吹起了“东风”。
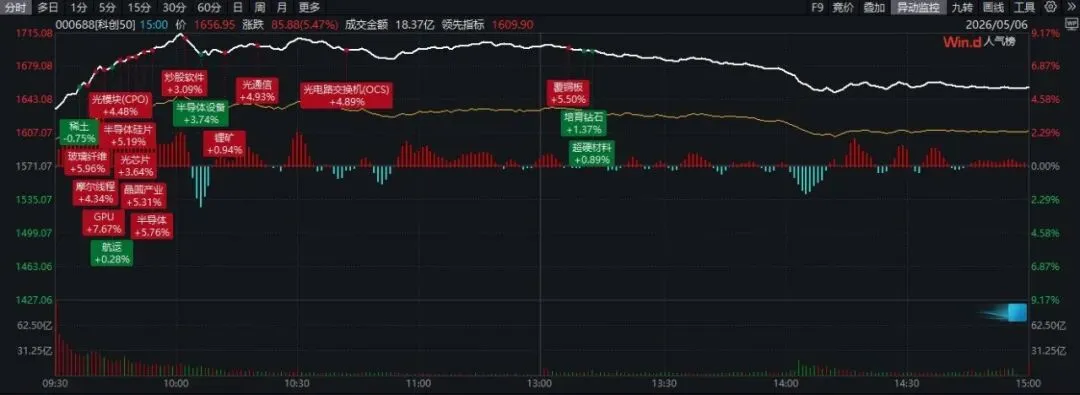
今天盘面上,存储器、GPU方向领涨,芯片、光模块等细分领域表现强劲,其背后是存储芯片行业供需格局的根本性改善。
要理解国产替代的空间,必须先看清我们要追赶的目标——英伟达。
黄仁勋前天在米尔肯全球峰会上说:中国不应该获得英伟达最先进的芯片,但美国要允许我们继续在全球竞争。
他也曾明确表示:中国的AI加速器市场拥有近500亿美元的价值,若英伟达失去进入这个市场,将对未来的业务带来显著的不利影响。
2024年,英伟达在中国GPU市场份额约70%,华为昇腾23%,其余国产合计约7%。英伟达出货约190万张,华为昇腾约64万张。
2025年,受H20禁令影响,英伟达中国出货量大幅萎缩。综合IDC最新报告,2025年中国AI芯片总量约400万张,国产出货165万张,国产化率跃升至41%,其中华为81.2万张,寒武纪11.6万张。
过去三年的出口管制,客观上成了中国AI芯片产业的强制性市场培育期。
当前顶尖大模型训练单轮算力消耗较2024年提升3倍,推理算力需求年增幅超320%,算力需求的爆发速度远超行业预期。
然而,算力供给严重不足的问题日益凸显。国内高端训练算力的缺口达40%,全球缺口也有15%-20%,就算你有钱想租,订单也已经排到了 2027年年中,头部的公共智算中心基本一直是满负荷运行的状态。这种供需失衡为国产算力产业提供了巨大的发展机遇。
中国AI算力产业,正在形成"GPU+NPU/DSA两派十家"的竞争格局、两种不同的技术路线选择。
GPU阵营以海光信息为龙头,其次是沐曦、摩尔线程、壁仞、天数智芯等。这条路线的核心逻辑是兼容CUDA/ROCm生态,降低迁移成本。
NPU/DSA阵营以华为昇腾为绝对领头羊,其后是寒武纪、百度昆仑芯、阿里平头哥,以及燧原科技。这条路线强调算法与硬件的深度协同,对Transformer架构做了针对性的算子优化,能效比突出。
华为昇腾是国内唯一真正与英伟达形成体系性竞争的厂商。
910C双Die设计:FP16算力达800 TFLOPS,性能逼近H100的80%
TPP性能:12032,相当于H200的76%,在国产芯片中排名第一
显存规格:128GB HBM,内存带宽3.2TB/s,超越英伟达A800,但低于H200
集群方案:CloudMatrix 384(384张910C组成超节点),FP16算力300 PFLOPS,是GB200 NVL72的1.7倍,总内存容量是后者的3.6倍
单卡性能落后英伟达约40%,但集群层面已可正面抗衡。
1. 性能对标:差距在缩小,但结构性鸿沟仍在
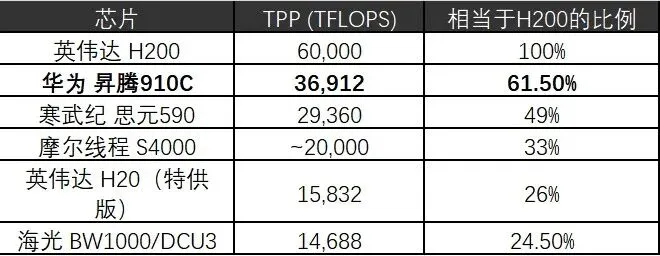
以TPP(理论算力峰值)指标为基准,参照伯恩斯坦研究2025年12月报告:
国产最强单卡(华为昇腾910C)TPP约为英伟达旗舰产品H200的61.5%,但已全面超越H20(禁令前中国市场的主要供应品)。这意味着国产替代在对等产品上已经具备了基本可行性。
单卡性能只是一个维度。真正的差距在于:
制程落后(国产主流7nm vs 英伟达Blackwell 4nm,晶体管密度差距约2.2-2.6倍);
软件生态(CUDA历经15年积累的算子库、编译器、调试工具链,国产平台文档完整性约为CUDA的70-80%,debug工具响应时间是英伟达的2-3倍,算子覆盖率与社区支持差距更显著);
能效(对比 H100,每瓦性能落后约40-50%,这在数据中心的电力约束下是实际运营成本;对比 H20 则领先 10-20%)。
2. 价格对标:50%的成本优势是实质性竞争力
目前,国产芯片在推理场景的竞争力明显强于训练场景。
当前市场采购价格:
英伟达H200:30-40万元/张(含25%"美国税")
华为昇腾910C(训练卡):18-22万元/张
寒武纪思元590(推理卡):裸卡 8,000-12,000 元 / 张,批量服务器配套 5-6 万元 / 张
海光BW1000/DGC3(训练卡):7-8万元/张
百度昆仑芯 P800(推理卡):裸卡 12-15 万元 / 张,服务器配套 18-20 万元 / 张
50%左右的价差,在智算中心、政务云、运营商采购场景中已形成实质性的经济吸引力,即使算上性能折扣,单位算力成本仍具优势。百度昆仑芯 P800 在推理场景下,单卡吞吐比H100低30-40%,但硬件成本仅为H100的40-50%。
综合考虑软件适配、电力消耗与维护成本,国产方案在多数场景下是合算的。
3. 生态对标:软件壁垒是最后一公里
英伟达的领先优势并非仅来源于芯片性能,更核心的是其构建的“芯片-软件-应用”闭环生态,CUDA生态经过多年积累拥有海量的开发者资源与成熟的应用适配体系,形成了极高的用户迁移成本,这也是其能够长期维持市场绝对主导地位的核心支撑。
国产芯片的破局策略分为三条路线:
1. 自研生态:完整替换英伟达软件栈,全栈自主可控、生态自成体系,适配强信创与国资场景;
2. 兼容生态:依托 AMD ROCm 生态授权降低迁移成本,是市场化落地最快的捷径;
3. 转译层:通过CUDA兼容层实现迁移,性能有一定损耗但开发者体验友好。
算力替代带动的不仅是芯片本身,还有光模块、液冷散热、先进封装(HBM国产化)、算力调度软件、电网……
当前,国产芯片主力仍在7nm节点,主要国产AI芯片厂商各有私有生态但互不兼容。只有投入足够的钱,才能持续迭代产品,然后赚更多的钱,继续投入,强化垄断地位。
政策定方向,流动性给估值,基本面给业绩——三者共振,行情才有持续性。