新一周EDA动态来袭!本周产业聚焦:国内大型论坛重磅发布与新型产品亮相,海外企业并购计划及制造封装领域前沿动态。
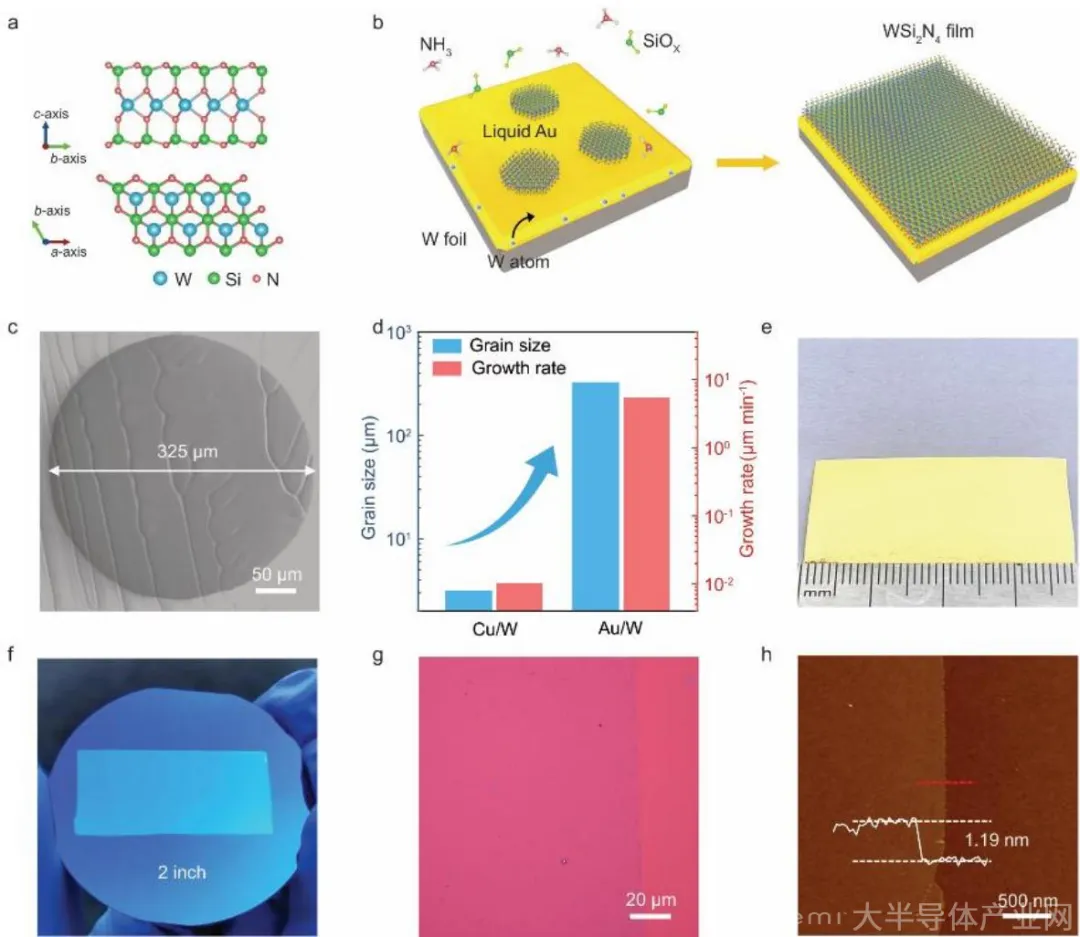
国防科技大学前沿交叉学科学院团队联合合作单位,在二维半导体关键技术上取得重要突破,相关成果有望支撑后摩尔时代自主可控芯片技术发展。
团队创新采用液态金 / 钨双金属薄膜衬底,通过化学气相沉积法,实现晶圆级、掺杂可调的单层 WSi₂N₄薄膜可控生长,该材料具备优异化学稳定性。新技术使畴区尺寸达亚毫米级,生长速率较现有报道提升约三个数量级。
研究证实,单层 WSi₂N₄是高性能 P 型沟道材料,在二维半导体 CMOS 集成电路领域应用前景广阔,可为我国自主芯片技术提供关键材料与器件支撑。
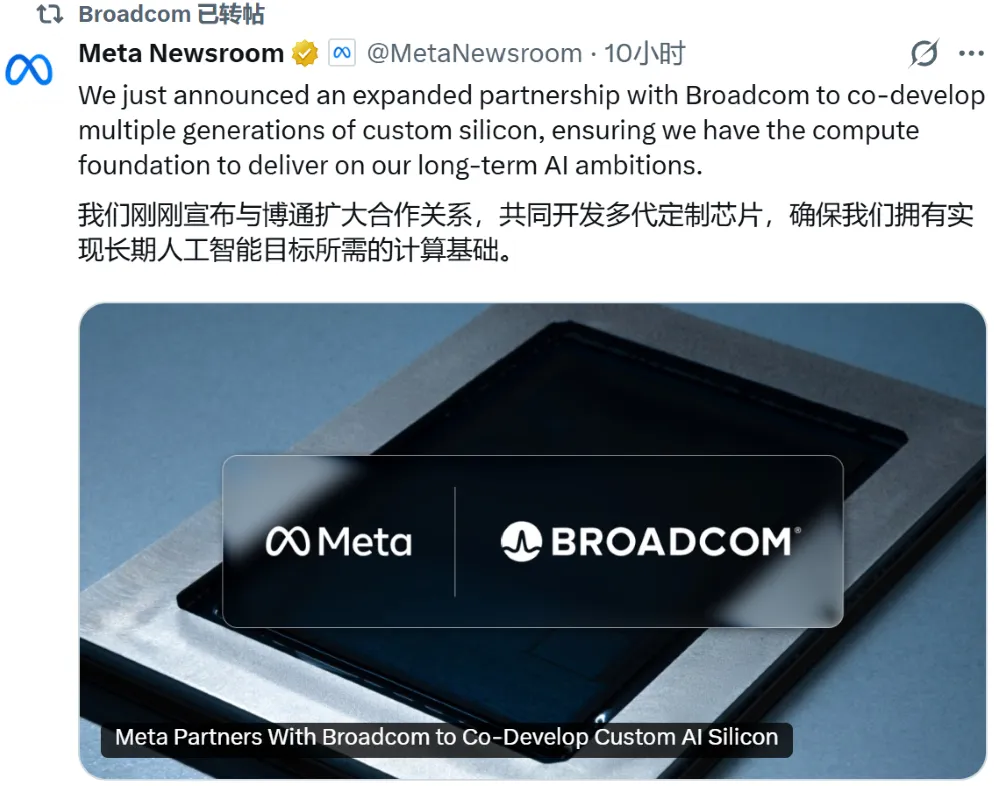
当地时间4月14日,Meta宣布与博通达成扩大合作协议,将合作期限延长至2029年,并承诺“吉瓦级”算力部署,联合研发数代定制AI处理器,以摆脱对英伟达通用GPU的过度依赖。消息公布后,博通盘后股价上涨约3.5%,Meta股价保持平稳。
此次合作核心是部署Meta自研的MTIA加速器,初始算力承诺超1吉瓦,未来还将扩展至数吉瓦级别。双方计划推出业界首款2纳米制程的下一代MTIA芯片,相比3纳米工艺大幅提升能效比,同时博通将提供以太网网络解决方案,保障AI集群高效协同。此外,博通CEO陈福阳将退出Meta董事会,转任定制芯片战略顾问以规避利益冲突。此次合作是科技巨头“去英伟达化”的缩影,既助力Meta加速自研ASIC芯片,也巩固了博通在AI基础设施领域的核心地位。
SiFive加速高性能 RISC-V 数据中心解决方案
2026年4月9日,美国加利福尼亚州圣克拉拉的RISC-V处理器IP行业标杆企业SiFive正式宣布,已成功完成4亿美元的G轮超额认购融资。本轮股权融资由Atreides Management领投,集结了Apollo Global Management、NVIDIA、Point72 Turion、T. Rowe Price Investment Management, Inc.等顶级投资者,公司原有投资者Prosperity7 Ventures和Sutter Hill Ventures也参与跟投。
此次融资后,SiFive估值已达36.5亿美元。据悉,融资资金将主要用于加速下一代数据中心解决方案研发,扩张全球工程团队,聚焦高性能标量、向量和矩阵RISC-V CPU及AI IP路线图,同时推进软件生态建设与客户赋能,以满足Agentic AI工作负载的需求,助力超大规模云厂商实现数据中心计算方案差异化,推动行业向开放标准的RISC-V架构转型。
据台媒报道,SK 海力士将于近期在韩国清州 M15X 新厂,扩大最先进 DRAM 量产规模。
M15X 为 M15 工厂扩建项目,投资约 20 万亿韩元,大量部署 EUV 光刻设备,2027 年龙仁半导体集群首座晶圆厂投产前,将承担下一代 HBM 产能需求。工厂本月起逐步提产,月产能从 1 万片增至明年 8 万片;年内可达 3 万至 5 万片,较原计划提前约两个月。其产出 DRAM 主要用于第六代 HBM(HBM4)及服务器级高性能 DRAM,业界预计 M15X 将成为 SK 海力士 2027 年前扩产 HBM 的核心据点。
近日,全球半导体设备龙头 ASML 在一季度财报会议上宣布实施 “产能倍增” 战略,以应对 AI 带动的芯片需求,消除 EUV 光刻机成为行业产能瓶颈的担忧。
作为全球唯一 EUV 光刻机供应商,ASML 公布明确产能规划:2026 年 Low-NA EUV 出货量至少 60 台,2027 年提升至至少 80 台,较 2025 年的 44 台实现翻倍。公司还设定年产 90 套 Low-NA EUV、600 套 DUV 系统的目标,并通过扩建厂房、提升库存保障供应。
同时,ASML 持续优化设备效率,旗舰机型 NXE:3800E 晶圆吞吐量提升至每小时 230 片,并规划了至 2031 年的详细产品路线图,不断提升 Low-NA 与 High-NA EUV 设备产能。
High-NA EUV 可用于 2nm 及以下先进制程,能大幅减少掩模版与工艺步骤,在成本与良率上优势显著,已具备支撑先进逻辑与存储芯片量产的技术能力,将为下一代芯片制造提供关键价值。
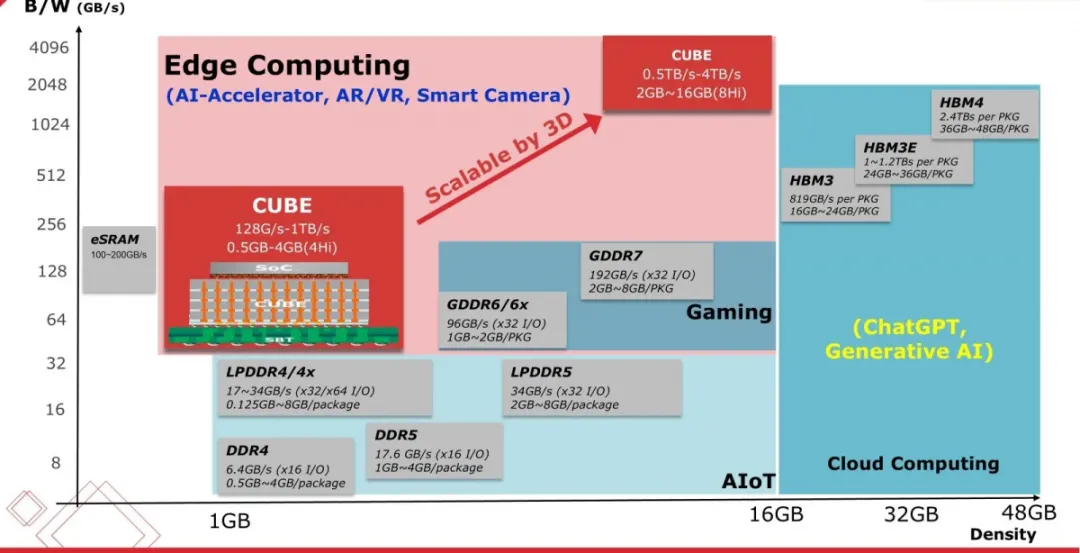
DDR5单引脚速率6.4Gbps、单模块速度51.2GB/s,性能接近DDR4两倍,电压降至1.1V更节能。采用8组架构及ECC纠错,适配AI PC、数据中心等场景,美光DDR5 MRDIMM可进一步提升带宽与能效39%。
预计2026年实现超150GB/s吞吐量,面向移动AI终端,速度提升33%、功耗降低20%以上,可解决LPDDR5带宽瓶颈,SK海力士、三星已推进量产。
主打AI训练场景,单堆栈速度超1.2TB/s,六颗堆叠总带宽达7.35TB/s,但单堆栈功耗超30W,仅适用于高端AI加速器、数据中心。
华邦研发,带宽突破1TB/s,单组容量可扩至8GB以上,4层堆叠可实现70GB密度、40TB/s带宽,依托TSV技术,适配AI边缘计算场景。
CUBE低功耗子系列,带宽8-16GB/s(等效LPDDR4x),功耗仅为其30%,无需LPDDR4 PHY,适配低功耗AI终端。
仍在开发中,预计单模块带宽超200GB/s、功耗降20%,优化AI加速器支持,未来将与HBM4、CUBE协同完善AI内存布局。
据图灵量子官微披露,4月15日,国内光量子计算企业图灵量子与AI网络互联企业奇异摩尔正式达成深度战略合作,双方将携手联合研发并推进下一代光互联OIO(Optical I/O)技术项目。此次合作将围绕算力互联架构、资源调度优化及行业场景适配等核心维度协同发力,核心目标是加速推动光互联技术从当前的“板级”互连,向更高集成度的“芯片级”融合升级,进而助力智算中心实现算力高效利用与业务敏捷部署。
合作分工明确,图灵量子负责提供定制化光芯粒和2.5D光电共封解决方案,奇异摩尔则聚焦开发Kiwi Optical IO芯粒,该芯粒可提供多种I/O接口底层数据通道,并兼容主流Scale-up协议,为异构计算节点传输提供支撑。未来,双方将以CPO技术为核心,锚定智算中心需求,在关键领域持续攻关,推动OIO技术从原型验证向量产落地跨越。
026 年 4 月 10 日,浙江大学极端光学技术与仪器全国重点实验室在杭州发布万通道 3D 纳米激光直写光刻机,为超分辨光刻、光子芯片制造等领域提供关键技术支撑。
该设备针对传统单通道加工效率低的痛点,通过光场调控生成上万个独立可控激光焦点,每个焦点能量可 169 阶以上精细调节。团队还研发自适应匀化算法、并行条带扫描等策略,大幅提升性能。其加工精度达亚 30 纳米,速率 42.7 平方毫米 / 分钟,最大刻写尺寸覆盖 12 英寸硅片。此成果突破传统光刻瓶颈,为大面积微纳结构的高通量、高精度制造开辟新路径。
4 月 14 日,海关总署发布 2025 年一季度外贸数据,进出口呈现双位数高增,进口增速更快,结构持续优化。
按美元计,一季度进出口总值 16906.5 亿美元,同比增 18.0%;出口 9774.9 亿美元,增 14.7%;进口 7131.6 亿美元,增 22.7%;顺差 2643.3 亿美元。按人民币计,进出口 11.84 万亿元,增 15.0%;出口 6.85 万亿元,增 11.9%;进口 4.99 万亿元,增 19.6%;顺差 1.86 万亿元。
出口方面,机电与高新技术产品为核心动力,机电产品出口增 21.4%。其中集成电路出口暴增 77.5%,汽车、船舶出口分别增 58.5%、48.7%。东方金诚冯琳指出,中国占全球传统芯片制程产能约三分之一,半导体产业链涨价强力推高集成电路出口额,显著拉动整体出口。
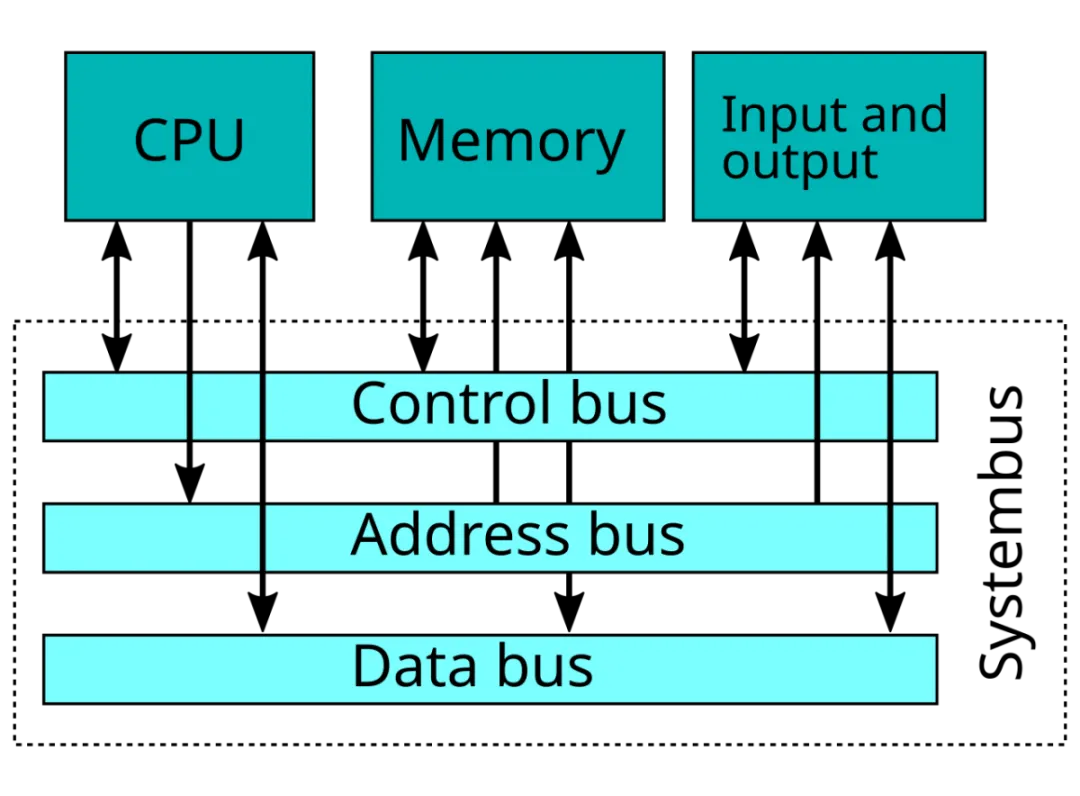
AI训练面临的最大挑战在于如何在内存和处理器之间传输海量数据集,而内存系统本身正是最大的瓶颈。随着计算性能的提升,内存架构也必须不断发展和创新才能跟上步伐。
概念起源:20 世纪 90 年代中期由 William Wulf 和 Sally McKee 提出,核心是处理器与 DRAM 性能差距引发的内存带宽瓶颈。
现状加剧:AI、HPC、大模型技术发展,万亿参数 LLM 对内存带宽需求激增,CPU/GPU 与内存性能差持续扩大,内存成为 AI 训练最大瓶颈。
基础架构:20 世纪 40 年代冯・诺依曼架构确立,处理器与内存分离,先天存在内存等待延迟。
技术迭代:先后通过提升内存总线速率、GDDR DRAM 满足 GPU 与早期 HPC 需求;AI 普及后,HBM 成为新一代高性能内存方案。
核心优势:采用 DRAM 垂直堆叠 + 硅中介层设计,带宽、能效显著优于 DDR/GDDR,被头部科技企业用于 AI 训练与推理。
标准升级:2025 年 JEDEC 发布 HBM4,通道数翻倍,带宽提升,平衡容量与带宽,适配 AI 高速发展。
现存问题:系统复杂度高、成本高于传统 DRAM。
持续挑战:LLM 参数年增 30%~50%,AI 向边缘计算延伸,带来散热、成本、安全等新难题。
发展方向:内存技术创新与计算能力同等重要,半导体行业将持续投入内存技术研发以适配 AI 发展。
如果您对我们的内容感兴趣,请继续关注我们~
欢迎评论留言,我们下周同一时间再见!