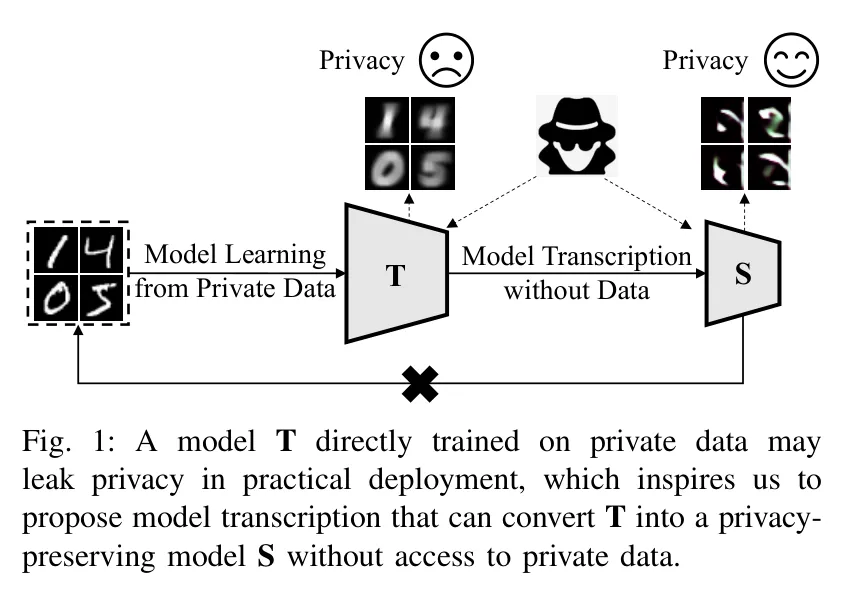
在深度学习大行其道的今天,我们习惯于将训练好的模型部署到各种终端。但你是否想过,这些看似“黑盒”的模型其实并不安全?攻击者可以通过模型反向攻击(Model Inversion Attacks)等手段,从模型参数中“还原”出训练时的私有数据。为了解决这一难题,来自中国科学院、悉尼大学等研究团队联合提出了一种全新的解决方案——隐私保护模型转录(Privacy-Preserving Model Transcription)。
该研究的核心是一种名为 DPSD(Differentially Private Synthetic Distillation,差分隐私合成蒸馏) 的框架。简单来说,它就像是一个“模型翻译官”,能在完全不接触原始私有数据的前提下,将一个可能泄密的预训练模型(教师模型)转录为一个具备差分隐私保证的安全模型(学生模型)。“转录”这一术语形象地表达了这种从模型到模型的转换过程,而“合成蒸馏”则揭示了其技术本质:利用生成器制造合成数据,并在蒸馏过程中注入差分隐私保护。

- 论文标题: Privacy-Preserving Model Transcription with Differentially Private Synthetic Distillation
- 机构: 中科院信工所;北京宇航系统工程研究所,悉尼大学
- 论文地址: https://arxiv.org/abs/2601.19090
01 为什么我们需要“模型转录”?
在实际工业场景中,我们经常面临这样的尴尬:手头有一个性能极好的模型,但它是在敏感数据(如医疗影像、人脸数据)上训练的。出于合规要求,我们不能直接部署它,因为模型可能会“记住”这些隐私。更糟糕的是,原始训练数据可能因为隐私政策已经删除了,或者因为数据量太大无法重新训练。
传统的差分隐私训练方法,如经典的 差分隐私随机梯度下降(Differentially Private Stochastic Gradient Descent, DP-SGD),通常需要在训练每一轮时对梯度加噪。这不仅会导致模型准确率大幅下降,还必须依赖原始数据。而 DPSD 的聪明之处在于,它开辟了一条“数据脱离”的新路径:既然没有原始数据,那我们就自己造。
02 方法详解:三方博弈的艺术
DPSD 的架构非常精妙,它设计了一个包含三个角色的“竞争-合作”学习框架:教师模型(Teacher)、学生模型(Student)和生成器(Generator)。
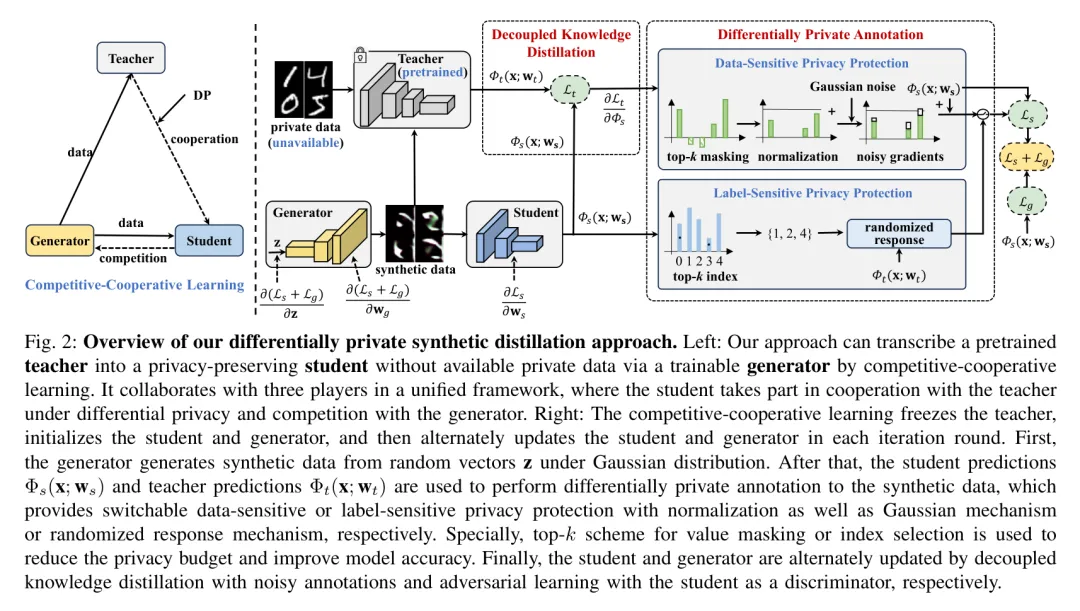
1. 角色分工与核心流程
- 生成器(Generator, ):它的任务是“无中生有”。它接收一个随机噪声向量 作为 Input,输出合成图像 。
- 教师模型(Teacher, ):它是知识的源头,已经过预训练并被冻结。它接收合成图像 ,输出原始的预测概率。
- 学生模型(Student, ):它是我们要培养的“安全接班人”。它既要学习教师的知识,还要作为“判别器”来监督生成器。
整个流程是一个迭代优化的过程(如 Algorithm 1 所示):
- 差分隐私标注:这是最关键的一步。教师模型对合成样本进行标注,但在将知识传给学生之前,会通过特定的隐私机制进行“脱敏”。
- 学生模型更新:学生模型利用这些带噪的标注进行学习,采用的是 解耦知识蒸馏(Decoupled Knowledge Distillation, DKD) 技术。

2. 灵活的“双重隐私”选择
为了适应不同的应用场景,DPSD 提供了两种可切换的隐私保护模式:
- 数据敏感型保护(Data-sensitive):如果你担心图像特征泄露(比如人脸的轮廓),可以使用 高斯机制(Gaussian Mechanism) 对梯度进行归一化和加噪。只保留最重要的梯度信息,从而在极低的隐私预算下维持高精度。
- 标签敏感型保护(Label-sensitive):如果你更担心类别身份泄露(例如在人脸识别中保护身份 ID),可以使用 随机响应机制(Randomized Response Mechanism)。它会以一定的概率“说谎”,从而保护真实的标签信息。
3. 生成器是如何被“调教”的?
很多小伙伴可能会好奇,没有真实数据,生成器怎么知道该画什么?秘诀就在三个损失项中:
- 分类损失:强制生成器产生的图像能被学生模型清晰地分类。
- 信息熵损失:确保生成的图像在各个类别之间是平衡的,不会一直生成同一类。
- 激活损失(-norm):这是一个非常巧妙的设计。因为真实图像通常能引起深度网络更高层的神经元激活,通过最大化这种激活,生成器被迫产生更具“代表性”的特征。
有趣的是,作者在理论上证明了这种方法不仅能满足 差分隐私(Differential Privacy, DP),还能确保模型最终收敛。
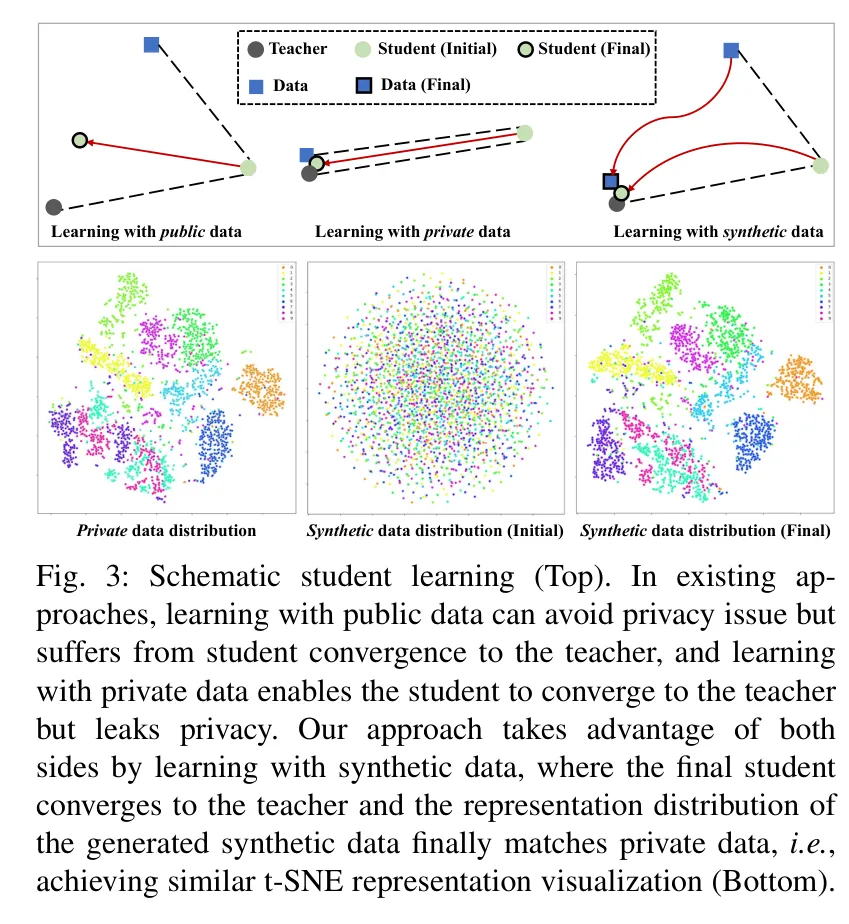
03 实验结果:性能与隐私的完美平衡
研究团队在 MNIST、Fashion-MNIST、CelebA、CIFAR10 以及复杂的 ImageNet 等 8 个数据集上进行了广泛测试,并与 26 种最先进(SOTA)的方法进行了对比。
1. 刷新性能榜单
在数据敏感型保护测试中,DPSD 展现出了统治级的性能。在 MNIST 数据集上,当隐私预算 (非常严格的隐私要求)时,DPSD 达到了 96.03% 的准确率,远超之前的 DPDFD (95.12%) 和经典方法 DataLens (71.23%)。
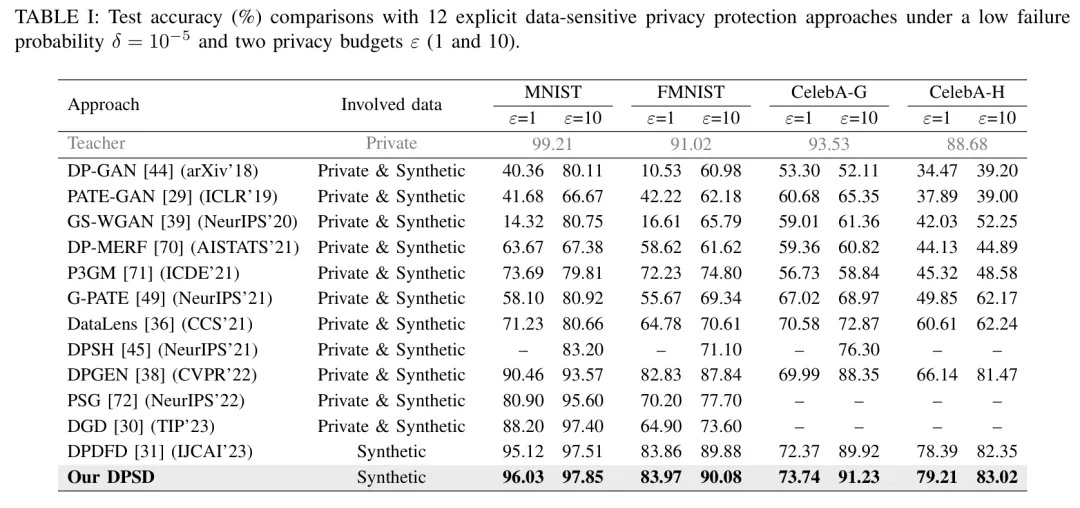
即使是在极具挑战性的 ImageNet 大规模数据集上,DPSD 也能成功将 ResNet50 的知识转录到 ResNet34 中,且准确率损失在可接受范围内。
2. 联邦学习下的表现
考虑到实际应用中数据往往分布在不同客户端,作者还提出了 FedDPSD 变体。在非独立同分布(Non-IID)的设置下,FedDPSD 在 CIFAR10 上取得了 71.12% 的准确率,显著优于传统的 FedAVG (43.67%) 和 DENSE (62.19%)。这说明该方法在分布式场景下依然稳健。
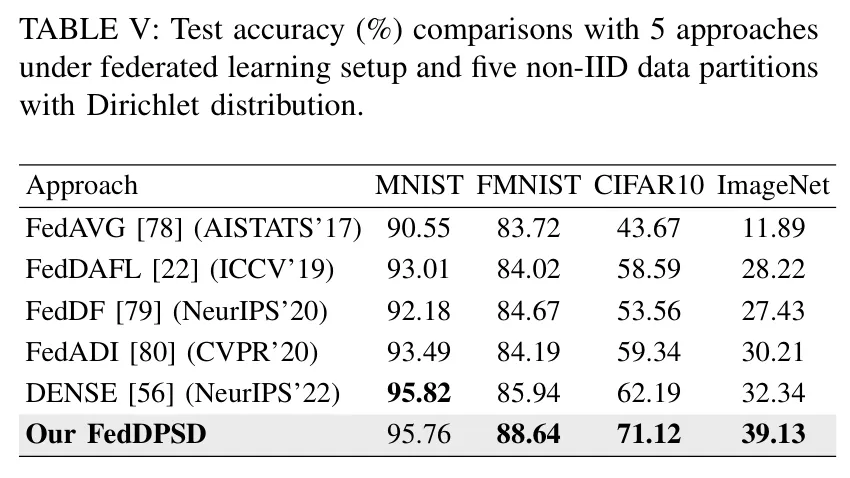
3. 参数敏感性分析
研究人员还深入探讨了参数对结果的影响。如图5所示,归一化(Normalization) 相比传统的 裁剪(Clipping) 能更好地保留梯度的相对比例信息,这在小隐私预算下至关重要。同时,随着迭代次数 的增加,模型准确率稳步提升,尤其是在 CIFAR100 这种复杂数据集上。
04 抵御攻击的能力:结实的“防弹衣”
为了验证“防弹衣”是否结实,作者模拟了 生成式反向攻击(Generative Inversion Attack)。结果显示,攻击者从 DPSD 转录的模型中还原出的图像充斥着大量噪声,几乎无法辨认出原始特征。

从图中我们可以看到,DataLens 虽然也有保护,但仍能隐约看出数字轮廓;而 DPSD 处理后的模型,其反向生成的图像完全变成了“雪花点”。这种直观的对比有力地证明了其隐私保护的深度。
05 写在最后
说实话,DPSD 的出现为隐私保护模型部署提供了一个非常有启发的新视角。它告诉我们:保护隐私不一定非要在训练阶段死磕原始数据,通过“模型转录”这种巧妙的二次加工,同样能达到甚至更好的效果。
正如作者在文末提到的,未来如果能引入更强大的 扩散模型(Diffusion Models) 作为生成器,这种“无损转录”的愿景或许会离我们更近。












 10个月宝宝每天需要喝多少奶粉?
10个月宝宝每天需要喝多少奶粉?
