技术背景
作为一名交易员,你是不是在盈利的时候经常感觉自己是市场的驾驭者,能够准确预测市场走势,巴菲特也不过如此!在亏损的时候,总是觉得账户被监控,一买就被砸盘一卖就卖飞。
其实,这是一个普遍的现象,主要原因出在了人工对未来价格的预测存在随机性、不稳定性、不准确性、无逻辑性。比如:今天涨了,很多人就预测继续涨,接着就是追高。跌了,觉得明天会继续悲观走势就卖了。造就了追涨杀跌的现象。
无逻辑性 很多人对未来的判断,仅仅基于有限的经验、小道消息,大部分是用脚投票,毫无依据、逻辑可言。
不准确性 基于90%的散户亏钱的理论,显然大部分人判断不够准确。具体胜率多少,无法考证。
随机性 很多人判断没有依据,完全是凭借自己的感觉走、映像中可能会涨,这就导致了同一段行情,早上可能就看涨、下午睡了一觉感觉不好就看跌了。
不稳定 随机性的判断,自然没法得到稳定的结果。就好比押大押小,运气好可能连续获胜、运气不好也可能连续亏损。
无法追溯 这也是显然易见的,人工根本给不了你,他以前判断的到底怎么样?有几成的把握,任何环节都无法准确的给出判断。
总体来讲,一个交易员所有的操作都是基于他个人对未来价格走势预测。显然,交易的结果好与坏,跟预测的准确性有着必然的联系。
我们认为投资其实就是一门概率学,首先,我们要认识没有人能够百分百胜利,至于一段时间是连续胜利,要认清楚到底是幸存者偏差,还是能力所致。其次,我们要充分的了解,自己对未来的判断正确的概率是多少?空间有多少?最大亏损可能是多少?需要配置多少的仓位?总的来说,就是需要知道未来走势的概率分布是怎么样的?对应不同的概率分布,制定不同的交易策略。
那么,如何估计股票的未来收益分布就成了本期的主要内容。 我觉得本文方法是其次,主要的是需要转变一些交易的理念。
本文参考了:《Financial Wind Tunnel: A Retrieval-Augmented Market Simulator》,结合了自己的想法与建议。需要原文的可以私我,代码后期星球放出。 论文提出了一个创新评估维度:市场排名。
市场排名的做法是,把合成序列与目标股票真实未来的相关性,放入“市场上所有其他真实股票与该真实未来的相关性”分布中排名,观察合成序列能超越多少比例的真实股票。通俗的讲:我预测出的合成序列20天,与该股票真实未来20天收益序列的相关性,超过了N%的其他股票未来收益与该股票未来收益的相关性,那么,N%就是市场排名的数值。
举例而言,若市场排名达到 99%,说明合成序列在捕捉目标股票未来走势上优于市场上 99%的真实股票。
原文解析
做了什么事?
在量化策略的优化与训练中,我们发现目前获取大规模、高质量的实时金融数据存在规模有限、隐私问题和成本障碍。因此,市场模拟器应运而生,旨在通过学习资产特征生成具有统计真实性的模拟数据。当然,当前市场模拟器面临诸多限制:
频率差异:不同数据频率(周、日、分钟)的模式和波动不同,现有模型通常只针对特定频率,缺乏跨尺度建模能力。
跨市场交互: 市场动态日益受外部资本和其他市场影响,但缺乏模仿跨市场运动交互的模拟器。
极端条件: 需要一个具备因果生成能力的模拟器,基于预定义的风险假设生成可控的市场波动。
为了解决上述限制,文中提出了金融风洞(FWT),FWT旨在为下游金融模型构建一个高度可靠和多样化的模拟环境。它使用扩散模型并检索横截面信息来增强金融时间序列的生成。
运用场景
1.策略的压力测试与参数优化: 显然某一个品种来讲,历史数据是不够的,如果我能够预测未来的走势分布。就知道策略在未来的收益分布。
2.持仓的收益分析: 这很明显的优势,如果你的策略开仓了,我就能得到收益分布。比如:最大收益、最大亏损。可以作为止盈止损的判断标准。
3. 直接作为截面因子: 收益序列的平均收益率作为截面因子,构造多因子策略。(下一期文章)
与传统预测的区别
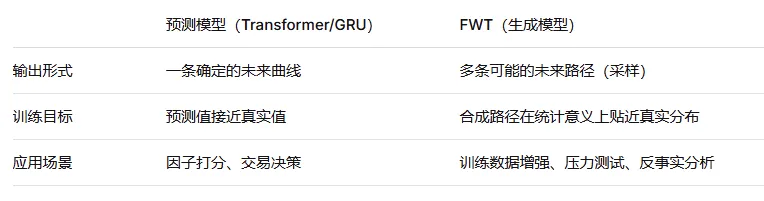 FWT本质上是一个生成模型,而非端到端预测模型。其合成结果不直接参与交易决策,而是作为下游量化模型的训练样本与压力测试素材。
FWT本质上是一个生成模型,而非端到端预测模型。其合成结果不直接参与交易决策,而是作为下游量化模型的训练样本与压力测试素材。
算法理论
本节详细阐述FWT的方法和结构,FWT由三个模块依次串联构成:
检索模块 → 生成模块 → 应用模块
检索模块:以目标股票过去250天收益序列为查询,在全市场中检索K=16只走势最相似的股票。
生成模块:基于条件去噪扩散概率模型(条件DDPM),以检索到的相似股票完整序列为条件,合成目标股票未来20天的收益路径。
应用模块:自动策略优化器,将合成数据用于下游模型的训练增强与压力测试。
1. 检索
为了增强生成序列与目标序列的可信度,我们执行检索增强以构建可靠的横截面上下文信号。
- 定义目标股票 的收益率序列:历史部分 (时间区间)和未来生成目标 (时间区间 )。
- 使用相似性度量(皮尔逊相关系数),检索在历史区间 内与 最相似的 Top-K 只股票。设这些股票为 。
- 连接这些股票的历史和未来数据,形成多变量时间序列观测值 。
- 定义一个观测掩码 ,用于过滤掉目标股票 的未来部分(即 置为0,其余为1)。我们的目标就是合成 以逼近真实值。
- 强调:检索过程可运行在所有频率上(多频率生成)。此外,我们还可以应用检索过滤规则来控制生成(如跨市场生成、假设生成)。
2. 生成 —— 条件扩散模型
我们利用条件扩散模型生成目标股票的未来价格轨迹。
- 基础DDPM:经典去噪扩散概率模型包含前向加噪过程(逐步加入高斯噪声)和逆向去噪过程(神经网络学习预测噪声 )。训练损失为预测噪声的均方误差(MSE)。
- 条件扩散扩展:我们定义了条件去噪函数 ,它接收条件观测 作为输入。
- 给定样本 ,将其分离为条件观测(包括检索到的相似股票的全部序列 + 目标股票的历史部分)和目标变量(目标股票的未来轨迹,被掩码遮盖)。
- 这类似于掩码语言建模(MLM)的自监督训练机制。模型主干网络使用 Transformer。
算法1(训练) 简要流程:
算法2(生成/推理) 简要流程:
- 对于 从 到 1,利用条件 和模型预测均值,逐步去噪,最终得到生成的未来轨迹 。
3. 自动策略优化器
为了展示实用性,介绍了一个基于FWT的策略优化器,在两种模式下运行,这部分是应用的一部分,可以做自己成:
- 基于模型的优化:使用模拟数据自动进行超参数调整、特征工程、模型架构搜索和集成,提高泛化能力。
- 基于规则的优化:根据预定义的组合指标(如收益率、回撤、夏普比率)系统评估,淘汰在极端市场条件下表现不佳的配置。
具体实现步骤
主要分为三步。
第一步:数据准备,准备条件信息。取目标股票在 的历史段,并检索对应的 16 只相似股票及其完整 270 天序列,二者共同构成条件输入。
第二步,初始化目标段 在目标股票 至 的位置上放置一段纯随机高斯噪声,作为待生成区域的初始值。
第三步,迭代去噪 1、将纯随机噪声与条件信息一起输入 Transformer 去噪网络,模型输出“本步应当去除的噪声” , 得到含噪噪声的序列;2、该序列再次与条件信息一起输入去噪网络,再去掉一部分噪声。如此循环 100 次,最终得到的就是目标股票 至 的一条合成收益路径。
由于起点是随机噪声,同样的输入多次运行会得到不同的合成路径,这正是 FWT 作为生成模型而非预测模型的核心体现:每次部署产出的都只是众多可能未来中的一条候选路径,而不是对未来收益的单一确定性估计。
代码与实现
由于篇幅原因,代码仅展示部分,代码借助了Claude code。
1.检索模块
# models/retrieval/dtw_retrieval.py
"""
代码用途:DTW相似度检索核心功能
创建日期:2026-06-17
修改日期:2026-06-17
修改目的:实现DTW检索核心,为生成模块提供相似股票作为条件信息
实现方法:
1. 使用dtaidistance库计算DTW距离(支持窗口约束加速)
2. 实现Top-K检索,返回K个最相似的股票序列
3. 严格时间截断,避免未来函数
4. 支持滑动窗口匹配,寻找历史中的相似片段
关键参数:
- K: 检索返回的相似股票数量
- L: 目标序列长度(观察窗口)
- T: 预测窗口长度(用于时间截断)
"""
import numpy as np
import pandas as pd
from typing import Dict, List, Tuple, Optional
from dtaidistance import dtw
from ...utils.logger import get_logger
logger = get_logger(__name__)
classDTWRetrieval:
"""
DTW相似度检索器
用于在候选股票池中检索与目标序列最相似的K个股票序列。
核心功能:
1. 计算DTW距离
2. Top-K检索
3. 时间安全保证(严格截断未来数据)
"""
def__init__(
self,
K: int = 5,
L: int = 20,
T: int = 5,
window: Optional[int] = None
):
"""
初始化DTW检索器
参数:
K: 检索返回的相似股票数量
L: 目标序列长度(观察窗口,单位:天)
T: 预测窗口长度(用于时间截断,单位:天)
window: DTW窗口约束参数,用于加速计算。
None表示不限制,建议设置为L//2以加速
"""
self.K = K
self.L = L
self.T = T
self.window = window if window isnotNoneelse L // 2
logger.info(f"初始化DTW检索器: K={K}, L={L}, T={T}, window={self.window}")
defcompute_dtw_distance(
self,
seq1: np.ndarray,
seq2: np.ndarray
) -> float:
"""
计算两个序列之间的DTW距离
参数:
seq1: 序列1,形状 (length1,)
seq2: 序列2,形状 (length2,)
返回:
distance: DTW距离(归一化后的值)
"""
# 输入验证
if len(seq1) == 0or len(seq2) == 0:
logger.warning("输入序列为空,返回无穷大距离")
return float('inf')
# 类型转换:确保输入为float类型(dtaidistance要求)
seq1 = np.asarray(seq1, dtype=np.float64)
seq2 = np.asarray(seq2, dtype=np.float64)
# 使用dtaidistance计算DTW距离
# window参数限制对齐路径的搜索范围,加速计算
try:
distance = dtw.distance(
seq1,
seq2,
window=self.window,
use_c=True# 使用C加速版本
)
# 归一化:除以序列长度,使不同长度序列可比
normalized_distance = distance / max(len(seq1), len(seq2))
return normalized_distance
except Exception as e:
logger.error(f"DTW距离计算失败: {e}")
return float('inf')
defretrieve_similar_stocks(
self,
target_returns: np.ndarray,
candidates: Dict[str, Tuple[np.ndarray, pd.Timestamp]],
current_date: pd.Timestamp,
k: Optional[int] = None
) -> List[Tuple[str, float, pd.Timestamp]]:
"""
检索与目标股票最相似的K只股票
参数:
target_returns: 目标股票历史收益 (L,)
candidates: 候选股票池 {stock_id: (returns_sequence, data_date)}
- returns_sequence: 收益率序列
- data_date: 该序列的**结束日期**(序列最后一天的日期)
用于时间安全验证,必须 < current_date
current_date: 当前时间点(时间截断)
k: 检索数量(默认使用self.K)
返回:
results: [(stock_id, dtw_distance, matched_date), ...]
- matched_date: 候选序列的结束日期(即data_date)
⚠️ 未来函数防范:
- candidates中的data_date必须 < current_date
- 候选序列长度必须 >= L,否则跳过
- 返回的matched_date必须 < current_date
注意:
- 当前实现只使用候选序列的前L天进行匹配(简化版)
- 完整版应该实现滑动窗口寻找最佳匹配位置
"""
if k isNone:
k = self.K
logger.info(f"开始检索相似股票: target_length={len(target_returns)}, "
f"candidates={len(candidates)}, k={k}")
# 输入验证
if len(target_returns) != self.L:
logger.warning(f"目标序列长度{len(target_returns)}与配置L={self.L}不一致")
# 计算与所有候选股票的DTW距离
distances = []
for stock_id, (candidate_seq, data_date) in candidates.items():
# ⚠️ 时间安全性检查:候选数据必须早于current_date
if data_date >= current_date:
logger.warning(
f"跳过 {stock_id}:data_date={data_date} >= current_date={current_date}"
)
continue
# ⚠️ 长度验证:候选序列必须足够长
if len(candidate_seq) < self.L:
logger.debug(
f"跳过 {stock_id}:序列长度{len(candidate_seq)} < L={self.L}"
)
continue
try:
# 只使用候选股票的历史部分(前L天)进行匹配
# 注意:这是简化实现,完整版应该滑动窗口寻找最佳匹配位置
candidate_hist = candidate_seq[:self.L]
# 计算DTW距离
distance = self.compute_dtw_distance(target_returns, candidate_hist)
# matched_date就是候选序列的data_date
matched_date = data_date
distances.append((stock_id, distance, matched_date))
except Exception as e:
logger.warning(f"计算 {stock_id} 的DTW距离失败: {e}")
continue
# 按距离排序,取Top-K
distances.sort(key=lambda x: x[1])
top_k = distances[:k]
logger.info(
f"检索完成:从{len(candidates)}只候选股票中选出Top-{k},"
f"平均距离={np.mean([d[1] for d in top_k]):.4f}"if top_k else
f"检索完成:从{len(candidates)}只候选股票中选出0只(无有效候选)"
)
return top_k
defbatch_retrieve(
self,
target_stocks: Dict[str, np.ndarray],
candidate_pool: Dict[str, Tuple[np.ndarray, pd.Timestamp]],
current_date: pd.Timestamp,
k: Optional[int] = None
) -> Dict[str, List[Tuple[str, float, pd.Timestamp]]]:
"""
批量检索多个目标股票的相似股票
参数:
target_stocks: 目标股票池,dict {stock_id: returns_array}
candidate_pool: 候选股票池,dict {stock_id: (returns_sequence, data_date)}
current_date: 当前日期
k: 每个目标股票返回的相似股票数量
返回:
batch_results: dict {target_stock_id: [(stock_id, distance, matched_date), ...]}
"""
logger.info(f"批量检索: {len(target_stocks)}个目标股票")
batch_results = {}
for target_id, target_returns in target_stocks.items():
# 确保不会检索到自己
filtered_pool = {
sid: data for sid, data in candidate_pool.items()
if sid != target_id
}
results = self.retrieve_similar_stocks(
target_returns,
filtered_pool,
current_date,
k=k
)
batch_results[target_id] = results
logger.info(f"批量检索完成")
return batch_results
2. 生成模块实现
2.1 扩散模型基础
前向加噪过程:
给定原始数据 ,逐步加入高斯噪声:
其中 是预定义的噪声调度(通常从 线性增加到 )。
可直接采样:
其中 ,。
反向去噪过程:
从纯噪声 出发,逐步去噪:
2.2 条件扩散模型
FWT的核心创新在于将检索信息作为条件:
训练目标:
其中:
- :条件信息(目标股票历史段 + 相似股票完整序列)
2.3 Transformer骨干网络
import torch
import torch.nn as nn
classDiffusionTransformer(nn.Module):
def__init__(
self,
input_dim: int = 1, # 收益率序列维度
seq_len: int = 270, # 序列长度
n_stocks: int = 17, # K+1
d_model: int = 128,
n_layers: int = 4,
n_heads: int = 8,
diff_steps: int = 100
):
super().__init__()
self.diff_steps = diff_steps
# 输入嵌入: 将(17, 270)展平或使用2D位置编码
self.input_proj = nn.Linear(input_dim, d_model)
# 时间步嵌入
self.time_embed = nn.Sequential(
nn.Linear(d_model, d_model * 4),
nn.SiLU(),
nn.Linear(d_model * 4, d_model)
)
# Transformer编码器
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model,
nhead=n_heads,
dim_feedforward=d_model * 4,
dropout=0.1,
activation='gelu'
)
self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=n_layers)
# 输出投影: 预测噪声
self.output_proj = nn.Linear(d_model, input_dim)
defforward(
self,
x_noisy: torch.Tensor, # 加噪目标段 (batch, n_stocks, seq_len)
cond: torch.Tensor, # 条件信息 (batch, n_stocks, seq_len)
t: torch.Tensor # 扩散步数 (batch,)
) -> torch.Tensor:
"""
预测被加入的噪声
"""
# 组合输入: 条件信息 + 加噪目标段
# 注意: 条件信息中目标段位置为0,加噪目标段填充目标位置
combined = cond + x_noisy # 或使用concat
# 时间步嵌入
t_embed = self.time_embed(self._timestep_embedding(t))
# Transformer处理
# ... 具体实现细节
# 输出预测噪声
return self.output_proj(hidden)
def_timestep_embedding(self, t: torch.Tensor) -> torch.Tensor:
# Sinusoidal位置编码
pass
2.4 训练流程(Algorithm 1)
deftrain_fwt(
data: np.ndarray, # shape: (N_stocks, total_days)
train_indices: range,
L: int = 250,
T: int = 20,
K: int = 16,
H: int = 100, # 扩散步数
batch_size: int = 64,
epochs: int = 500
):
model = DiffusionTransformer()
optimizer = torch.optim.Adam(model.parameters(), lr=1.5e-4)
for epoch in range(epochs):
# 从训练集中随机采样时点t
t = np.random.choice(train_indices[L: -T])
target_stock = np.random.choice(N_stocks)
# 1. 检索相似股票
target_hist = data[target_stock, t-L:t]
similar_ids = retrieve_similar_stocks(target_hist, data[:, t-L:t], K)
# 2. 构造观测矩阵和掩码
X, M = build_observation_matrix(target_stock, similar_ids, t, L, T, data)
# X: (17, 270), M: (17, 270)
# 3. 分离条件和目标
x_cond = X * M # 已知条件
x_target = X * (1 - M) # 待生成目标 (只有目标股票未来20天非零)
# 4. 随机采样扩散步数
h = np.random.randint(1, H+1)
alpha_bar = get_alpha_bar(h) # 预计算
noise = np.random.normal(0, 1, x_target.shape)
# 5. 加噪
x_noisy = np.sqrt(alpha_bar) * x_target + np.sqrt(1 - alpha_bar) * noise
# 6. 模型预测噪声
noise_pred = model(x_noisy, x_cond, h)
# 7. 计算损失
loss = F.mse_loss(noise_pred, noise)
loss.backward()
optimizer.step()
2.5 生成流程
defgenerate_fwt(
model: DiffusionTransformer,
target_stock: int,
similar_ids: List[int],
t: int,
L: int = 250,
T: int = 20,
H: int = 100,
n_samples: int = 10# 生成多条路径
) -> np.ndarray:
"""
生成目标股票未来20天的多条合成路径
"""
# 1. 构造条件
X, M = build_observation_matrix(target_stock, similar_ids, t, L, T, data)
x_cond = X * M
# 2. 初始化: 从纯噪声开始
x_target = np.random.normal(0, 1, (n_samples, T))
# 3. 迭代去噪
for h in range(H, 0, -1):
# 组装完整矩阵
x_noisy_full = x_cond.copy()
x_noisy_full[0, L:L+T] = x_target # 填入当前噪声版本
# 模型预测噪声
noise_pred = model(x_noisy_full, x_cond, h)
# 更新 (DDPM采样公式)
alpha = get_alpha(h)
alpha_bar = get_alpha_bar(h)
beta = 1 - alpha
x_target = (1 / np.sqrt(alpha)) * (
x_target - (beta / np.sqrt(1 - alpha_bar)) * noise_pred
)
if h > 1:
x_target += np.sqrt(beta) * np.random.normal(0, 1, x_target.shape)
return x_target # shape: (n_samples, T)
3 评估模块实现
相关性计算:
defcompute_correlation(generated: np.ndarray, real: np.ndarray) -> float:
"""计算合成序列与真实序列的Pearson相关系数"""
return np.corrcoef(generated.flatten(), real.flatten())[0, 1]
市场排名:
defcompute_market_ranking(
generated: np.ndarray, # shape: (T,)
real_target: np.ndarray, # shape: (T,)
all_stock_future: np.ndarray # shape: (N_stocks, T)
) -> float:
"""
计算合成序列在横截面上的市场排名
"""
# 合成序列与真实目标的相关性
target_corr = np.corrcoef(generated, real_target)[0, 1]
# 所有其他真实股票与真实目标的相关性
other_corrs = []
for i in range(all_stock_future.shape[0]):
other_corrs.append(np.corrcoef(all_stock_future[i], real_target)[0, 1])
# 排名
all_corrs = other_corrs + [target_corr]
rank = sum(1for c in all_corrs if c <= target_corr) / len(all_corrs)
return rank
实证结果
以沪深300作为股票池,2010-2018作为训练集、2019-2020作为验证集、2021-2026作为测试集。
1. 日频、小时频上表现最佳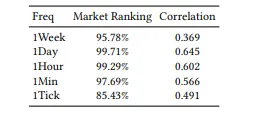 合成序列与真实收益序列的相关性分别:日频0.645、小时频率0.602.市场排名为99.72%与99.29%
合成序列与真实收益序列的相关性分别:日频0.645、小时频率0.602.市场排名为99.72%与99.29%
2.跨市场,有效性原文测试了在港中寻找相似股票的作为沪深300的数据,这里结果不展示,需要可看原文。
3.对其他独立量化模型的增强效果
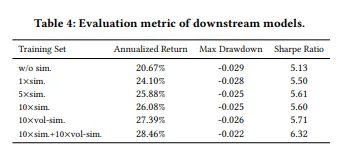
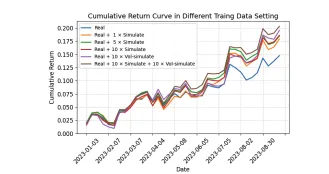 显然对量化的择时模型似乎有些提升,但是我们还没有做验证。
显然对量化的择时模型似乎有些提升,但是我们还没有做验证。
总结
总的来讲,本文介绍了一种生成未来收益序列的通用方法,与传统的时序估计模型不同,本文采用的了类似于大模型中检索增强(RAG)的思路,对预测进行了改进。整体效果可观。
正好我们目前也在做一些类似的研究,觉得整体的思路还是比较新颖跟独到的,值得大家一起研究。

