字数 4336,阅读大约需 22 分钟
背景
令人惊讶的是,在AI技术日益成熟的今天,大多数医疗机构仍然依赖于传统技术。传真机、寻呼机和电话仍然被大量使用。
许多外部实验室结果(病理学、放射学、基因检测等)仍然通过传真到达,而不是通过 API 传输。像 eFax 这样的服务可以接收这些传真并将其传送到电子邮件收件箱或文件共享中,然后由工作人员手动审核并将它们路由到电子健康记录(EHR)系统中的正确患者记录。
我们最近一直在研究一个自动化工作流管道的概念验证,用于处理这些传真并将数据提取为结构化格式。输出可以存储在数据库中,并与一个用户界面应用程序配对,让诊所工作人员可以监控和查看传入的结果。
本文涵盖了我们在从 PDF 提取信息方面学到的内容,并将该概念验证描述为迈向更完全自动化的医疗文档摄取系统的一个潜在基石。这包括与智能体助手的集成。
挑战
第一个令人惊讶的发现是,意识到从电子文档中提取信息仍然不是一个已经解决的问题。OCR 已经存在了很长时间,所以我认为我可以找到一个足够好的解决方案,然而我发现我错了。
在几次快速尝试从医疗结果文档中提取数据后,我了解到它们不可以基于当前的PDF以编程方式直接提取文本。虽然它们以PDF形式到达,但每个文件本质上是一个扫描页面嵌入图像的包装器,因此直接文本提取不起作用。我以为没问题,就使用 OCR 来提取信息。
概念验证的第一次迭代使用 OCR 提取文本,然后将其转换为结构化数据。这在技术上可行,但准确度不够好。它错过了数据元素,文本顺序混乱,产生了太多的字符识别错误,无法可靠使用。
解决方案
突破来自于一个意想不到的转变:完全移除 OCR。
不再使用 OCR,我们切换到具有视觉能力的大语言模型,它可以解释每一页并将其转换为 Markdown。这保留了布局和格式,包括表格,作为数据提取之前的中间步骤。
移除 OCR 并添加 Markdown 转换步骤显著提高了提取准确性。权衡的是,如果您出于数据隐私而在本地运行,会有更高的计算要求;如果您在云端运行,则成本更高。对于像医疗文档处理这样以准确性优先的工作流程来说,这是一个可以接受的妥协。
在接下来的部分中,我将分享我学到的关于 PDF 和从中提取数据的知识,以及我们构建的概念验证系统的概述。
PDF 文档基础
文档处理系统需要处理的三种基本类型的 PDF:纯文本 PDF(所有内容可以直接提取)、混合 PDF(信息包含在文本和图像的混合中)、以及 纯图像 PDF(所有内容都包含在图像中)。下图显示了这些类型及其提取特征:
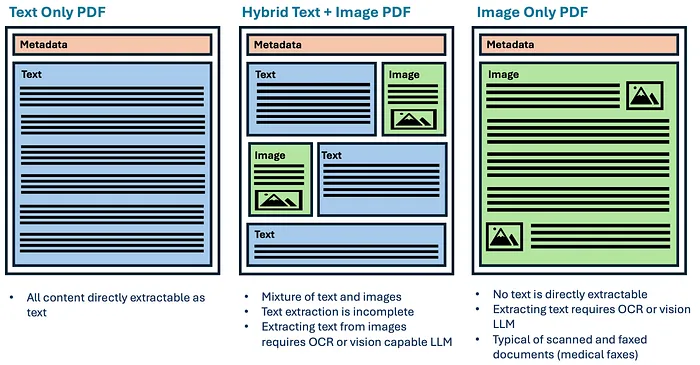
文档处理系统将遇到的 PDF 基本类型
下表显示了不同文本提取方法以及每种 PDF 类型和提取方法的特征:
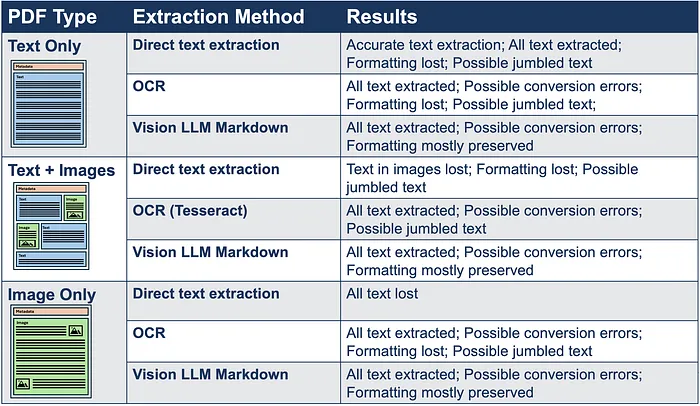
每种 PDF 文档类型的提取方法和结果
直接文本提取
对于简单的纯文本 PDF,提取内容是直接了当的,出错的机会很小,因为文本是直接复制的。缺点是这种方法只适用于纯文本 PDF,格式如布局和表格会丢失。结果,输出可能变成一团文本,当存在列或表格时,内容可能会被错误排序。下面的示例展示了使用 Python 的 PyPDF 包进行直接文本提取:

使用 Doc2MD 将 PDF 转换为 Markdown 的示例(视觉大语言模型转换)
使用这种方法从 PDF 提取文本的完整代码可以在下面找到(我假设您正在使用 " uv" 作为您的 Python 环境):
"""从 PDF 中提取文本并打印到标准输出。用法: uv run example_basic_text_extraction.py <pdf_file_path>依赖项: - pypdf(安装方式:uv pip install pypdf)"""import sysfrom pathlib import Pathimport pypdfdef main(): if len(sys.argv) < 2: print("Usage: uv run example_basic_text_extraction.py <pdf_file_path>") sys.exit(1) pdf_path = Path(sys.argv[1]) # 打开并读取 PDF with open(pdf_path, 'rb') as file: pdf_reader = pypdf.PdfReader(file) # 从每一页提取文本 for page in pdf_reader.pages: text = page.extract_text() print(text)if __name__ == "__main__": main()
OCR 提取
我们将研究的下一个方法是光学字符识别(OCR)。对于混合 PDF(文本和图像的混合)和纯图像 PDF,OCR 可以用来提取文本内容。这种方法与直接文本提取有一些相同的限制。格式如布局和表格会丢失,文本可能会被错误排序,但 OCR 还会引入字符识别错误,尤其是当图像或扫描质量较低时。在这个示例中,我们将使用 Tesseract 和 pdf2image Python 包。
注意: 除了 Python 包之外,这还需要在您的操作系统中安装 " tesseract" 和 " poppler" 实用程序:
- • MacOS:"brew install tesseract poppler"
- • Linux (Ubuntu):"sudo apt-get install tesseract-ocr poppler-utils"
- • Windows:Tesseract:从 UB Mannheim 下载;Poppler:从 GitHub 下载

使用直接文本 extraction从 PDF 提取文本的示例
使用这种方法从 PDF 提取文本的完整代码可以在下面找到:
"""使用 OCR 从 PDF 中提取文本并打印到标准输出。用法: uv run example_ocr_extraction.py <pdf_file_path>依赖项: - pytesseract(安装方式:uv pip install pytesseract) - pdf2image(安装方式:uv pip install pdf2image)系统要求: - Tesseract OCR: "brew install tesseract" (macOS), "sudo apt-get install tesseract-ocr" (Ubuntu) - poppler-utils: "brew install poppler" (macOS), "sudo apt-get install poppler-utils" (Ubuntu)"""import sysfrom pathlib import Pathimport pytesseractfrom pdf2image import convert_from_pathdef main(): if len(sys.argv) < 2: print("Usage: uv run example_ocr_extraction.py <pdf_file_path>") sys.exit(1) pdf_path = Path(sys.argv[1]) # 将 PDF 转换为图像 images = convert_from_path(pdf_path, dpi=300) # 对每一页执行 OCR for image in images: text = pytesseract.image_to_string(image) print(text)if __name__ == "__main__": main()
视觉大语言模型 Markdown 转换和提取
正如我在本文档前面的"挑战"和"解决方案"部分所记,我需要处理的许多文件都是低质量扫描,OCR 的准确度不够高。它产生了太多的识别错误和太多的乱序文本,无法可靠地提取所需数据。我估计我只能正确提取大约 80% 的所需数据。
我曾在几个过去的项目中与大语言模型驱动的管道合作过,包括一个使用具有视觉能力(多模态)大语言模型的图像分类管道( LLaVA)。我决定尝试当时可用的最好的开源视觉模型。经过一些快速测试,它比 OCR 慢得多,但准确度显著提高。
下一个重大突破是在结构化数据提取之前添加了 Markdown 转换步骤。下面是使用我在此项目中创建的独立 Doc2MD 实用程序进行 PDF 到 Markdown 过程的示例。对于医疗结果文档最重要的是,它保留了表格,这使得提取相关数据变得更加容易。
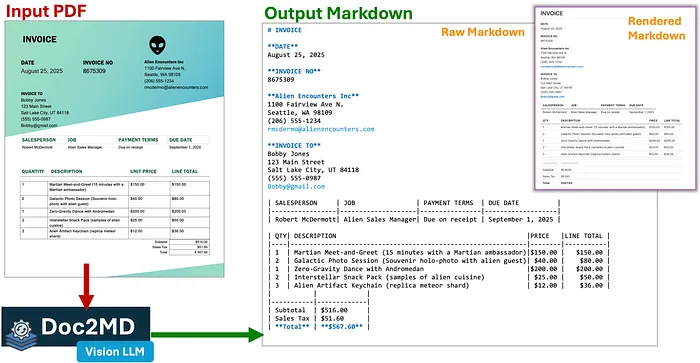
使用 Doc2MD 将 PDF 转换为 Markdown 的示例(视觉大语言模型转换)
PDF图像转换到 Markdown 的实用程序,可以在这里找到: https://github.com/robert-mcdermott/doc2md
将 OCR 与这种视觉大语言模型转 Markdown 方法进行比较
OCR 与低质量扫描、复杂文档
示例 1: 使用 OCR 有很多字符识别错误,一些扫描伪影(如页面边缘)被错误地检测为字符。仍然可能从这个文本中提取一些数据,但错误太多,无法信任。

低质量复杂文档示例 1 的 OCR 文本提取
示例 2: 这个文档更加复杂,输出中有太多的错误和乱序的文本,无法使用:
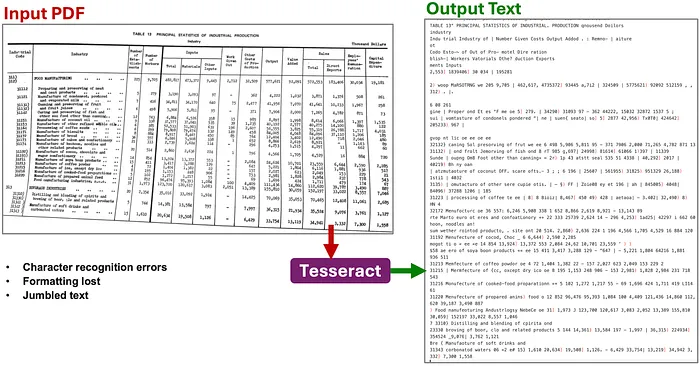
低质量复杂文档示例 2 的 OCR 文本提取
视觉大语言模型与 Markdown 转换 vs 低质量扫描、复杂文档
示例 1: 与这个文档的 OCR 版本相比,它的转换做得非常好。我们必须注意的一点是大语言模型可能会超越提取,可能会添加一些内容来填补空白或试图"帮助"。在这个例子中,它添加了下面指示的有用信息,这些信息在原始文档中并不存在:

低质量复杂文档示例 1 的视觉大语言模型提取和 Markdown 转换
示例 2: 这个文档被选为更糟糕情况的例子。表格中没有水平线,一些行是嵌套的,而且它是扭曲的。虽然输出不完美,但它在尝试用 Markdown 重建它方面做得令人印象深刻。幸运的是,我需要处理的医疗结果文档没有这么混乱:
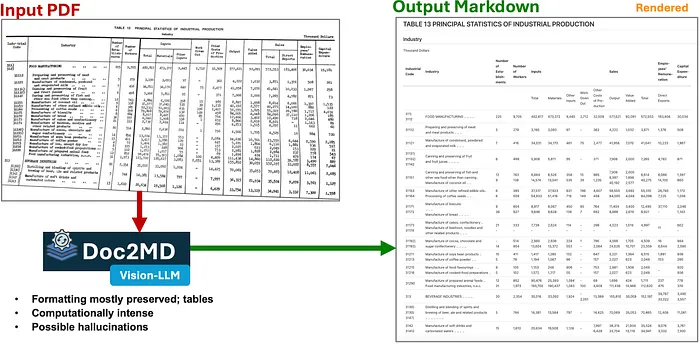
低质量复杂文档示例 2 的视觉大语言模型提取和 Markdown 转换
很明显,即使是运行在本地的小型开源模型,视觉大语言模型在准确提取扫描文档信息方面也远比 OCR 优越。
文档到 Markdown 转换工具
因为我之前有构建大语言模型驱动的数据管道和使用具有视觉能力的大语言模型的经验,我在花时间查看已经存在的东西之前就开始构建自己的解决方案。
在这一部分中,我将分享 Doc2MD 和我后来发现的另外两个系统的信息:DeepSeek-OCR 和 Docling。
Doc2MD
Doc2MD 是一个独立的实用程序,以下是它作为视觉大语言模型驱动的文档到 Markdown 方法的公共示例:

Doc2MD 信息(点击图像放大)
DeepSeek-OCR
DeepSeek-OCR 名称中的"OCR"有点名不副实。它不像 Tesseract 那样使用传统的 OCR 方法。相反,它使用具有令人印象深刻提取能力的具有视觉能力的大语言模型:
DeepSeek OCR 信息(点击图像放大)
DeepSeek-OCR 可以根据系统提示有不同的输出类型。它可以输出:
- • 原始文档的图像,在每个检测/提取的文本块上覆盖彩色编码的边界框
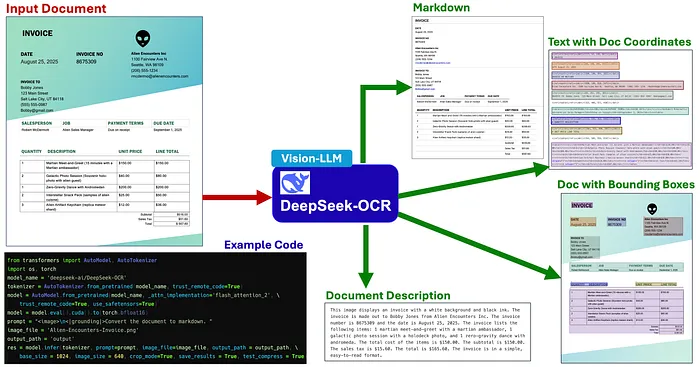
带有代码及其输出的 DeepSeek-OCR 示例(点击图像放大)
这是 DeepSeek-OCR 可以产生的独特边界框叠加和坐标输出的特写:
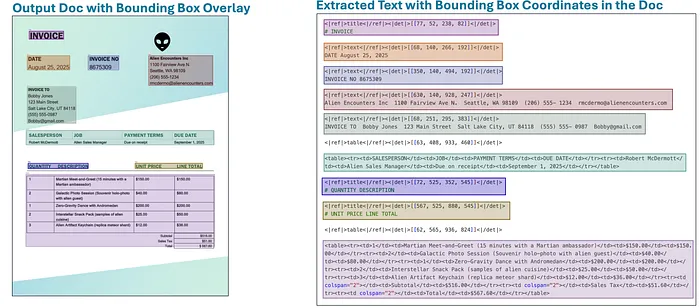
DeepSeek-OCR 边界框叠加和坐标输出(点击图像放大)
Docling
Docling 是另一个强大的文档文本提取实用程序,具有广泛的功能和选项。我能够获得与使用 DeepSeek-OCR 相似的输出。使用 Docling,我能够生成以下输出格式:
DeepSeek-OCR 主要是一个模型,而 Docling 是一个功能齐全的实用程序,具有广泛的功能。如果我早点知道 Docling,我可能就不会创建 Doc2MD,而是可能会将 Docling 用作我们医疗结果管道概念验证的一部分:
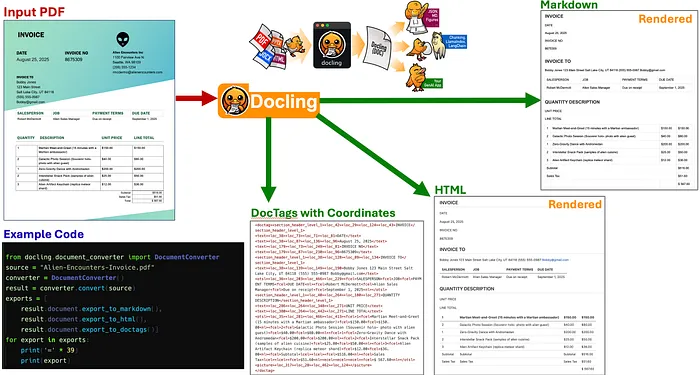
带有代码及其输出的 Docling 示例(点击图像放大)
医疗结果传真文档处理概念验证
我开始走上这条路并学会了本文第一部分中涵盖的所有内容的原因,是要构建一个外部医疗结果传真处理管道,我将在本文的其余部分介绍这个管道。如前所述,这个管道最初使用 OCR 从传入的传真中提取信息,但准确度不够。
注意: 下面示例中显示的所有患者信息(PHI)都是虚假的,本文不包含敏感信息。
高级概念
下图显示了视觉大语言模型驱动管道的高级概念。简而言之,文档被转换为一堆图像(每页一个图像)。然后这些图像被传递给具有视觉能力的大语言模型,它将文档转换为 Markdown。然后 Markdown 被输入到一个带有特定任务提取指令的纯文本大语言模型中,返回一个存储在数据库中的 JSON 文档:
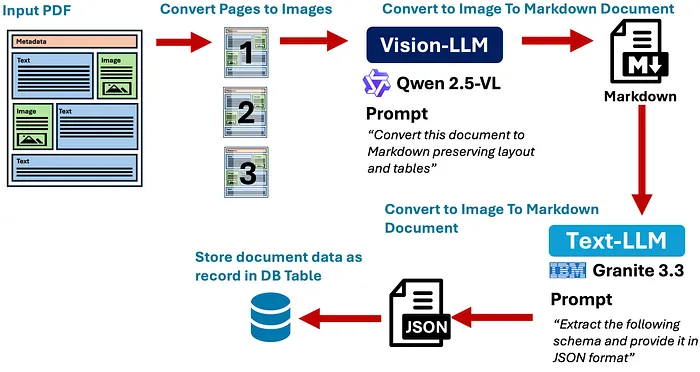
文档处理管道的高级概念
数据模式
在与主题专家合作定义了应该从外部医疗结果文档中捕获哪些数据之后,我们为管道的数据提取阶段创建了以下模式:
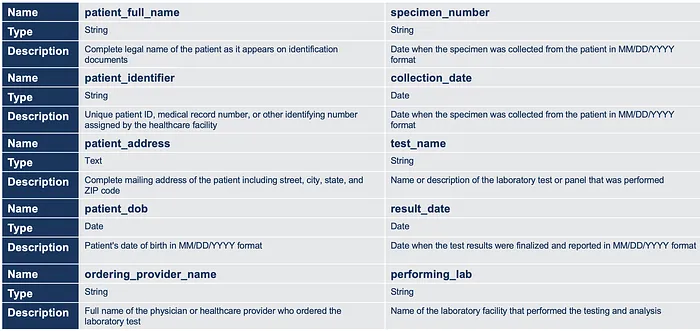
用于医疗结果管道的数据模式
外部医疗结果处理系统概念验证的 diagram
下面是为处理外部医疗结果文档而构建的概念验证系统的高级 diagram。该系统的直接文本提取和 OCR 提取功能首先实现,如果需要仍然可以使用,但视觉大语言模型提取被配置为默认方法:
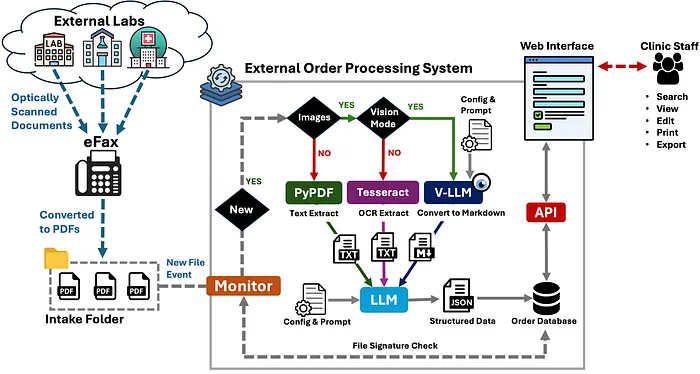
概念验证文档处理系统的高级架构 diagram
管理和监控界面
概念验证系统包括一个基本的管理用户界面,可用于监控指标、健康状况和配置,以及启动、停止或手动触发文档摄入目录扫描的控件:
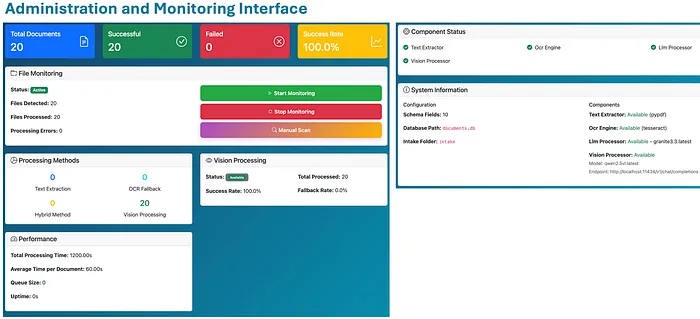
文档处理系统管理面板(点击图像放大)
搜索界面和结果
系统包括一个搜索界面,用户可以在整个文档文本中执行全文搜索,或搜索特定字段。匹配的记录显示在表格中:
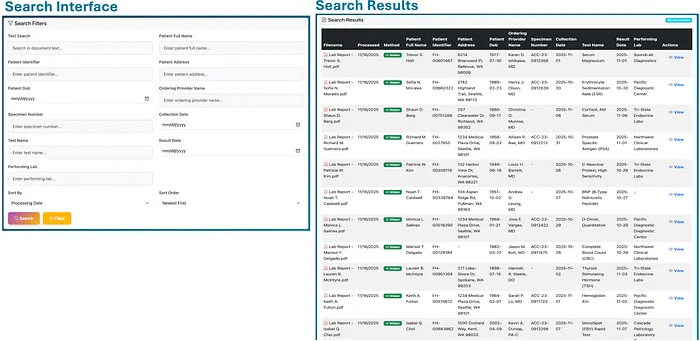
搜索和文档结果界面(点击图像放大)
文档详情、审查、编辑、导出和查看
当用户点击搜索结果中记录的"查看"操作时,他们会被带到文档详情页面。在那里,他们可以审查提取的数据,如果需要可以进行编辑,导出数据,并查看文档:
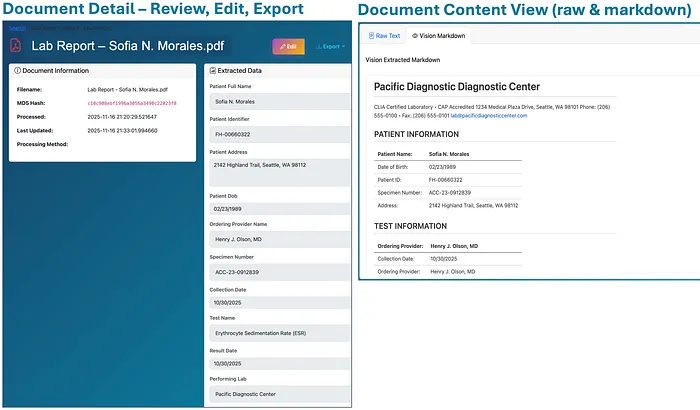
文档详情、审查和导出界面(点击图像放大)
API
系统公开了一个可用于监控、控制、搜索和检索文档的 API。这个 API 还支持与其他系统的集成:

带有示例的医疗结果文档处理系统 API(点击图像放大)
医疗结果智能体助手
使用上面显示的 API,我们构建了一个智能体助手,允许用户询问关于文档、患者特定结果或系统可以回答的任何其他问题。智能体助手使用 API 检索相关信息并回复用户。
MCP(模型上下文协议)服务器也可以使用相同的 API,为智能体提供一个干净的接口来访问文档系统。下图显示了 IOERD 助手如何与文档系统交互。
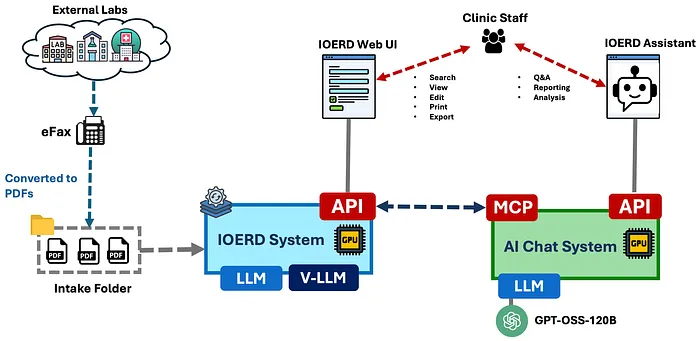
显示智能体助手如何与医疗结果文档系统交互的 diagram
为了保持开源和开放权重,我们使用了 OpenAI 的开放权重模型 GPT-OSS-120B 作为智能体助手。这允许整个系统在本地运行,防止敏感数据离开园区网络。
智能体助手示例
- • 左边的示例(下图)显示了智能体告诉用户它是什么、它的目的是什么以及如何帮助他们
- • 右边的示例(下图)显示了助手获取和显示系统收到的最后 5 条记录:
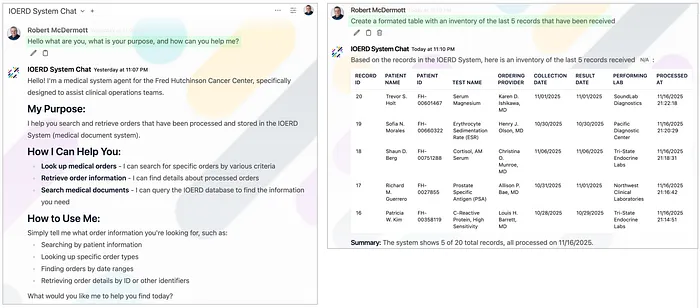
智能体助手与医疗结果文档系统的交互(点击图像放大)
- • 左边的示例(下图)显示了助手根据标本/样本编号查找结果文档
- • 右边的示例(下图)显示了助手查找特定患者的结果:
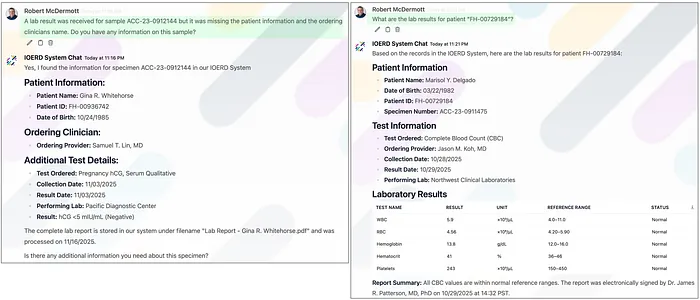
智能体助手与医疗结果文档系统的交互(点击图像放大)
结论
OCR 对于某些用例仍然有用,但对于从复杂文档中提取信息,尤其是质量不理想的扫描文档,它的性能远不如新的基于视觉大语言模型的方法。在实践中,大语言模型也比一堆提取的乱序单词更可靠地处理 Markdown,因此在运行任何提取步骤之前将文档转换为 Markdown 可能会改变游戏规则。
与 OCR 相比,视觉大语言模型方法的主要缺点是成本和性能。它在本地 GPU 上运行时计算更密集,通常更慢;而在租用的 GPU 上运行时(例如 AWS EC2),或按令牌的使用量计费时(例如 OpenAI、Anthropic 或 AWS Bedrock),成本可能会更高。

