1.AI容易带来做很多事的幻觉:同时让AI做几个事情,还都是逻辑很强的开发工作,遇到问题后,自己就很着急的只想让AI解决,而没时间和意愿自己分析,引导AI,结果自己和AI同时做的多,错的多。
2.对AI的高阶玩法还缺少实践:比如今天看到了一个claude的插件:Superpowers。可能就能规范AI的开发,避免一些异常错误的出现。
今天继续看下高频系统中绑核的实现思路。
以之前系列文章中提到的行情模块的线程绑核实现过程来说,包括不同线程,如行情接收线程、排序线程、串行核心线程的绑核逻辑、Linux系统级配置以及绑核后的性能验证方法。
绑核的核心目标是通过绑核避免线程调度切换,最大化CPU缓存利用率。
1. 为什么要绑核?
- 操作系统默认的线程调度会将线程随机分配到不同CPU核心,导致:
- CPU缓存失效(核心切换后,原缓存的行情数据失效,需重新加载);
- 绑核(CPU Affinity):将线程强制绑定到指定物理核心,保证:
- 核心的L1/L2缓存始终存储该线程的行情数据,命中率接近100%。
2. 关键前提
- 区分物理核心和超线程核心:高频场景优先绑定物理核心(超线程会共享执行单元,引入竞争);
- 关闭系统
irqbalance服务:避免中断请求抢占绑核的核心,命令:systemctl stop irqbalance && systemctl disable irqbalance
- 关闭CPU超线程(可选,极致低时延):
# 在BIOS中关闭,或通过内核参数关闭echo off > /sys/devices/system/cpu/smt/control
3. 通用绑核工具函数(可复用)
封装跨平台绑核逻辑(Linux下基于pthread,Windows下基于SetThreadAffinityMask),优先实现Linux版本(高频交易多半采用的主流投研和交易环境),示例代码如下:
#include<thread>#include<pthread.h>#include<cpu_set.h>#include<stdexcept>#include<iostream>// 通用绑核函数(Linux)// cpu_id:要绑定的核心ID(从0开始,如0、1、2...)// t:要绑定的线程(std::jthread/std::thread)voidbind_thread_to_cpu(std::jthread& t, int cpu_id){// 1. 校验CPU ID有效性int cpu_count = std::thread::hardware_concurrency();if (cpu_id < 0 || cpu_id >= cpu_count) {throwstd::invalid_argument("CPU ID " + std::to_string(cpu_id) + " is invalid (total: " + std::to_string(cpu_count) + ")"); }// 2. 初始化CPU集合cpu_set_t cpuset; CPU_ZERO(&cpuset); // 清空集合 CPU_SET(cpu_id, &cpuset); // 将指定CPU加入集合// 3. 绑定线程到CPU核心int ret = pthread_setaffinity_np( t.native_handle(), // 线程原生句柄sizeof(cpu_set_t), // 集合大小 &cpuset // 要绑定的CPU集合 );// 4. 错误处理if (ret != 0) {throwstd::runtime_error("Failed to bind thread to CPU " + std::to_string(cpu_id) + ", errno: " + std::to_string(ret)); }// 可选:验证绑定结果cpu_set_t get_cpuset; CPU_ZERO(&get_cpuset); pthread_getaffinity_np(t.native_handle(), sizeof(cpu_set_t), &get_cpuset);if (!CPU_ISSET(cpu_id, &get_cpuset)) {std::cerr << "Warning: Thread bind to CPU " << cpu_id << " failed (fallback to system scheduling)" << std::endl; } else {std::cout << "Thread " << t.get_id() << " bound to CPU " << cpu_id << std::endl; }}// 绑定当前线程到CPU核心(适用于线程内部自我绑定)voidbind_current_thread_to_cpu(int cpu_id){std::jthread t(std::this_thread::get_id()); bind_thread_to_cpu(t, cpu_id);}
4. 行情模块各线程绑核落地
结合之前文章中探讨的行情模块涉及到的:行情接收、排序、串行核心线程等特点,按“核心隔离”原则分配CPU核心参考如下(注:只是概念示例,具体以自己实际设计的线程及行情订阅数量确定):
| | |
|---|
| | |
| | 与接收线程对应,就近分配核心(减少缓存跨核心传输) |
| | |
| | |
具体示例代码如下:
(1)行情接收线程绑核
// 行情接收线程池classMarketDataReceiver {private:staticconstexprsize_t kRecvThreadNum = 4; // 4个接收线程std::array<std::jthread, kRecvThreadNum> recv_threads_;// 接收线程工作函数voidrecv_worker(int thread_id, int nic_queue_id){// 可选:线程内部自我绑定(兜底,避免外部绑定失效) bind_current_thread_to_cpu(thread_id);// 原有行情接收逻辑 MD_SDK_Init(nic_queue_id);auto stock_list = get_stock_range(thread_id); MD_SDK_Subscribe(stock_list.data(), stock_list.size()); MD_SDK_Run(); }public: MarketDataReceiver() {// 初始化接收线程并绑核for (int i = 0; i < kRecvThreadNum; ++i) {// 创建线程(绑定到网卡队列i) recv_threads_[i] = std::jthread( &MarketDataReceiver::recv_worker, this, i, // 线程ID i // 网卡队列ID(与CPU核心一一对应) );// 绑定到CPU i(物理核心) bind_thread_to_cpu(recv_threads_[i], i); } }};
(2)排序线程绑核
// 线程级排序器classThreadLevelSorter {private:staticconstexprsize_t kSortThreadNum = 4;std::array<std::jthread, kSortThreadNum> sort_threads_;// 排序线程工作函数voidsort_worker(int thread_id, OutputFunc output_func){// 自我绑定到CPU 4+thread_id(如thread_id=0→CPU4,thread_id=1→CPU5) bind_current_thread_to_cpu(4 + thread_id);// 原有排序逻辑std::unordered_map<std::string_view, StockSortBuffer<128>> stock_buffers_; MarketData md;while (true) {// 处理行情排序... _mm_pause(); } }public: ThreadLevelSorter(OutputFunc output_func) {// 初始化排序线程并绑核for (int i = 0; i < kSortThreadNum; ++i) { sort_threads_[i] = std::jthread( &ThreadLevelSorter::sort_worker,this, i, output_func );// 绑定到CPU 4+i bind_thread_to_cpu(sort_threads_[i], 4 + i); } }};
(3)串行核心线程绑核
// 串行核心(因子/模型/策略)classSerialCore {private:std::jthread core_thread_;voidcore_worker(){// 自我绑定到CPU 8(独占核心) bind_current_thread_to_cpu(8);// 原有串行处理逻辑 MarketData md;while (true) {if (global_mpsc_queue.pop(md)) { calculate_factor(md); model_inference(md); strategy_logic(md); } else { _mm_pause(); } } }public: SerialCore() { core_thread_ = std::jthread(&SerialCore::core_worker, this);// 绑定到CPU 8 bind_thread_to_cpu(core_thread_, 8); }};
5. 系统级核隔离
为了让绑核的核心完全独占(避免系统进程抢占),可在Linux内核启动参数中隔离核心:
- 编辑
/etc/default/grub,添加内核参数:GRUB_CMDLINE_LINUX_DEFAULT="quiet splash isolcpus=0-8 nohz_full=0-8 rcu_nocbs=0-8"
isolcpus=0-8:隔离CPU 0~8,系统进程不会调度到这些核心;nohz_full=0-8:关闭CPU 0~8的时钟中断,减少内核干扰;rcu_nocbs=0-8:关闭CPU 0~8的RCU回调,降低内核开销。
- 更新grub并重启:
update-grub && reboot
6.绑核验证方法
(1)代码层验证
// 验证当前线程绑定的CPU核心intget_current_thread_cpu_id(){int cpu_id = sched_getcpu();if (cpu_id == -1) {throwstd::runtime_error("Failed to get current CPU ID"); }return cpu_id;}// 在线程工作函数中添加验证voidcore_worker(){ bind_current_thread_to_cpu(8);std::cout << "Current thread CPU ID: " << get_current_thread_cpu_id() << std::endl;// 输出应为8,验证绑核成功}
(2)系统级验证
# 查看线程的CPU亲和性(替换<pid>为进程ID)ps -eo pid,pcpu,cmd | grep <你的程序名># 查看指定线程的绑核情况(替换<tid>为线程ID)taskset -cp <tid># 示例输出(线程12345绑定到CPU8)pid 12345's current affinity list: 8
(3)性能验证
- 绑核前:用
perf stat -p <pid>查看线程上下文切换次数(context-switches),每秒可能达数千次; - 绑核后:上下文切换次数应降至0~10次/秒,缓存命中率(
cache-misses)降低80%+。
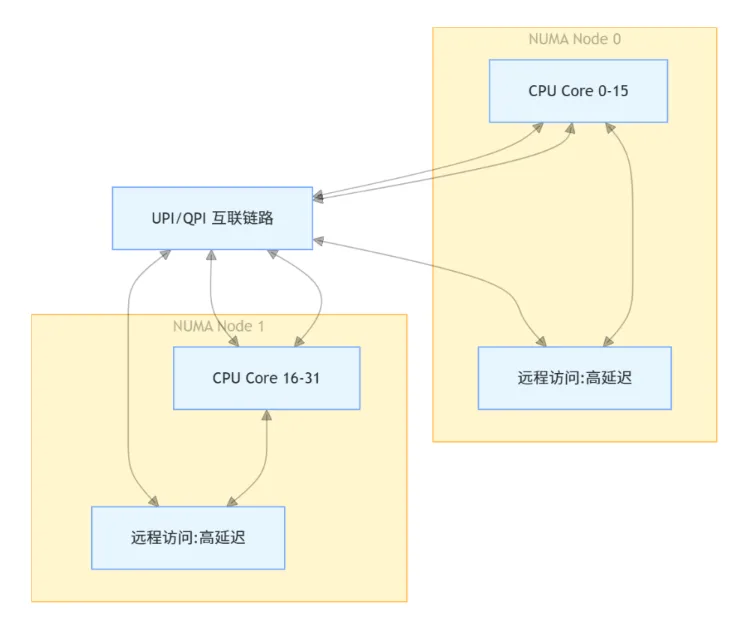
7.绑核跨NUMA问题
NUMA(Non-Uniform Memory Access)是一种内存架构设计,适用于多处理器系统。在NUMA系统中,每个CPU(更准确地说是NUMA节点)拥有自己“本地”的内存,访问这部分内存的延迟较低。而访问其他节点的“远程”内存则需跨NUMA总线,延迟和带宽都较差。举个例子,假如你的服务器有两个CPU,每个CPU配有本地的内存控制器和一块独立的内存。当线程A运行在CPU0上并访问CPU1的内存时,会发生所谓的“远程访问”。
跨NUMA是行情模块绑核的核心风险点,线程与内存、网卡队列跨NUMA节点访问,会大幅增加内存延迟、降低缓存命中率,直接破坏低时延特性。
优化必须遵循同NUMA节点绑定原则:行情线程、网卡队列、内存分配严格绑定在同一个 NUMA 节点内,禁止跨节点调度;通过numactl、lstopo工具校验拓扑,关闭 NUMA 自动均衡,优先使用本地节点内存。规避跨 NUMA 后,可彻底消除非必要延迟,保障绑核优化的低时延效果稳定落地。
行情模块绑核是实现低时延的关键优化手段。通过封装一个通用bind_thread_to_cpu工具函数,支持外部绑定与线程自我绑定并增强容错能力。核心分配遵循严格原则:行情接收、排序线程绑定连续物理核心并与网卡队列一一对应,串行核心线程独占物理核心,监控、日志等低优先级线程绑定超线程核心。配合系统级优化,隔离CPU核心、关闭irqbalance与超线程,最大化核心独占性。可通过代码层查CPU ID、系统层查taskset、性能层查上下文切换与缓存命中率完成验证。降低行情接收至串行核心端到端时延。