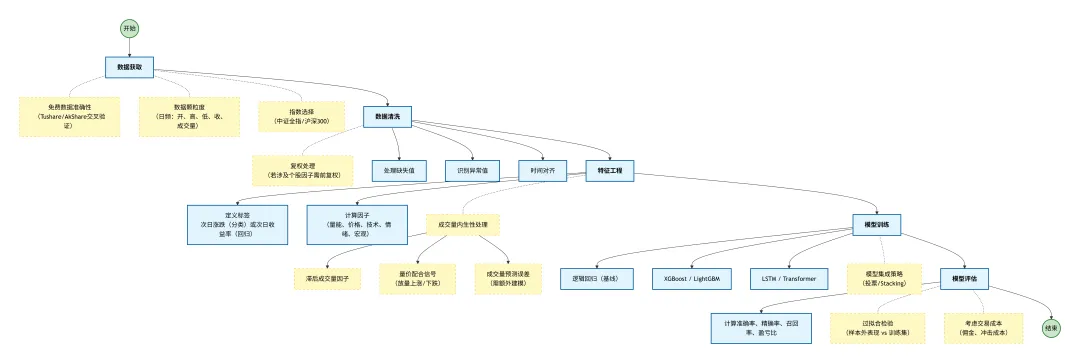
今日,我们正式开启新的学习。我们接下来的任务即是构建一个能够对未来整体市场行情有一个基本把握的模型,在这个模型中,我们将采用机器学习建模的方法。在AI时代,不管是思路整理,还是代表编写,AI都大大的提高了我们生产效率。如上图所示,即为我们用deepseek生成的一个模型的基本框架,接下来,我们就需要按照框架一步一步的实现即可。一、数据获取:打好地基
1.1 指数选择
要反映全市场整体走势,我们优先考虑中证全指(000985.SH),它覆盖沪深两市全部A股,最具代表性。若数据源不支持,也可用沪深300(000300.SH)作为替代,但需注意其偏向大盘蓝筹风格。我们这里将会采取两种数据进行比较,看看哪个指数的效果更好。
1.2 数据源与颗粒度
1.3 注意事项
二、数据清洗:去芜存菁
数据清洗是建模中常被忽视却至关重要的环节。对于日频数据,主要处理:
缺失值:检查停牌、节假日导致的空值,一般用前一日填充或直接剔除。
异常值:识别涨跌幅超过±10%或成交量突变为零等异常情况,结合上下文判断是否为真实事件(如成分股调整),否则予以修正。
时间对齐:确保日期连续,剔除周末和节假日,保证时间序列的完整性。
三、特征工程:构建预测信号
特征工程是模型预测能力的核心。我们将从定义标签、计算因子、处理成交量内生性三个层面展开。
3.1 定义标签
预测目标有两种常见设定:
建议先从分类任务入手,简化问题。
3.2 计算因子(部分)
从多个维度构建因子,捕捉市场信息:
| |
|---|
| 量能类 | |
| 价格类 | 涨跌幅、最高最低价差/收盘价、收盘价相对于N日均线的偏离度 |
| 技术指标 | |
| 市场情绪 | |
| 宏观/日历 | |
3.3 核心难点:成交量与收益的内生性
直接使用当日成交量预测次日收益,容易陷入伪相关。我们推荐以下处理方式:
建议优先使用方法一和方法二,简单有效。
3.4 特征工程注意事项
标准化:树模型无需标准化;逻辑回归、神经网络需Z-score标准化。
避免未来函数:所有因子必须基于当日及之前数据计算。
滚动窗口:计算移动平均等指标时,使用expanding或rolling窗口,确保不泄漏未来信息。
四、模型训练:从简单到复杂
我们采用渐进式策略,逐步提升模型复杂度,并观察预测性能的变化。
4.1 基线模型:逻辑回归
4.2 进阶模型:树模型(XGBoost / LightGBM)
4.3 高级模型:深度学习(LSTM / Transformer)
优点:能建模时间序列长期依赖,适合捕捉趋势和周期。
操作:将过去N天的因子序列作为输入,需构建三维数据,注意过拟合。
预期准确率:有望冲击70%,但需要大量数据和算力。
4.4 模型集成策略
五、模型评估:聚焦预测性能
根据你的需求,我们不进行模拟交易回测,而是直接评估模型的预测准确率、精确率等指标。
5.1 评估方法
5.2 核心指标
准确率(Accuracy):预测涨跌正确的比例,即我们关注的70%目标。
精确率(Precision):预测上涨中实际上涨的比例,避免盲目看多。
召回率(Recall):实际上涨中被正确预测的比例。
盈亏比:预测正确的平均收益 vs 预测错误的平均亏损。高胜率低盈亏比可能无法盈利。
5.3 过拟合检验
5.4 交易成本考虑(可选)
虽然不进行回测,但若未来打算实盘,可估算单边0.1%的交易成本,观察其对净收益的影响。这有助于判断模型的实用价值。
六、迭代优化:迈向70%胜率
若模型准确率未达预期,可通过以下路径迭代:
调整因子:新增有效因子,剔除噪音,尝试因子组合。
优化模型参数:使用网格搜索、贝叶斯优化寻找最优超参数。
尝试更复杂模型:从XGBoost升级到LSTM,或引入注意力机制。
特征工程改进:增加交互项、多项式特征,或对因子进行降维(PCA等)。
上述就是建模的一个整体框架呈现,下一期,我们将从代码着手,一步一步实现它,关注我,带你玩转量化!