片和能力,通过不同硬件形态与大模型进行关联,针对大模型,可以根据客户的模型参数规模来推进不同的解决方案。若模型在10亿以内,我们推荐R200、8F、RG800或T3E板卡,其性价比和性能均优异。对于模型在百亿到千亿的规模,推荐使用R480产品,它完美地呈现了所有技术特性,并在实际大模型场景中性能超出常规GPU的30%至80%。对于千亿级规模,R480集群实现了分布式推理,且软件层面已适配主流大模型,测试也都是达到预期的。

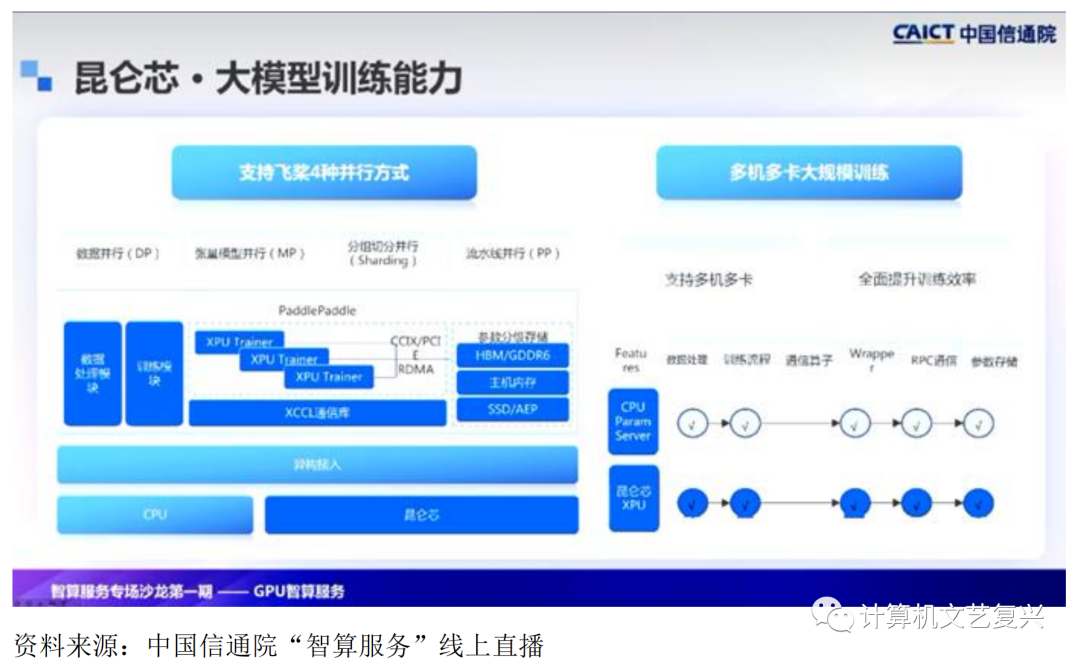
在基于大模型方面,还有两点很重要。首先是训练,昆仑芯的训练与分享部分深度协同,并支持行业主流大模型的分布式训练和推理。对于稠密大模型,支持四种并行模式,包括数据并行、张量模型并行、分组切分并行和流水线并行,以及飞桨独有的spring并行方式。对于稀疏大模型,推荐与飞桨构建大规模参数服务器架构,并通过技术全面提升训练效率。
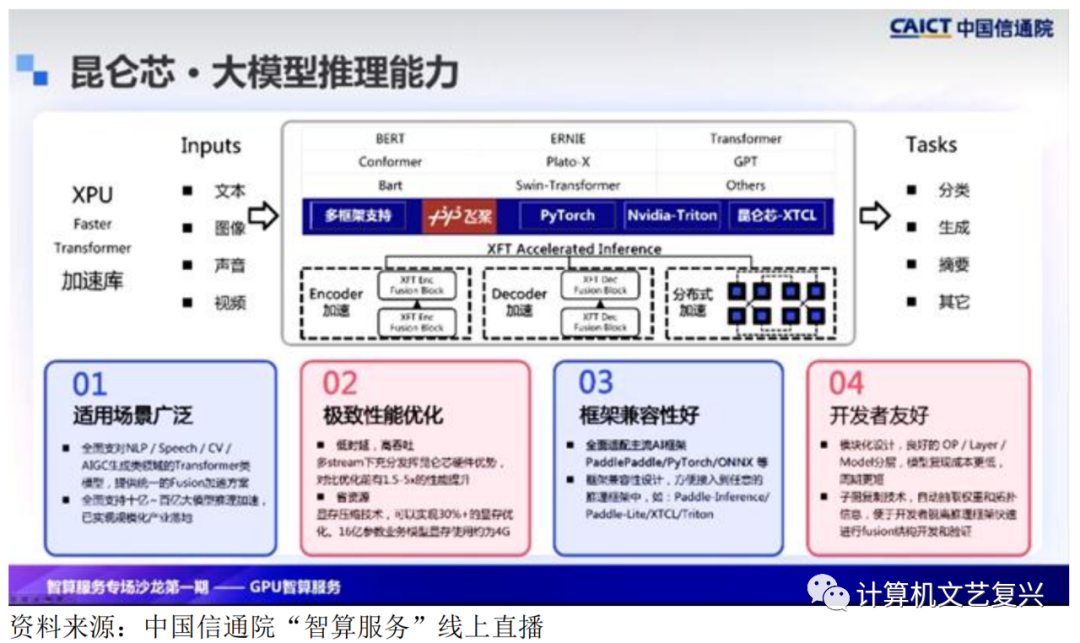
当前场景上应用更多是面向推理的能力。训练主要依赖于前期预训练、数据基础和技术能力的调优,与产业真正产生交集的是大模型推理场景。基于昆仑芯XPU的Transformer加速库,支持文本、图像、声音和视频,形成了一整套加速方案,包括框架支持等技术。适用的场景广泛,涵盖常规的NLP、CV,AIGC,以及生成类Transformer模型和大规模加速方式。
对于推理场景,客户最关心的是性能,及低延迟和高吞吐。昆仑芯的优化在这方面有大的提升。显存压缩技术可以实现30%以上的显存优化,16亿参数的业务规模可以节约近4G显存。框架兼容性好,全面适配了主流AI框架,并且设计方便接入到任意框架中。为开发者提供了很好的支持。
对于大模型的推理技术,主要围绕三个阶段进行:首先是单卡基建,解决百亿级推理;接着是分布式方式,主要解决模型迁移;最后结合具体应用推理场景,提供更好的定制化方案。昆仑芯已经将这三步的核心能力沉淀到XPU的fast Transformer加速库中,并在接口层实现了多个框架的兼容,方便客户快速应用和接入。
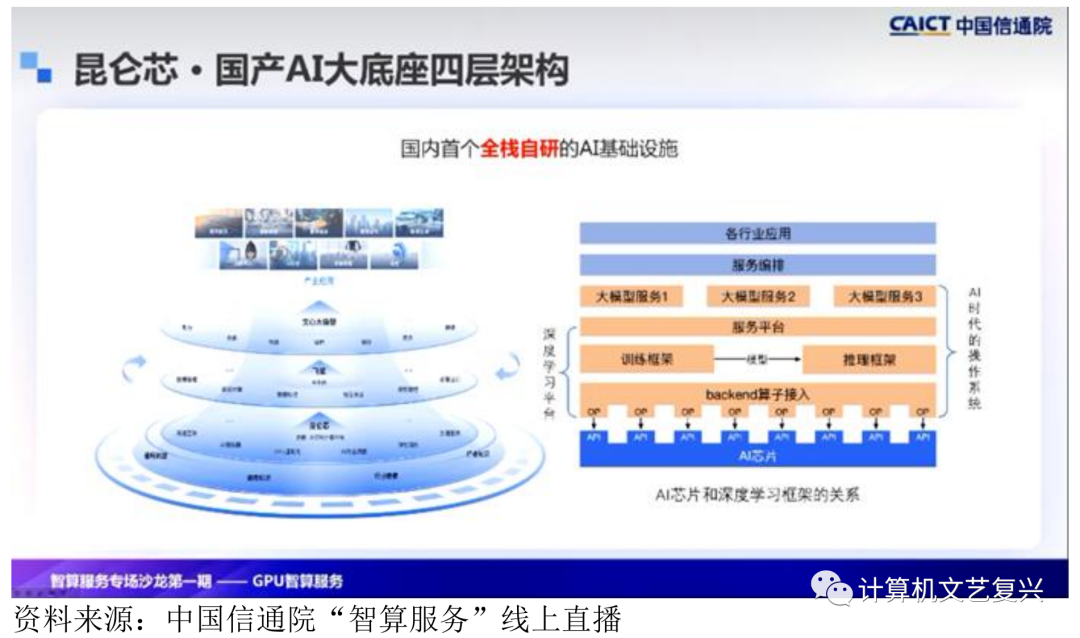
整体能力确立后,基于同样的理论依据,需要有机地组合它们。可以看到,百度的AI生态整体呈现出一个自身完整的架构。其中,昆仑芯保证整个底层的算力支撑,飞桨则作为人工智能时代的操作系统,支撑上层的小模型和一系列大模型的应用。最顶层是通过百度的智能云和合作伙伴进入各行各业,与此配套的是与芯片和深度学习框架紧密协同的关系。昆仑芯的分布式通信和飞桨的分布式实现在多级多卡下已经达到了信任能力。
在计算时间层面,昆仑芯与飞桨的算子库有两种基础模式。首先,可以直接映射到XDNN算子库中。其次,如果在开发过程中遇到特殊情境缺失,可以通过XTDK编程接口进行算子开发,进而接入飞桨算子库。
在设备管理方面,框架管理模块与昆仑新SDK的驱动和运行模块结合,使昆仑新加速卡可以被飞桨框架识别为可分配的计算资源,支持内存的灵活申请和释放,从而有机结合国产AI四层框架。
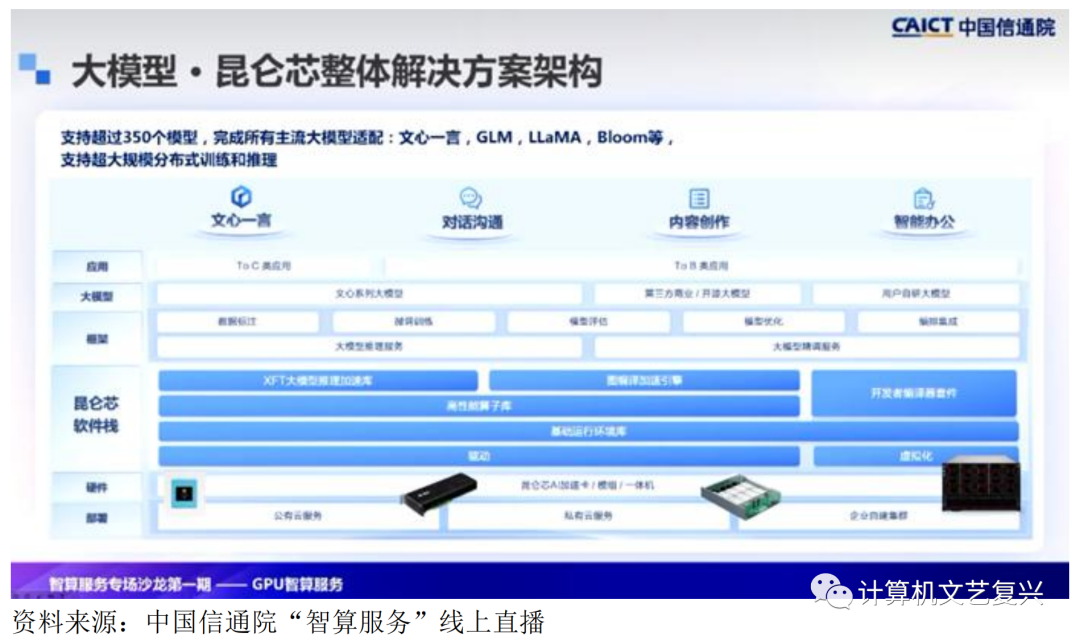
昆仑芯和整体解决方案包括底层、芯片、盖板卡,以及更好地支持片间互联的R480,这都基于昆仑芯的软件栈。通过上层框架,昆仑芯提供了基于飞桨平台的完整解决方案,如数据标注、大模型的微调推理服务和精调服务。昆仑芯已经成功论证了自己的大模型和第三方开源大模型。在此过程中,通过支持科研院所和一些合作伙伴,帮助开发自研大模型,从而实现大模型与产业的有机结合。