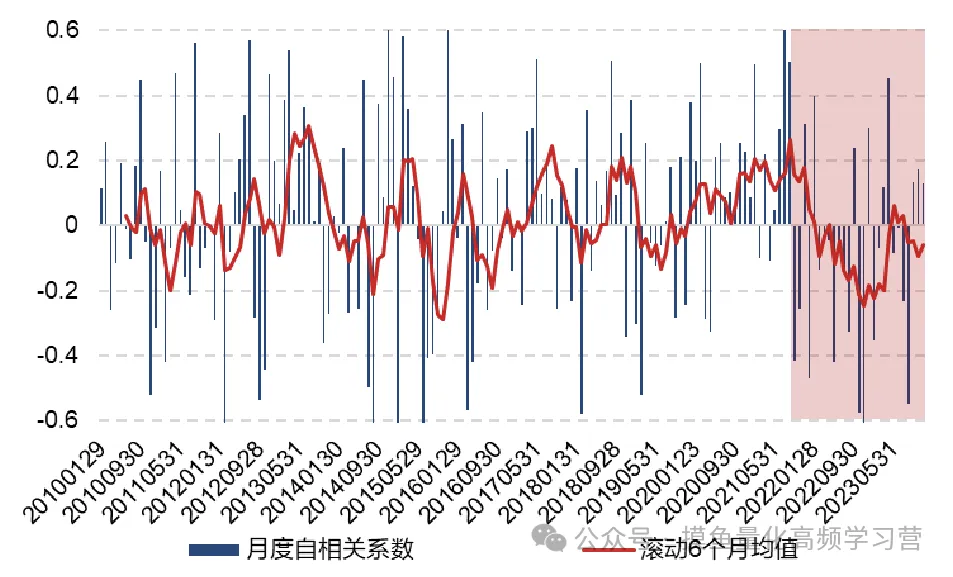
近年来,A股市场机构化趋势明显,量化私募机构的管理规模也迅速扩大,产生了一批管理规模超过百亿的量化私募机构。与此同时,传统的风格因子波动增大,从市场获取超额收益的难度在增加。 因子拥挤是因子收益下降的原因之一。因子代表着市场某方面的非有效性、或者是一段时期内的定价失效。当某类因子收益高的时候,会吸引更多的资金进入,从而出现因子拥挤,降低因子的预期收益。一旦新的因子被公开,套利资金的介入会使得错误定价收窄,因子收益也会跟着下降。因此,在多因子选股模型中,因子的开发和更新迭代变得越来越重要。以传统日频价量和更低频财务数据为基础的因子开发是一种研究途径。由于基础因子广为人知,在此基础上进行因子挖掘的收益提升空间相对有限。而且日频数据由于本身的数据量和信息量有限,过度挖掘会增大过拟合的风险。以高频价量数据为基础的因子开发在当下具有更大的收益提升空间。
本期主要针对目前行业内流行的各类量化选股因子,分批筛选出效果较好的不同类别的高频因子(除了市值因子,波动率因子等,低频因子目前超额不算稳定),并由此构建出多因子量化选股模型,并利用python编程回测模型的历史绩效。最终的目的是在众多的多因子选股模型中,发现表现相对更好的目标模型为投资者所用。本期包括构建、回测不同的多因子选股模型的过程中,展示具体的因子检验方法和流程,包括因子的有效性、稳定性、单调性的检验等。
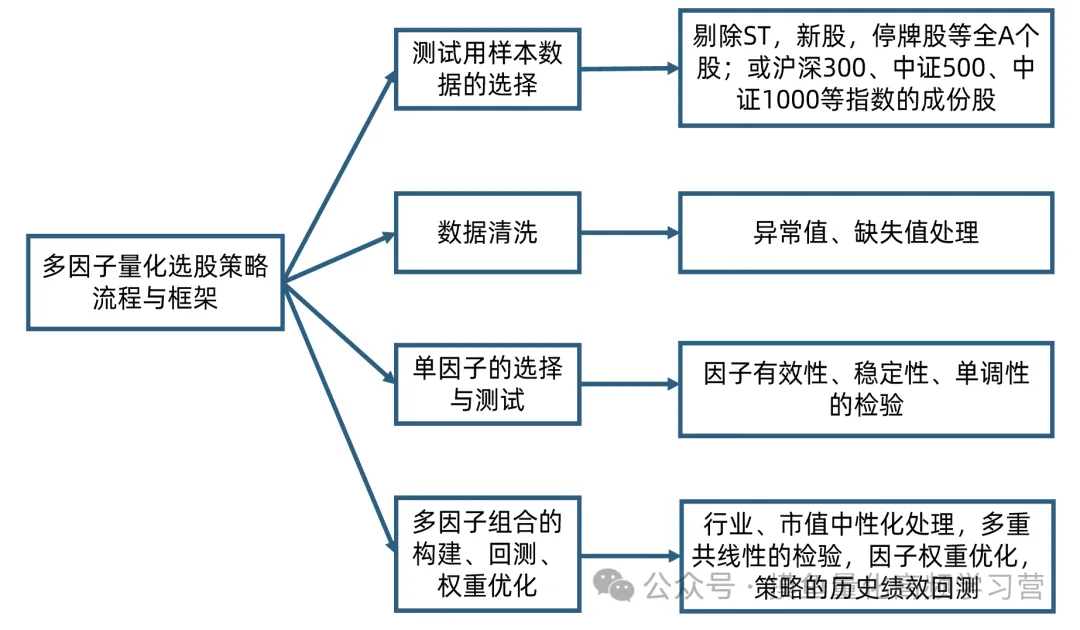
第一部分,测试用样本数据的选择。剔除ST,新股,停牌股后 的全A股;或者是沪深300、中证500、中证1000等指数的成分股。 第二部分,数据清洗。主要包括异常值,缺失值的处理。第三部分,单因子的选择与测试。单因子检验包括因子有效性、稳定性、单调性的检验。 第四部分,多因子组合的构建、回测、权重优化。多因子组合的构建, 涉及行业、市值的中性化处理;多重共线性检验;因子权重优化;以及多因子策略的历史绩效回测。
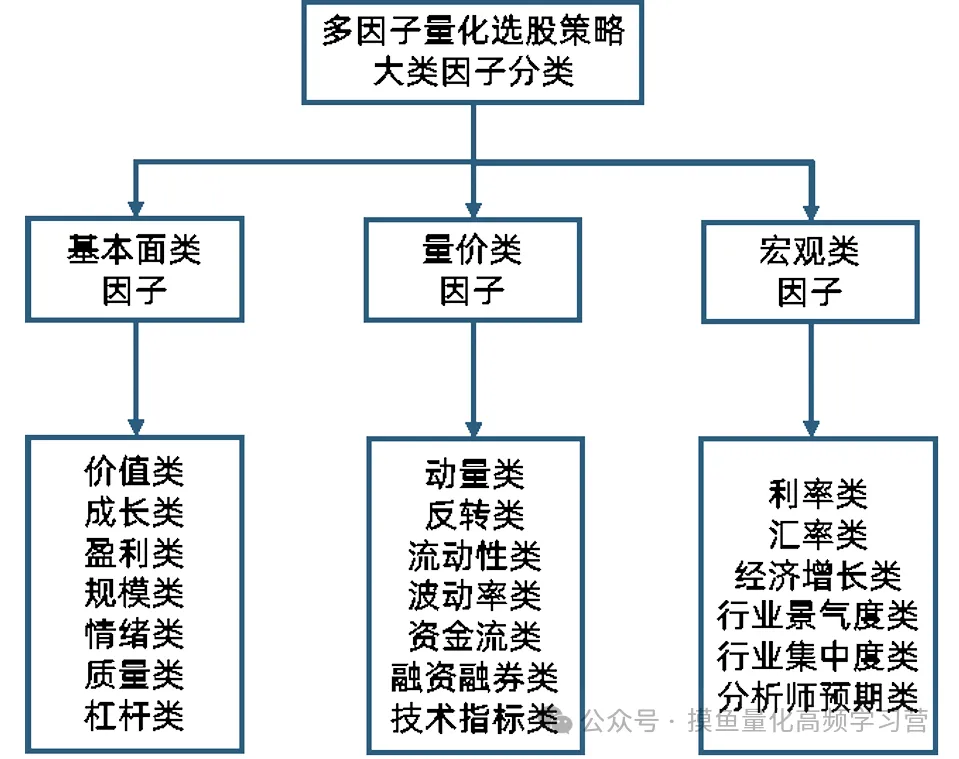
从大类上可划分为三大类,基本面类、量价类、宏观类因子。
基本面类因子包括价值类,成长类,盈利类,规模类,情绪类,质量类,杠杆类因子。量价类因子包括动量类,反转类,流动性类,波动率类,资金流类,融资融券类,技术指标类。宏观类因子包括利率类,汇率类,经济增长类,行业景气度类,行业集中度类,分析师预期类。
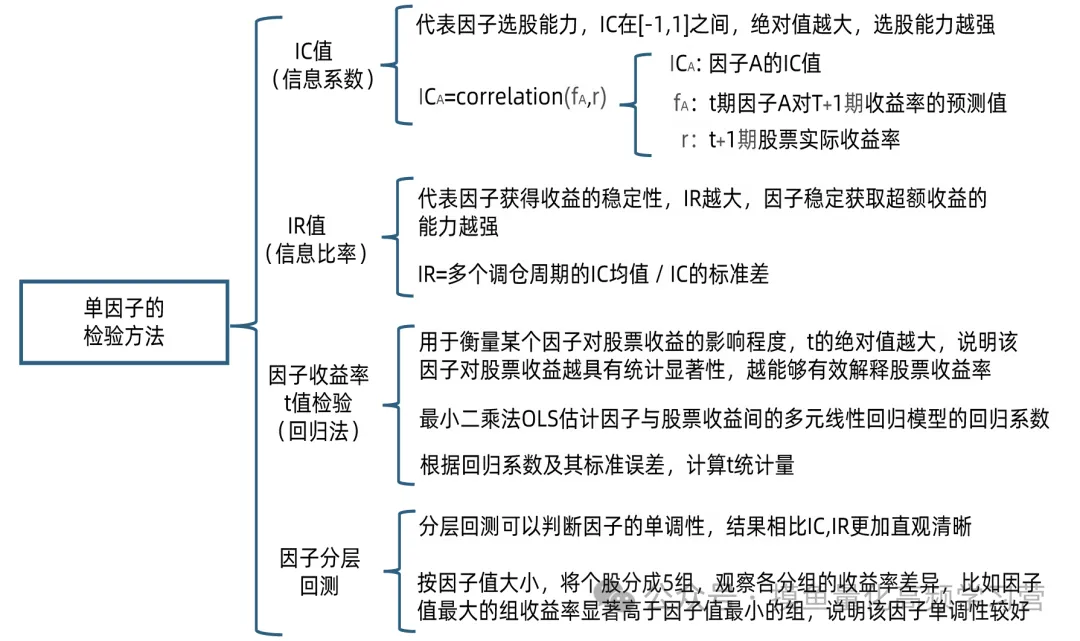
与低频因子相比,高频数据在用于量化投资中存在一定优势。首先,高频价量数据的体量明显大于低频数据。以分钟行情为例,用压缩效果 较好的mat格式存储2020年全市场股票的分钟行情数据(包括分钟频的开高低收价格数据、买卖盘挂单数据等),约为12GB。如果是快照行情(目前上交所和深交所都是3秒一笔)或者level 2行情,数据量要大很多。因此,高频数据因子挖掘对 信息处理能力和处理效率的要求较高。而且,日内数据,尤其是level 2数据,一般 要额外付费,甚至需要自行下载存储实时行情,在此基础上构建的因子拥挤度较低。 其次,高频价量数据一般是多维的时间序列数据,数据中噪声比例较高,而且 与ROE、PE这类低频指标本身就具有选股能力不同的是,原始的高频行情数据一般不能直接用作选股因子,而要通过信号变换、时间序列分析、机器学习等方法从 高频数据中构建特征,才能作为选股因子。此类因子与低频信号的相关性较低,而且由于因子开发流程相对复杂,不同投资者构建的因子更具有多样性。此外,高频数据开发的因子一般调仓周期较短,意味着在检验因子有效性的时候,同一段测试期具有更多的独立样本。例如,在一年的测试期内,只有12个独立 的样本段用于检验月频调仓的因子,与之相比,有约50个独立的时段用于检验周频调仓因子,有超过240个独立的时段用于检验日频调仓的因子。独立样本的增多有助于检验高频因子的有效性。高频数据挖掘因子的难点在于数据维度大、噪声高。凭借专业投资者的经验或者是参阅已发表的文献,可以从高频数据中提炼出一部分有选股能力的特征。此外,机器学习方法擅长从数据中寻找规律和特征,是高频数据因子挖掘的有力工 具。本期借鉴机器学习领域特征工程的思路,从高频价量数据中提炼选股因子。在机器学习领域,“正确”的特征应该适合当前的任务,并易于被模型使用。合理的特征设计可以使得后续模型建立更容易,提升模型的预测能力。特征工程就是在给定数据、模型和任务的情况下设计出最合适的特征的过程。特征设计主要是指对原始数据进行加工、特征组合,生成有一定意义的新变量 (新特征)。以健康管理为例,通过观察者的身高、体重、或者两者的线性加权,并不能直接判断其是否肥胖,而通过适当的变量组合之后形成的BMI指数(体重除以 身高的平方)则是一个非常简明的指标,可以直接用BMI指数的大小判断观察者是否肥胖。 领域知识可以显著提升特征的挖掘效率。在多因子选股体系中,不同的选股因 子即是结合金融市场特点构建的特征。盈利、成长、价值、质量、动量、流动性等 因子都是投资者通过经济学逻辑和金融市场的特点构建的选股因子。基于上述因子 筛选的股票组合有望跑赢市场。随着我们将研究对象从低频数据转向高频数据,数据的维度变得更高、信息密度变得更低、噪声含量变得更高。此时,专家的金融领域知识相对匮乏,而机器学习等方法擅长处理海量数据和高维特征,在这种情景下更能体现其优势。遗传规划是一种启发式搜索算法,在选股因子构建时,一般以因子收益率或者因子IC为优化目标,通过不断迭代进化因子计算表达式,获取预测能力强的因子。机器学习特征生成是在机器学习方法对数据进行建模的同时,产生新特征。可以产生新特征的机器学习模型包括主成分分析、梯度提升树和深度学习等。包括IC和IR值的检测,因子收益 率t值检验(回归法),因子分层回测法。计算IC(信息系数)和IR值(信息比率)方法:当IC值绝对值越大, 说明因子的选股能力越强,即因子暴露值与股票的未来收益率相关性越高。当IR 值越大,代表因子稳定地获取超额收益的能力越强(针对稳定性)。因子收益率t值检验:该方法为回归法,t的绝对值越大,说明该因子 对股票收益越具有统计显著性,越能够有效解释股票收益率。因子分层回测法:该方法相比IC,IR值更加直观清晰。按因子值大小,将个股分成5组,观察各分组的收益率差异,比如因子值最大的组收益率 显著高于因子值最小的组,说明该因子单调性较好。本节主要是对多个单因子进行单因子测试分析,所筛选的因子均属于行业内比较受欢迎的因子,因子种类结合了量价类因子,也包括基本面类、情绪类等因子。单因子回测按调仓周期为1天,5天,20天三种情况测试,分层回测各分位数因子组的平均收益率和累积收益率。回测周期为 2022 年12月至2024年12月两年。回测股票样本池为中证1000指数成分股。
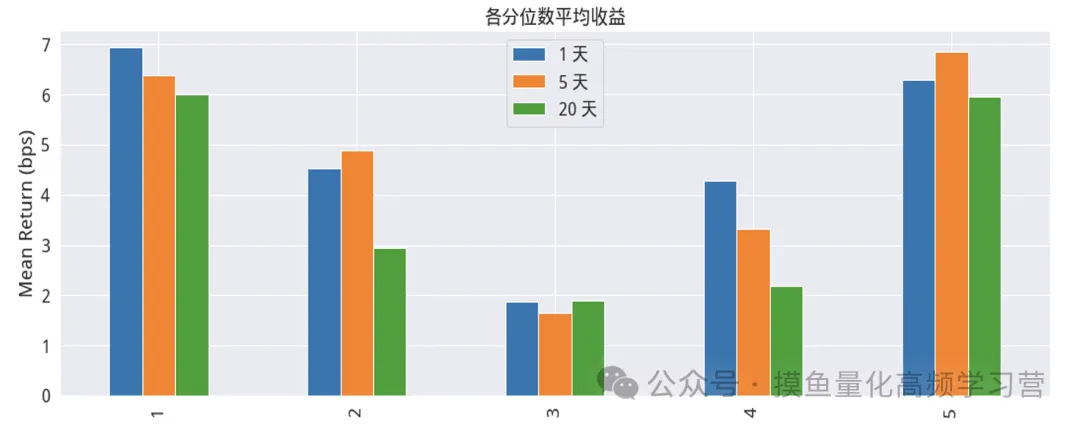
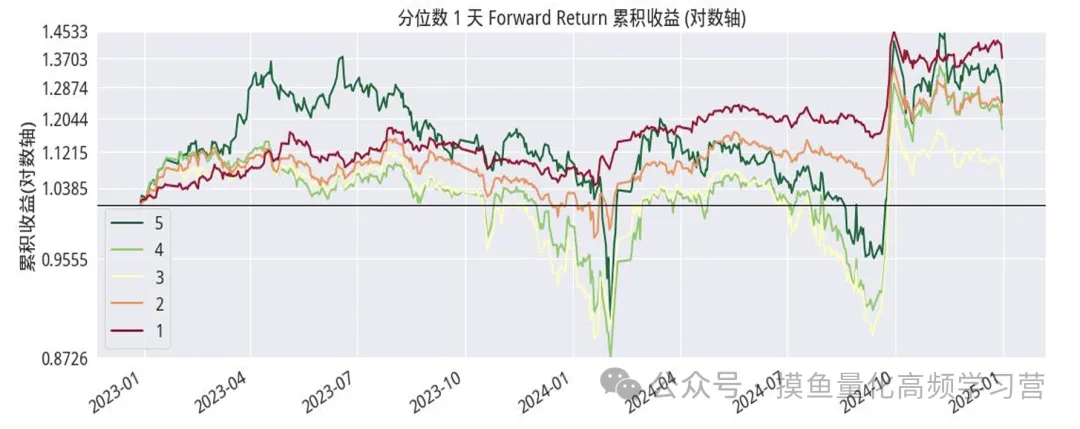
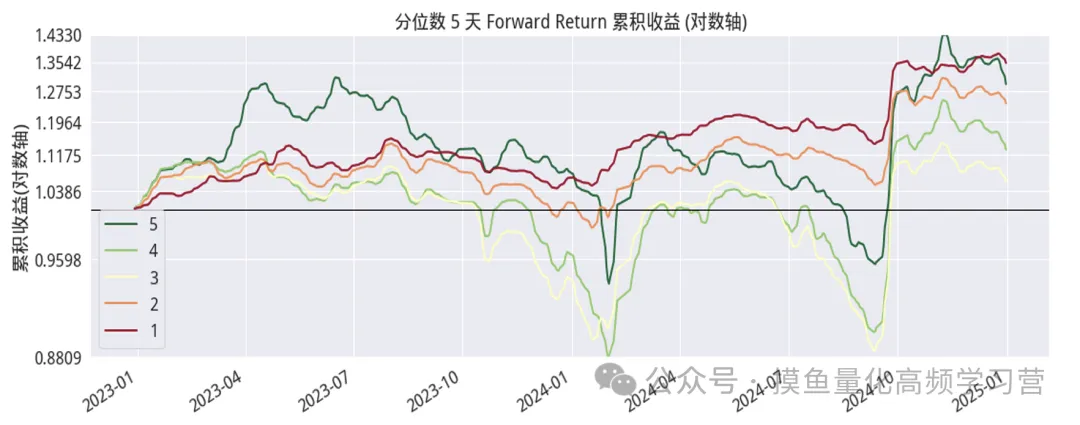
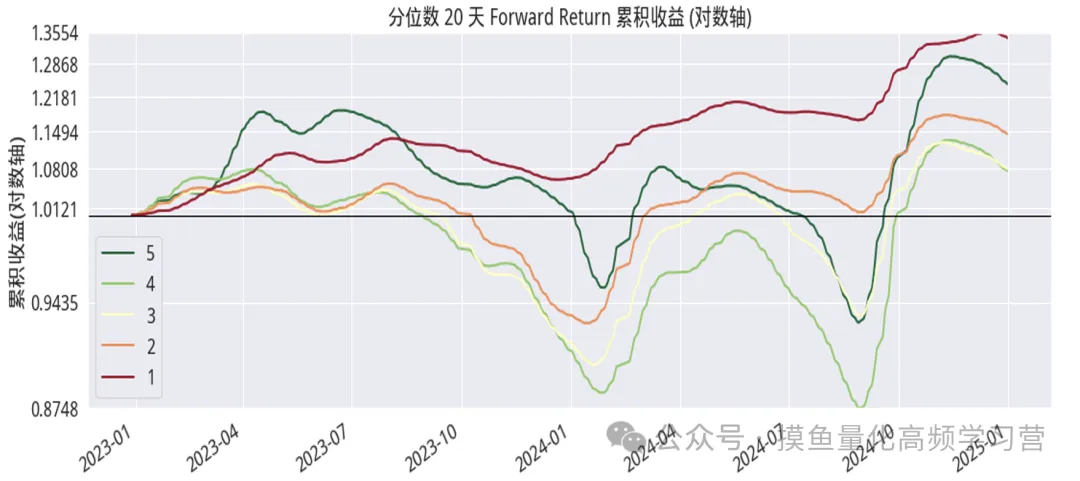
以下是具体的各单因子的分析、测试及其结果的展示: 一、改进型换手率高频因子,下图显示的是该因子在分层回测下,不同分位数组(分层)的股票组合的平均收益。
调仓周期为1天,5天,20天下,因子分组的累 积收益率。红色曲线为因子第1组即最小分位数组的收益率曲线,绿色曲 线为因子第5组即最大分位数组的收益率曲线。可以看到,过去2年,因 子的最小分位数组收益显著高于最大分位数组的收益,该因子显示出一定 的负单调性特征。 按调仓日期1天、5天、20天计算,IC均值分别为-0.048、-0.06、 0.082;IR 分别为-0.2、-0.264、-0.361。
import pandas as pdimport numpy as npimport yfinance as yffrom sklearn.ensemble import RandomForestClassifierfrom sklearn.preprocessing import StandardScalerfrom sklearn.pipeline import Pipelinefrom sklearn.model_selection import TimeSeriesSplitfrom backtrader import Cerebro, feeds, Strategy# ========== 数据准备 ==========def fetch_multi_freq_data(ticker, start_date, end_date): # 获取多频率数据 daily = yf.download(ticker, start=start_date, end=end_date, interval='1d') weekly = yf.download(ticker, start=start_date, end=end_date, interval='1wk') monthly = yf.download(ticker, start=start_date, end=end_date, interval='1mo') # 重采样对齐数据 weekly_resampled = weekly.resample('D').ffill() monthly_resampled = monthly.resample('D').ffill() # 合并多频率数据 merged = pd.concat([ daily.add_prefix('D_'), weekly_resampled.add_prefix('W_'), monthly_resampled.add_prefix('M_') ], axis=1).ffill().dropna() return merged# ========== 多频率因子计算 ==========def calculate_factors(df): # 日频因子 df['D_RSI'] = compute_rsi(df['D_Close'], 14) df['D_MA5'] = df['D_Close'].rolling(5).mean() # 周频因子 df['W_Momentum'] = df['W_Close'].pct_change(4) # 4周动量 # 月频因子 df['M_MA3'] = df['M_Close'].rolling(3).mean() df['M_Volatility'] = df['M_Close'].rolling(6).std() # 6个月波动率 # 跨频率交互因子 df['D_W_Spread'] = df['D_MA5'] / df['W_MA5'] - 1 df['W_M_Spread'] = df['W_MA5'] / df['M_MA3'] -1 return df.dropna()def compute_rsi(series, window): delta = series.diff() gain = delta.where(delta > 0, 0) loss = -delta.where(delta < 0, 0) avg_gain = gain.rolling(window).mean() avg_loss = loss.rolling(window).mean() rs = avg_gain / avg_loss return 100 - (100 / (1 + rs))# ========== 特征工程 ==========def create_features_target(df, forward_days=5): # 未来收益率作为标签 df['Target'] = df['D_Close'].pct_change(forward_days).shift(-forward_days) df['Target'] = (df['Target'] > 0).astype(int) # 滞后特征处理 features = df.columns.drop('Target') for lag in [1, 3, 5]: for f in features: df[f'{f}_lag{lag}'] = df[f].shift(lag) return df.dropna()# ========== 模型训练 ==========def train_model(X, y): pipeline = Pipeline([ ('scaler', StandardScaler()), ('clf', RandomForestClassifier(n_estimators=100, max_depth=5, class_weight='balanced')) ]) tscv = TimeSeriesSplit(n_splits=5) scores = [] for train_idx, test_idx in tscv.split(X): X_train, X_test = X.iloc
 想要学习更多,可以关注我们,下一期会持续更新,扫描我,带走优秀策略!
想要学习更多,可以关注我们,下一期会持续更新,扫描我,带走优秀策略!关注我,跑赢95%
重温经典(点击标题即可观看):
金牌策略:ETF轮动策略的优化(二)
金牌策略:大A牌‘电风扇’策略的超额与躺赢之路(一)
金牌策略:浅谈‘小狮子’策略的超额来源和优化之路(一)
高频控:CTA高频入门(三)