2025年,全球半导体产业于挑战与机遇交织中稳健迈进。依据世界半导体贸易统计协会(WSTS)发布的数据,2025年全球半导体市场规模有望突破7000亿美元,同比增幅约达11.2%。其中,人工智能(AI)与高性能计算(HPC)相关芯片的增长态势极为突出,有力地推动了先进工艺、封装以及存储技术持续创新。
在技术发展维度,2nm工艺节点已步入量产的关键时期,台积电的N2工艺在晶体管密度方面树立了行业典范;英特尔的18A工艺,借助环栅场效应管(GAAFET)与背面供电网络(BSPDN)技术的创新运用,在性能与能效方面实现了双重提升。
与此同时,存算一体、芯粒(Chiplet)、共封装光学(CPO)等前沿技术正加速从理论走向实践。北京大学、南京大学、中科院微电子所等科研机构在存算一体领域取得重大突破;imec成功达成250nm间距的3D键合,为逻辑 - 内存异构集成提供了关键的技术支撑;英伟达推出集成硅光引擎的CPO交换芯片,大幅提升了能效与部署效率,推动该技术在AI超级集群中开启早期应用。
随着摩尔定律逐渐逼近物理极限,半导体产业正从“单点技术突破”模式向“系统级创新”模式转变。2025年,部分新型半导体技术已从验证阶段跨越至规模化应用的临界点,为2026年的全面推广应用筑牢了坚实根基。在AI蓬勃发展、算力需求呈爆发式增长的背景下,这些技术突破将全方位重塑芯片设计、制造以及应用的全产业链,引领半导体产业步入新一轮的增长周期。
本文将深入探讨2026年全球半导体领域有望出现或实现高速发展的10大技术趋势,剖析这些先进技术的发展走向与市场前景。
趋势一:BSPDN引领先进工艺革新
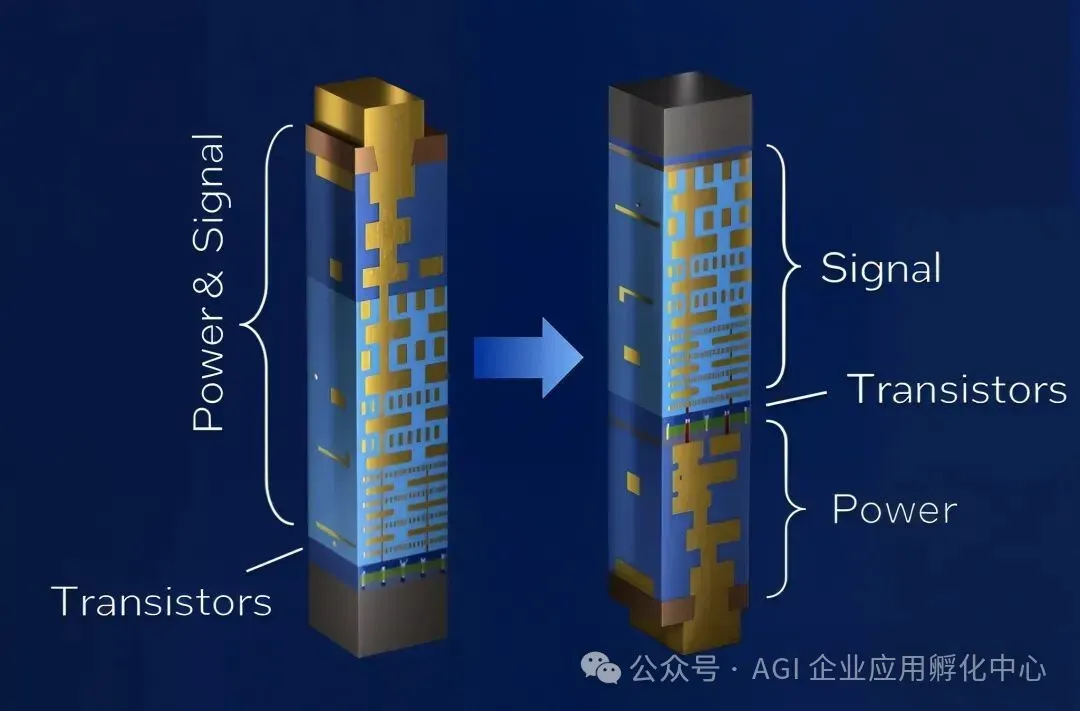
BSPDN正逐步跻身突破先进工艺物理瓶颈的核心技术行列,预计到2026年,它将全面迈入量产爬坡与生态拓展的关键时期。该技术创新性地把传统处于晶圆正面的供电线路转移至背面,借助纳米级硅穿孔(nTSV)或者埋藏式电源轨(BPR)达成电力的垂直传输,进而在物理空间层面实现了电源与信号布线的解耦。
这一改变意义重大,它不仅极大地缩短了供电路径、有效降低了IR压降(即电压损耗),还释放出正面的金属层资源,使其能够用于高密度信号互联。如此一来,信号完整性得到显著提升,晶体管的集成密度也大幅提高,为2nm及以下制程节点提供了可持续优化功耗、性能和面积(PPA)的有效路径。
目前,英特尔、台积电和三星这三大芯片代工领域的巨头,都已在BSPDN技术领域积极布局。英特尔依托其PowerVia技术,并融合RibbonFET GAAFET,计划在其18A工艺节点中引入BSPDN,且已进入量产爬坡阶段。在2025年VLSI研讨会上公布的系统比较数据显示,英特尔18A工艺通过采用GAAFET和BSPDN技术,在相同电压(1.1V)条件下,相较于英特尔3工艺,频率能够提升25%,或者功耗降低36%;在0.75V低压环境下,性能提升18%,功耗减少38%。此外,BSPDN的引入还使得正面M0层间距得以扩大,降低了制造的复杂程度以及良率风险。
正面与背面供电。(来源:Intel)
台积电计划于2026年下半年推出A16节点,届时将集成GAAFET与背面接触供电技术。台积电宣称,通过对布线资源使用效率进行优化,该技术可实现芯片密度提升7% - 10%,同时能效提升20%。三星则对外宣布,将在2027年的SF2Z节点中引入背面供电技术,采用直接背面接触设计,目标是性能提升8%,功耗降低15%,芯片面积缩减7%。
从技术层面来看,BSPDN将与GAAFET、3D互连实现深度融合。通过缩小标准单元高度(例如英特尔18A的高性能单元压缩至180nm)、优化金属层堆叠(采用22层结构并搭配背面金属隔离)等方式,提升晶体管密度,以满足高性能计算(HPC)、人工智能(AI)对算力的需求。与此同时,CMOS 2.0架构推动系统级芯片(SoC)进行垂直堆叠,imec已成功实现250nm间距的3D键合,为逻辑 - 内存异构集成提供了有力支持。在产业生态方面,厂商借助光刻校正技术,将键合误差控制在25nm以内,但全晶圆良率的提升仍有赖于工具方面的突破。
预计到2026年,BSPDN将加速进入量产阶段。此时,技术路线将出现分化(PowerVia主打低成本路线,背面接触则聚焦微缩方向),良率优化以及多技术协同(GAAFET与3D堆叠技术相结合)将成为竞争的关键焦点。随着工艺的不断优化,BSPDN将突破供电架构的限制,成为AI、HPC芯片的核心技术支撑。
趋势二:2nm全面上量,GAAFET接棒FinFET
自2021年IBM首次对外宣布成功制造出2nm节点GAAFET晶体管起,2nm工艺便引发了广泛热议。在2021 - 2022年这段时间里,英特尔代工、三星代工以及台积电(TSMC)陆续公布了各自的2nm节点规划,且基本都确定会在2025年达成量产目标。
从IEDM 2024大会上所公布的数据可知,台积电的N2工艺在晶体管密度方面持续保持领先地位,其晶体管密度高达313MTr/mm²。而目前已知三星的SF2工艺、英特尔的18A工艺对应的晶体管密度数值分别为231和238。尽管目前尚未获取这些工艺的物理尺寸相关数据,不过依据2021年IEEE发布的国际器件与系统路标更新内容,“2.1nm节点”预期实现的接触栅极间距(CGP)为45nm,最小金属间距(MMP)约为20nm。此外,2021年IBM宣布的2nm晶体管的栅极长度为12nm。
从FinFET走向GAAFET(来源:Intel)
毫无例外,几家主要的晶圆代工厂在2nm节点上均会采用GAAFET结构,而不再选用FinFET——这种结构下,所谓的纳米片电流通道被横向放置,并且被栅极从四面环绕。GAAFET作为一种被广泛深入研究的新型器件结构,不仅实现了对沟道更为出色的控制,而且通过对纳米片的宽度和层数进行灵活调节,再搭配不同的工作电压与阈值,能够在同一工艺平台上衍生出多种具有不同优化方向的晶体管规格。这为芯片设计客户提供了更高的设计自由度,涵盖了高性能和低功耗等多种选择。
这三家代工厂对GAAFET的命名各有特色:三星将其称为MBCFET,台积电依旧称其为GAAFET,英特尔的版本则命名为RibbonFET。在具体的实施方案上,它们也都存在差异。尽管三星早在3nm节点就率先应用了GAAFET,但当时的应用范围和量产数量都极为有限。因此,预计到2026年,2nm工艺芯片有望全面应用于手机、PC以及HPC领域,GAAFET也将在尖端工艺中全面取代FinFET,成为主流。
目前,三家代工厂的2nm工艺应该都已进入产能爬坡阶段。在2025年10月,英特尔率先发布了预计于2026年初推出的两款处理器,分别是用于PC笔记本的Panther Lake处理器和用于数据中心服务器的Clearwater Forest处理器,这两款处理器都将采用英特尔的18A工艺。
到了11月,有关采用2nm工艺的三星Exynos 2600芯片单核性能超越苹果M5的消息开始在网络上广泛传播……虽然截至发稿前,还没有任何关于2nm芯片确切的性能与功耗数据公布,但这些信息的披露,无疑表明英特尔和三星都有意在2nm GAAFET工艺节点上,以更积极的姿态与台积电展开竞争。
趋势三:CPO迈过发展拐点
在AI数据中心领域,基于光互连的方案本身并不罕见。不过,相较于可插拔光模块,将实现光电转换功能的硅光引擎与数字芯片直接封装在一起,也就是所谓的CPO技术,能够显著提升互联带宽,同时有效降低传输延迟。
在2025年的GTC活动上,英伟达发布的NVIDIA Photonics芯片,便是将交换芯片和硅光引擎进行了封装整合。这一创新带来了诸多优势,能效提升了3.5倍,抗干扰和抗打断能力增强了10倍,而且部署更为便捷,仅需以往1/4数量的激光器,从而大幅降低了功耗以及数据中心的总拥有成本(TCO)。
在同一时期,光通信行业的巨头企业、芯片制造商以及云服务供应商等,纷纷在CPO技术领域布局并加大投入。对于未来的AI数据中心而言,特别是在当下超节点、万卡集群盛行的情况下,CPO技术显得尤为关键。在AI大模型算力竞争激烈、功耗问题愈发敏感的大背景下,CPO技术自然成为了备受追捧的“香饽饽”。
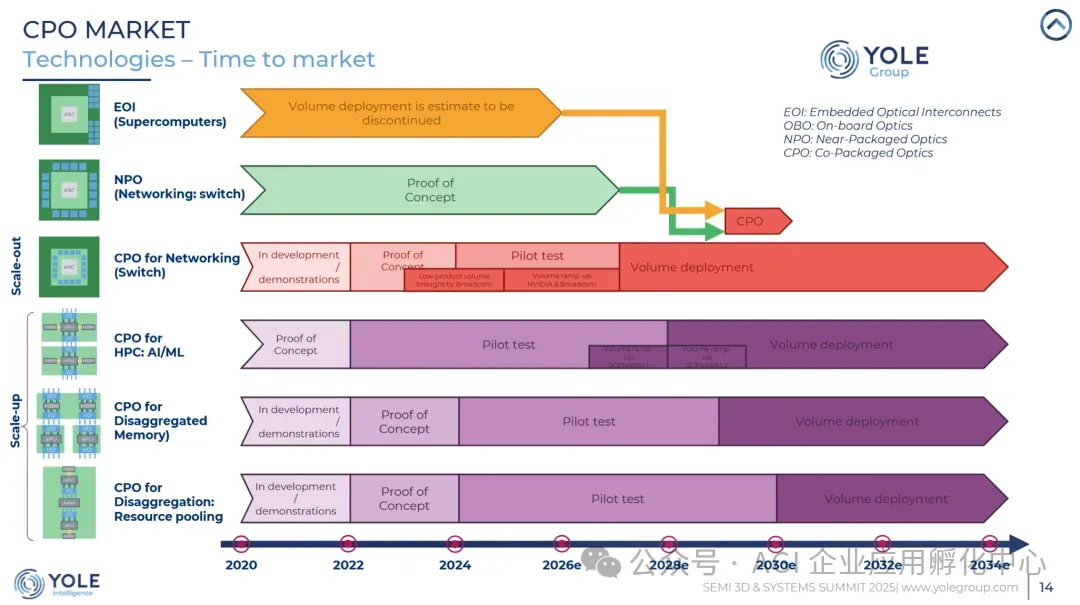
多家研究机构在市场展望中均指出,2025年和2026年将成为CPO芯片发展的关键转折点。届时,CPO技术将从试验性质的部署、概念验证(PoC)阶段,逐步迈向试运行、早期上量阶段,其采用率也将不断提升,尤其是在超级集群中的应用。此外,不同互操作性标准的逐步完善以及先进封装技术的持续进步,也在加速推动CPO技术的落地应用。
2020-2034年CPO市场规模预测(来源:Yole Group)
从更长远的时间维度审视,Yole Intelligence提供的数据表明,CPO市场的整体营收规模将从2024年的4600万美元,一路攀升至2030年的54亿美元,其年复合增长率(CAGR)高达惊人的121%。尽管Yole的这份数据在不同时期或许会有所调整,但三位数的年复合增长率基本已成定论。
此外,CPO在中国市场的发展态势格外引人关注。以曦智科技为代表的国产CPO芯片企业指出,受贸易摩擦和技术封锁的双重影响,中国在构建高算力AI芯片、打造AI计算超节点以及组建大规模训练集群的能力方面受到了限制。
而基于CPO的光互连技术能够显著提升跨机柜、跨节点的通信能力。在未来实现GPU或AI芯片直接输出光信号之后,CPO技术有望有效缓解单位芯片AI算力不足、超节点构建受限所带来的一系列不利影响。并且,硅光产品以及CPO封装并不高度依赖尖端制造工艺,国内头部生产线完全具备出色的生产能力,产业链发展也较为完备。因此,硅光技术对于中国的AI技术设施建设而言至关重要。
综合各方面因素考量,CPO以及未来的3D CPO都已成为AI技术发展路线中不可或缺的选项。
趋势四:RISC-V剑指全球算力“第三极”
从当下产业界释放出的种种信号来看,2026年无疑会成为RISC - V关键技术实现产业化的重要里程碑。届时,RISC - V架构有望围绕“行业专用化、高性能AI化、生态工业化”这三条主线,聚焦六大核心亮点,迅速崛起成为除x86、Arm之外全球算力领域的“第三极”。
在技术层面,RVA23服务器级配置文件将开启早期部署进程。到2028年,下一代RVA30或许会统一矩阵、向量与张量这三大AI扩展,构建起与Armv9、x86 - SSE同样完备且无需授权费的指令矩阵。从工艺角度而言,由于先进工艺逐渐逼近物理极限,Chiplet成为提升性能的最佳途径,“通用RISC - V架构 + AI加速 + I/O接口”的三明治结构将更受行业推崇。
伴随着生成式AI推理需求的爆发式增长,RISC - V未来的演进将着重于两个关键方向:一是推动向量处理单元(VPU)与张量处理单元(TPU)深度融合,实现通用并行计算能力与专用AI算力的高效协同;二是借助动态电压调节、指令集裁剪等技术手段,进一步提升AI设备的续航能力。
2026年,RISC - V在安全与标准化领域也将取得重大突破:RVA23 - Automotive规范文件有望完成ISO 26262 ASIL - D与IEC 61508 SIL3双认证,轻量级内存标记和能力硬件增强RISC指令(CHERI)等硬件级安全机制也有望获得通过。目前,RVA23文件规范已整合了81项扩展标准,明确了64位通用计算平台的接口技术要求。接下来,向量扩展2.0、安全扩展1.1等关键技术标准将完成修订,进一步降低技术开发的门槛。
此外,地缘政治因素加速了产业格局的分化,中国、印度、欧洲的中小厂商更多地转向开源指令集。预计到2031年,RISC - V SoC芯片出货量将达到200亿颗,在SoC市场获得超过25%的渗透率。与此同时,RISC - V在消费、计算机、汽车、数据中心、工业、网络六大市场的份额将处于26% - 39%之间。
总体而言,在未来3 - 5年内,RISC - V将通过针对汽车、AIoT、数据中心、工业控制等场景发布的专用配置规范文件,采用“分层规范 + 兼容性认证”的方式规避碎片化问题,一边冲击服务器与PC级通用算力市场,一边叠加AI功能扩展,在抢占AI推理、自动驾驶、服务器等高增长市场的同时,逐步降低架构迁移成本。
趋势五:Chiplet标准化浪潮重塑芯片设计新范式
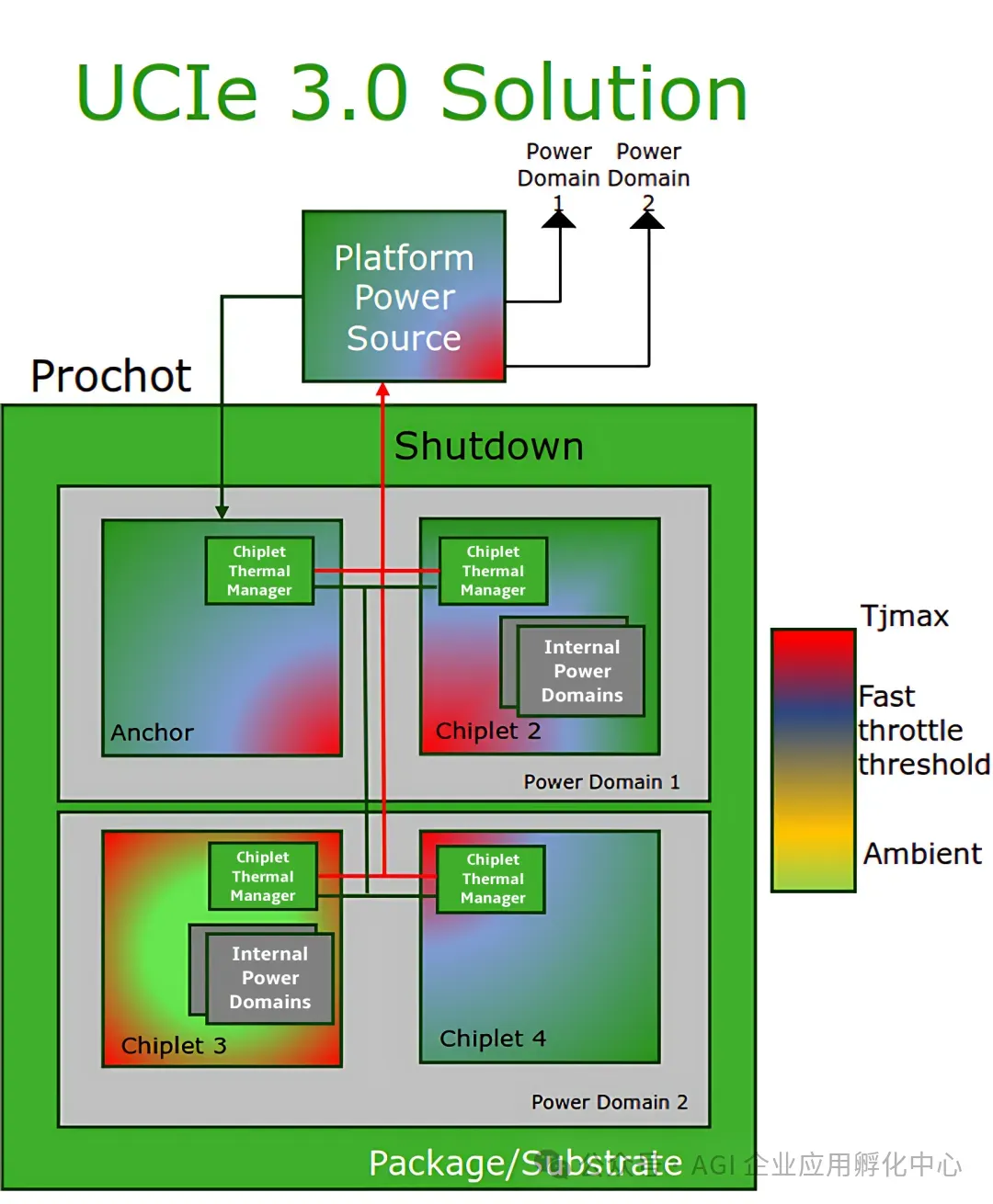
当下,摩尔定律正逐渐逼近物理层面的极限,Chiplet技术已然从原本的“过渡方案”成功蜕变成为“核心战略”。在过去,它大多被普通厂商当作应对大芯片良率不佳与成本高昂难题的权宜之计;而如今,随着UCIe 2.0/3.0标准的确立,Chiplet技术迎来了标准化爆发阶段,从少数企业内部的优化策略,迅速转变为全行业共同遵循的接口标准与规则,有力地推动着半导体产业架构进行深度重构。
UCIe标准的持续演进,堪称Chiplet技术腾飞的核心动力。其1.0版本虽搭建起了Chiplet互连的基本框架,但在带宽、延迟以及协议兼容性等方面存在明显不足。而2.0/3.0版本则使Chiplet互连进入实用化阶段,具备更高的带宽密度以及更广泛的协议支持能力,使得逻辑芯片、存储芯片、I/O芯片乃至未来的光子芯片都能在同一封装内实现互联。这种跨工艺节点、跨功能模块的集成方式,正在从根本上重塑多个芯片设计领域的基本范式。
UCIe 3.0新增功能(来源:UCIe联盟)
在设计模式层面,传统单片SoC模式要求CPU芯片将所有功能集成于一体,这直接导致设计复杂度与制造成本持续走高。与之不同的是,Chiplet架构支持不同功能模块采用各自最适配的工艺节点。比如,GPU逻辑采用先进工艺,而I/O与模拟电路则选用成熟工艺,如此便能实现资源的高效利用。在产业分工领域,UCIe标准的广泛推广有望催生类似“IP核市场”的开放生态。不同厂商提供标准化的模块,系统设计者则能像拼积木一样自由组合这些模块。这不仅优化了产业分工模式,还极有可能催生出全新的产业生态。
然而,Chiplet技术的发展并非一路坦途。随着3D堆叠与高密度互连技术的普及,功耗管理、热设计以及信号完整性等问题成为了新的发展瓶颈。在AI大模型训练这类对极限算力要求极高的场景下,如何在有限的封装空间内实现高带宽、低延迟且稳定的性能表现,成为Chiplet技术得以广泛普及的关键所在。与此同时,安全性与数据一致性也需要全新的体系架构来提供保障,以避免开放性带来新的安全风险。
展望未来,Chiplet的发展将呈现出阶段性特征。在短期内,UCIe 2.0/3.0将推动HPC与AI芯片向Chiplet化方向发展,并逐渐成为事实上的行业标准;在中期,Chiplet将与光互连、3D封装技术深度融合,突破带宽与能效方面的瓶颈;在远期,Chiplet生态或将转变为一个开放的市场,实现跨领域、跨工艺的互连。总而言之,当前Chiplet标准化的爆发,既是摩尔时代算力竞赛的关键路径,也是市场需求拉动下的产业变革。谁能构建出最具活力的Chiplet生态,谁就能在后摩尔时代的算力竞赛中抢占先机。
趋势六:芯片堆叠革命,混合键合开启逻辑芯片3D时代
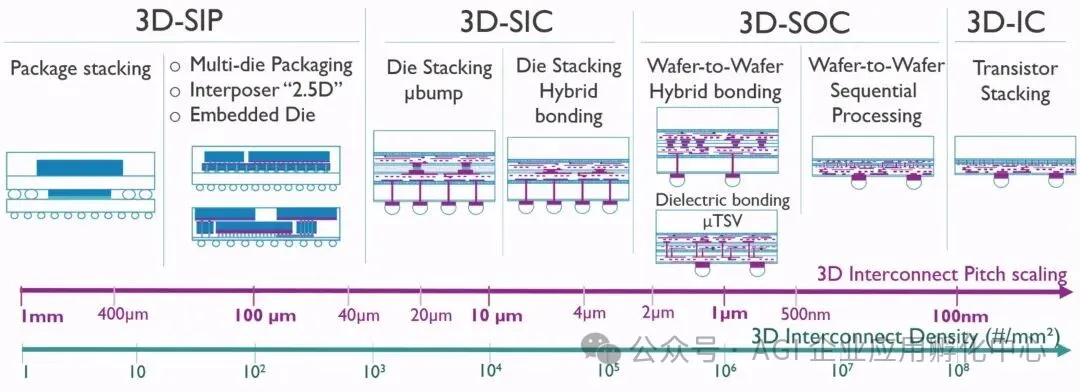
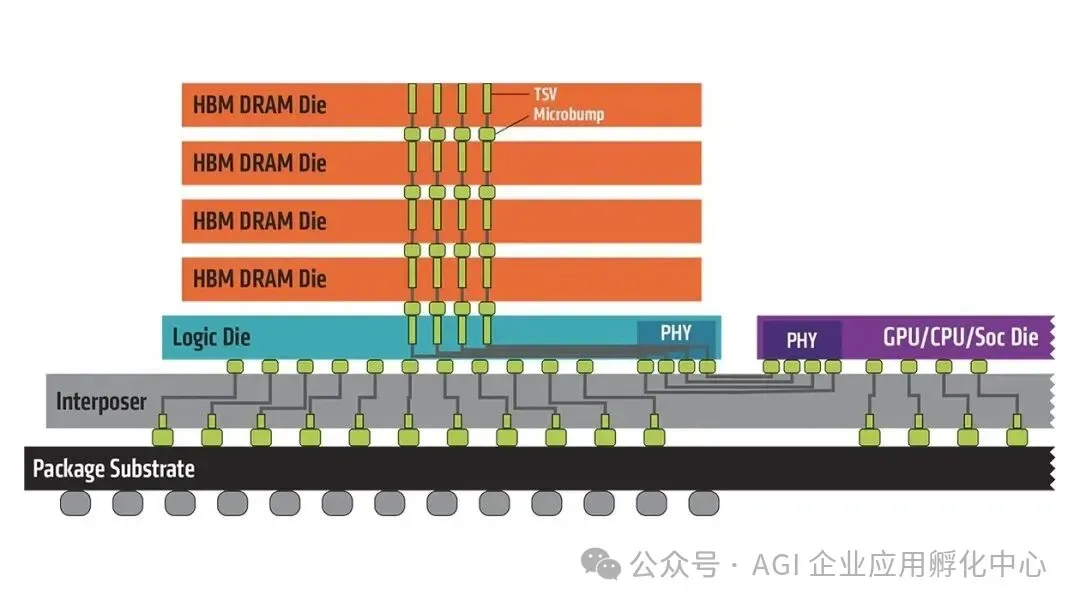
混合键合技术通过铜对铜直接键合突破传统封装极限,已成为后摩尔时代逻辑芯片三维集成的核心方案。其介电层与金属层同步键合,可将互连间距压缩至3μm以下,连接密度较传统TSV技术提升10-100倍,为逻辑与存储的异构集成提供原子级互联能力。
3D互连格局。(来源:imec)
该技术的核心突破在于无凸点互连架构,这一突破借助三大工艺得以实现:在表面工程领域,运用化学机械抛光(CMP)技术,将铜垫凹陷精准控制在2.5nm以内,同时结合等离子切割工艺,打造出无颗粒的边缘,确保实现原子级的平整接触;在对准技术方面,芯片对晶圆(D2W)键合的套刻误差小于350nm,晶圆对晶圆(W2W)键合的良率高达99.9%,为3D NAND的超高层堆叠提供了有力支撑;在键合机制方面,在300 - 400℃的低温环境下,通过热压合促使铜原子扩散焊接,同时介电层发生分子键合,形成兼具机械强度与电学性能的稳定复合界面。
到2025年,行业将呈现出技术分化与协同并存的格局。台积电的SoIC - X技术以9μm间距为AMD MI300系列提供支持,使接点密度提升了15倍;其SoIC - P方案(6μm间距)面向中低端市场,预计在2025年实现N3 - on - N4堆叠的量产,且良率损失控制在5%以下。英特尔的Foveros Direct技术通过铜对铜混合键合接口,实现了小于5μm的互连间距,后续的18A - PT工艺将与14A节点(基于High - NA EUV)相结合。三星的X - Cube技术采用TSV与混合键合融合架构,为16层HBM4E开发出4μm间距方案,在775μm模块高度内,可将芯片数量从12层增加至17层(含1颗基础芯片)。
在前沿研发方面,imec已成功验证了2μm间距的D2W键合,Kelvin结构的电学良率超过85%;SK海力士在HBM5开发过程中证实,混合键合是实现20层堆叠(单芯片厚度20μm)的唯一可行路径。
展望2026年,逻辑芯片3D化将迎来三大技术跃迁。在间距突破方面,台积电的A16节点(1.6nm工艺)将结合背面供电(SPR)与混合键合技术,通过信号层与电源层分离布线,在3μm间距下实现10⁴/mm²的连接密度,相较于2025年提升3倍;英特尔第二代Foveros Direct的目标间距为2μm,计划集成光互连引擎,实现片间1.6Tb/s的光学带宽。在工艺融合方面,CoWoS与SoIC的3.5D + 3D混合架构将成为主流,台积电的CoWoS CPO方案通过光引擎整合,可降低功耗50%、减少延迟10倍;EMIB与Foveros Direct协同封装则支持5×5处理器阵列,每边带宽达4.5Tbps。在良率控制方面,通过已知合格裸片(KGD)筛选与集体D2W键合优化,逻辑芯片堆叠的良率损失有望从当前的15%降至8%以下。
趋势七:HBM4量产引领算存架构革新
2026年,高带宽内存市场将迎来新的拐点。在数据中心和HPC持续扩容的背景下,算力架构对带宽、容量与延迟的要求被不断抬升,传统显存模式在资源利用和跨节点访问方面的限制愈发明显。在这样的趋势下,HBM4的商业化量产将逐渐确立其行业地位,成为产业链关注的核心。
HBM内部结构(来源:AMD)
HBM4的接口位宽实现翻倍,增至2048位,这使得单堆栈带宽能够高达2TB/s。借助先进的3D堆叠技术,它达成了最高64GB的单堆栈容量,同时对信号传输和功耗进行了优化,以此满足AI与HPC领域对数据处理的高要求。
在量产进度方面,头部厂商已开启激烈竞速。SK海力士于2025年完成HBM4的开发工作并开始小批量出货,还计划在2026年扩大生产规模。三星和美光也将依次进入量产阶段。台积电通过提升CoWoS产能以及优化封装流程,为HBM4的高密度集成筑牢基础支撑。整个产业链正形成协同之势,加速推动HBM4落地应用。
为适配更高的带宽密度,封装技术也将同步发展演进。CoWoS将进一步提升布线能力,玻璃衬底等下一代封装方案会加速开展验证工作,以提供更低的热膨胀系数与更高的互连密度。Chiplet架构将与HBM4紧密绑定,而硅光互连可能会在极限带宽场景中进行小规模测试,以此缓解铜互连在高频长距条件下的损耗与衰减问题。
值得关注的是HBM与CXL的协同作用。借助CXL 3.0,不同的加速器、CPU以及专用处理单元能够与更大的内存资源池建立高速连接。HBM作为加速器近邻的高带宽内存,与通过CXL扩展的通用内存池协同工作,能够在训练峰值时动态申请连续空间,在推理阶段灵活分配小块资源,从而提高整体利用率,减少碎片化情况并降低通信开销。
从演进路线来看,HBM4并非发展的终点。更高带宽密度的HBM4e已在规划之中,HBM5的研发也已启动,将在接口速率与堆叠高度方面持续实现突破。玻璃衬底、硅光互连以及更先进的热管理方法都将不断完善。
面向2026年,HBM4的量产不仅意味着性能的升级,更是围绕封装、互连、调度以及资源组织方式展开的系统性演进。在计算架构从板卡级迈向集群级的过程中,高带宽存储将成为不可或缺的基础能力,并在未来数年持续影响产业发展节奏。
趋势八:第三代半导体驱动绿色未来
伴随全球能源结构的深度转型以及AI算力需求呈现出爆发式增长态势,以碳化硅(SiC)和氮化镓(GaN)为代表的宽禁带(WBG)半导体,正从原本的利基市场逐步迈向主流应用领域。到2026年,第三代半导体的发展重点将不再仅仅聚焦于单一器件性能的优化提升,而是会将目光更多地投向规模化生产、系统级集成以及高可靠性等方面,从而全方位满足电动汽车、超快充、可再生能源以及AI数据中心对于高效率、低能耗和低碳排放的严苛需求。
在芯片的高集成度与系统级层面,WBG功率器件正加快从传统的分立器件朝着模块化与片上集成的方向演进。除此之外,借助3D堆叠与Chiplet技术,能够有效缩短功率传输路径、降低寄生电感,同时改善热阻状况。而垂直堆叠技术也开始在挑战高压领域的GaN功率器件中崭露头角、逐步兴起。
垂直结构的氮化镓器件正稳步迈向商业化进程。步入2026年,氮化镓发展的关键在于硅基氮化镓技术的持续改进与优化,以此确保能够在标准硅工艺生产线上制造出具备高可靠性且成本更具竞争力的器件产品。
在高耐压应用领域,碳化硅在1200V电压等级依然占据优势地位。预计到2026年,电动汽车制造商将加快导入800V高压电池平台,这将直接带动对1200V甚至1700V碳化硅功率模块的需求大幅增长。
2026年,异质外延技术将成为降低生产成本的核心途径之一,尤其是针对高频应用的高电子迁移率晶体管(HEMT)结构的优化。通过在硅或SiC衬底上外延生长GaN层,能够在器件性能与制造成本之间实现更好的平衡。近期的研究更是尝试采用石墨烯与六方氮化硼(h - BN)等二维材料作为缓冲层,以缓解晶格失配问题并提升散热性能,推动300mm大尺寸晶圆工艺走向成熟。
高导热封装与模块化集成技术也将在2026年成为各大厂商竞争的焦点。新一代封装将采用铜夹、烧结银等低热阻互连材料,以及直接键合衬底与嵌入式芯片设计,显著提升热管理能力与系统可靠性。此外,先进功率模块技术也将成为发展的重点方向,通过平面化设计、双面散热或直接液冷等方案,使功率模块能够在更紧凑的空间内处理更高的功率,实现低热阻、高散热性能与高功率密度的统一目标。
趋势九:AI加持EDA,驱动芯片设计“左移”
随着人工智能在半导体产业中的深度渗透,电子设计自动化(EDA)正迅速从传统的“辅助工具”角色,向“智能决策引擎”方向转变。这一转变的关键在于“设计左移”(Shift Left)策略的实施,也就是把原本在芯片开发后期才进行的性能分析、功耗预测以及可靠性验证等工作,提前到设计初期开展。如此一来,团队能够更早地察觉问题、优化方案,进而缩短开发周期,降低重新流片(respin)的风险。
“设计左移”并非是一个全新的概念,不过人工智能的加入,加速了它从理念转化为实践的进程。借助机器学习和强化学习技术,人工智能能够在设计早期就对芯片的PPA(性能、功耗、面积)进行预测,并实时给出优化建议,助力工程师在寄存器传输级(RTL)阶段就确定最优架构。这不仅提高了设计效率,还推动芯片开发从依赖经验驱动的模式,转变为依靠数据驱动的智能化模式。
全球三大EDA厂商正引领着这场转型。新思科技(Synopsys)率先将“设计左移”作为核心战略,如今更是把人工智能提前应用到设计初期,加快仿真与设计探索的速度,让EDA工具升级为智能协同平台。面对汽车电子数字化带来的挑战,该公司还提出了“三重左移”(Triple Shift Left)策略,将传统的串行开发流程转变为并行协同模式,并结合虚拟原型技术,实现更早期的功能与安全验证。
楷登电子(Cadence)则专注于验证环节的革新。其台湾区总经理宋栢安表示:“在人工智能时代,验证的重要性甚至超过了设计本身。”人工智能让验证工作更早地介入设计阶段,通过自动生成测试用例、实时异常检测以及软硬件协同仿真等方式,大幅缩短开发周期,实现设计与验证的同步进行。
西门子EDA资深总监Sathishkumar Balasubramanian认为,人工智能在EDA领域的价值并非仅仅停留在概念层面,而是通过工具、流程和平台这三个方面,真正实现“Shift Left”。借助数字孪生技术,设计团队能够在芯片开发初期进行全面的分析与优化,进一步提升效率与设计质量。
以AI推动设计左移:AI正成为EDA流程优化的核心动力,使设计团队在更早阶段完成优化与验证,加速开发与创新。(来源:西门子EDA)
展望2026年,EDA将迈入“多智能体AI”(Multi-Agent AI)新阶段。多个AI智能体将在设计流程中分工协作,从规格生成到签核分析自动衔接,形成具自我学习与协同决策能力的智能设计网络。这将进一步提升设计灵活性与自动化深度,推动EDA从“辅助设计”迈向“共创设计”,并推动芯片开发更具预测性与智能化,成为半导体创新的关键力量。
趋势十:存算一体技术加速落地
存算一体技术作为突破冯·诺依曼架构瓶颈的核心路径,预计在2026年将加速从技术验证阶段迈向规模化商用进程。该技术通过把计算单元直接嵌入存储器内部,有效消除了传统架构中因“存储墙”与“功耗墙”问题而产生的90%以上数据搬运能耗,理论上能够达成10 - 100TOPS/W的能效比,有望成为继CPU、GPU之后算力领域的第三极。当前,该技术已形成三大主要路径,分别是近存计算(例如AMD Zen系列CPU采用的HBM共封装方式)、存内处理(如三星的HBM - PIM)以及存内计算(CIM),其中存内计算由于实现了存储与计算的彻底融合,被公认为最具颠覆性的技术路线。
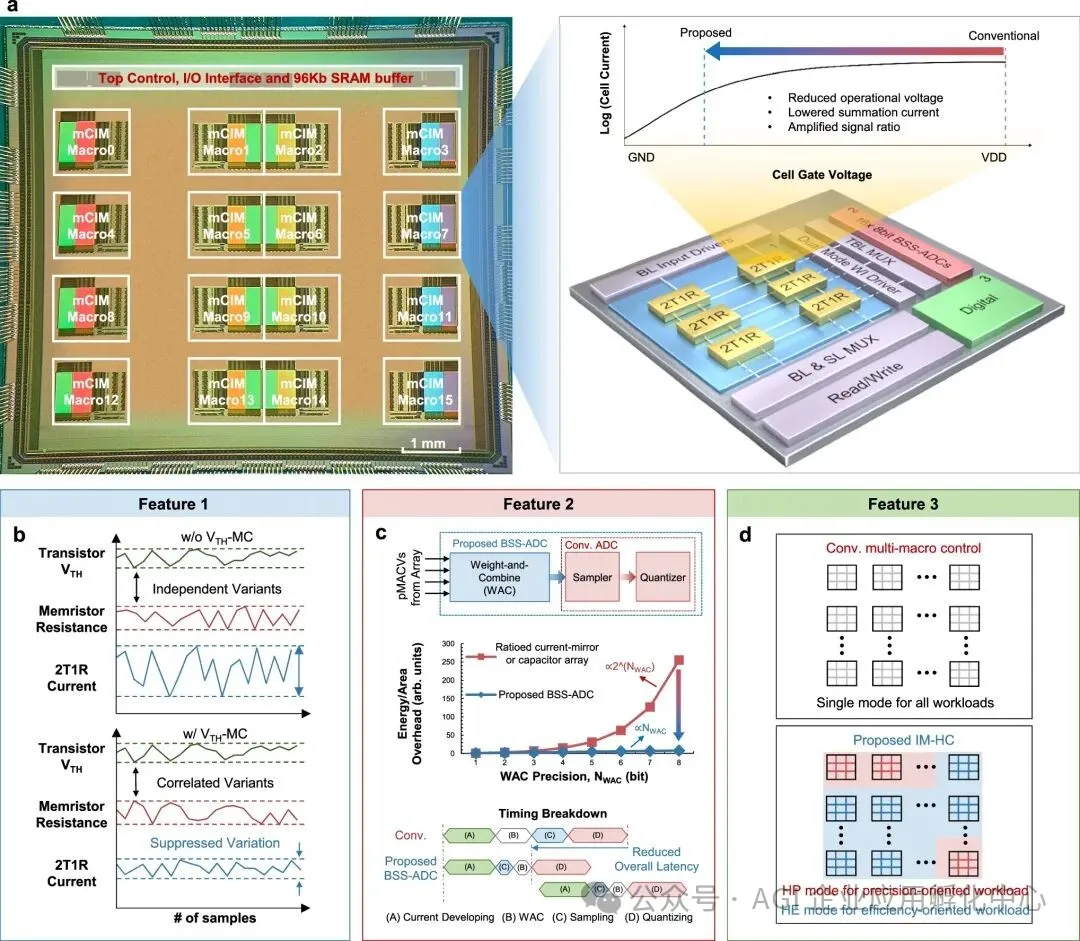
2025年堪称存算一体技术取得突破的关键节点。北京大学团队基于忆阻器构建了存算一体排序架构,采用“无比较器”设计,实现了速度提升15倍、能效提升160倍以及面积效率提升32倍的显著成果,并验证了其在路径规划、神经网络推理等场景中的实用性。南京大学团队提出了基于器件几何比例的模拟存内计算方案,在180nm CMOS工艺下,实现了0.101%的均方根误差,且在 -78.5℃至180℃的极端环境下仍能保持稳定,刷新了模拟计算精度的纪录。中国科学院微电子研究所研发的近阈值RRAM存算一体芯片,通过2T1R单元和电荷堆叠技术,实现了256通道并行计算,能效达到55.21 - 88.51TOPS/W,为边缘AI提供了高能效的解决方案。
基于近阈值计算的RRAM存算一体芯片(来源:中科院微电子所)
在产业竞争格局上,海外厂商选择以近存计算作为突破口,加速技术的落地应用。英伟达、三星、英特尔借助HBM共封装技术,推动近存计算在数据中心领域的应用推广;而d - Matrix的Corsair芯片集成了大容量的SRAM与LPDDR5X,使得推理任务的能耗降低了70%以上。国内企业也不甘落后,后摩智能发布了具备160TOPS算力的SRAM存算一体智驾芯片,知存科技量产了全球首款NOR Flash存算一体语音芯片,昕原半导体则实现了28nm ReRAM芯片的量产。
预计到2026年,存算一体技术将呈现出三大发展趋势:其一,技术路径将出现分化,近存计算凭借其低成本优势,将在端侧市场占据主导地位;而忆阻器、RRAM、SRAM等存内计算技术,则依靠极致的能效比,抢占云端AI推理的市场份额。其二,生态协同将加速推进,器件 - 电路 - 系统级技术栈的整合将成为关键所在。其三,应用场景将向自动驾驶、智慧医疗等对实时性要求较高的领域不断拓展。
当前,全球新能源产业蓬勃发展,硅碳负极材料作为锂离子电池核心关键材料,其技术创新与产业化进程直接影响新能源电池性能升级;石墨产业作为基础材料支撑领域,正面临结构优化、技术迭代与高质量发展的双重使命。为搭建产业链、创新链、资金链深度融合的高端交流平台,破解技术瓶颈、促进资源整合、推动产业升级,经多方筹备,南墅石墨矿定于2026年3月举办“2026(第六届)中国硅碳负极材料技术创新大会暨石墨产业高质量发展论坛”。诚邀国内外相关领域科研机构、生产企业、上下游应用端、投资机构及行业专家学者参会,共话产业发展新机遇、共谋技术创新新路径。欢迎各单位积极组织参加,现将有关事项通知如下:
总冠名单位:
征集中......
主办单位:
南墅石墨矿
联合主办:
征集中......
承办单位:
恩墨(山东)新材料有限公司
中科新能(山东)科技咨询有限公司
协办单位:
征集中......
支持单位:
征集中......
晚宴冠名:
征集中......
参展单位:
潍坊新翰泽能源科技有限公司
潍坊市友信粉体设备有限公司
山东深川变频科技股份有限公司青岛分公司
新乡市东瀚新材料有限公司
吉林敦化林机新能源材料有限公司
洛阳科创新材料股份有限公司
山东金顿新材料科技有限公司
东莞市凌聚机械有限公司
深圳美景环保设备科技有限公司
郑州市净天环保设备有限公司
青岛丰稔石墨科技有限公司
征集中......
赞助单位:
山东信众新能源材料有限公司
征集中......
媒体支持:
征集中......
1. 硅碳负极材料、石墨产业相关生产企业(原料供应、产品制造、设备研发等)负责人、技术总监、研发骨干;
2. 动力电池、储能电池、消费电子等下游应用企业采购负责人、技术选型负责人;
3. 高校、科研院所从事相关领域研究的专家学者、科研人员;
4. 行业协会、产业园区、投资机构、检测机构及相关服务单位代表;
5. 关注行业发展的政府主管部门领导及其他相关人士。
邀请行业权威专家、学者及企业领袖,就锂电气相硅碳与石墨的技术创新、应用进展、市场趋势等进行深入剖析。
(一)硅碳负极材料专题
1. 硅碳负极材料最新政策标准解读与产业发展趋势分析;
2. 高容量、长循环硅碳负极材料制备技术创新与工艺优化;
3. 硅碳复合材料界面改性、结构设计及性能提升方案;
4. 硅碳负极产业化过程中成本控制、规模化生产及质量管控技术;
5. 硅碳负极在动力电池、储能电池等领域的应用案例与性能验证。
(二)石墨产业专题
1. 石墨产业高质量发展政策导向与产业结构调整路径;
2. 天然石墨、人造石墨提纯技术升级与高附加值产品开发;
3. 石墨材料在新能源、新材料、高端制造等领域的创新应用;
4. 石墨产业绿色低碳生产技术与节能减排解决方案;
5. 石墨产业链供应链安全与协同发展策略。
设立展览区,展示锂电气相硅碳与石墨领域的最新研究成果、技术产品及应用案例,为参会者提供直观感受和交流平台。
组织商务对接活动,为参会企业搭建合作桥梁,促进产学研用深度融合与产业链上下游协同发展。
以庄重专业的流程表彰行业优秀企业,设置主持引导、嘉宾致辞、奖项揭晓、颁奖合影、媒体采访等环节,打造行业标杆盛会。
青岛大学材料科学与工程学院 教授
题目:硅碳复合负极材料制备方法研究
沈阳铝镁设计研究院有限公司/《轻金属》 副总工程师/副主编
题目:待定
四川长虹新材料科技有限公司 董事长、总经理
题目:待定
青岛大学材料学院,山东省低维材料与聚合物复合材料重点实验室,石墨烯创新研究院;临沂大学材料学院题目:待定
持续增加中......
申请报告联系人:王老师 15315983672(微同)
如需提交报告摘要或洽谈合作,可直接联系沟通。
1. 限时优惠截止至2月15日,需分享活动至朋友圈并集满10个赞方可享受;
2. 参会代表注册费包含会议资料、茶歇、1次午餐、1场晚宴及参会相关物料等费用;
3. 会议统一协调食宿安排,住宿费由参会人员自行承担;
4. 发票开具内容为“会务费”,仅提供增值税普通发票,暂不支持增值税专用发票开具;
注:所有人员凭参会证入场!提前注册缴费。
如需咨询赞助相关详情,可联系组委会,具体赞助类别如下:
实际呈现尺寸:2米(宽)×3米(高)
图片设计尺寸:2米(宽)×2.4米(高)
▸展位及参会预定专线:王老师 15315983672(微同)
帐户名称:恩墨(山东)新材料有限公司
开户银行:中国建设银行日照济南路支行
银行账号:37050171614100001452
行 号:105473200085